Bạn có thường xuyên làm việc với các tệp dữ liệu văn bản trên hệ thống Linux và cảm thấy cần một công cụ để sắp xếp chúng một cách nhanh chóng và hiệu quả không? Việc quản lý các tệp log, danh sách người dùng, hay bất kỳ dữ liệu dạng văn bản nào cũng có thể trở nên phức tạp nếu không được tổ chức đúng cách. Khi dữ liệu lộn xộn, việc tìm kiếm và phân tích thông tin trở nên tốn thời gian, dễ gây ra sai sót và làm giảm năng suất công việc của bạn. Đây chính là lúc lệnh sort trong Linux phát huy sức mạnh. Lệnh sort là một tiện ích dòng lệnh mạnh mẽ, được tích hợp sẵn trong hầu hết các bản phân phối Linux, giúp bạn sắp xếp các dòng trong tệp văn bản theo nhiều tiêu chí khác nhau một cách dễ dàng. Bài viết này sẽ hướng dẫn bạn từ những khái niệm cơ bản đến các kỹ thuật nâng cao, bao gồm cú pháp, các tùy chọn phổ biến, ví dụ thực tế và những mẹo hữu ích để bạn làm chủ công cụ này.
Cú pháp cơ bản của lệnh sort
Lệnh sort là một trong những công cụ không thể thiếu đối với bất kỳ ai làm việc thường xuyên trên môi trường dòng lệnh của Linux. Việc nắm vững cú pháp và cách thức hoạt động của nó sẽ giúp bạn xử lý dữ liệu văn bản hiệu quả hơn rất nhiều.
Định nghĩa và cú pháp tổng quan
Về cơ bản, lệnh sort được sử dụng để sắp xếp các dòng trong một hoặc nhiều tệp văn bản. Cú pháp chuẩn của lệnh này rất đơn giản và dễ nhớ, giúp người dùng mới có thể tiếp cận nhanh chóng.
Cú pháp tổng quát như sau:sort [tùy chọn] [tên_file]
Trong đó:
sort: Là lệnh để thực thi chương trình sắp xếp.[tùy chọn]: Là các tham số (cờ) bạn có thể thêm vào để thay đổi hành vi mặc định của lệnh. Ví dụ, bạn có thể yêu cầu sắp xếp theo số thay vì theo chữ cái, hoặc sắp xếp theo thứ tự giảm dần.[tên_file]: Là tên của tệp tin văn bản mà bạn muốn sắp xếp. Nếu bạn không cung cấp tên tệp, lệnhsortsẽ đọc dữ liệu từ đầu vào chuẩn (standard input), thường là dữ liệu được đưa vào từ bàn phím hoặc qua một pipe (|).
Nếu bạn cung cấp nhiều tệp tin, lệnh sort sẽ nối nội dung của chúng lại với nhau và sắp xếp tất cả các dòng như một khối dữ liệu duy nhất. Kết quả sau khi sắp xếp sẽ được hiển thị ra màn hình (đầu ra chuẩn – standard output).
Các tham số đầu vào phổ biến
Lệnh sort rất linh hoạt trong việc tiếp nhận dữ liệu đầu vào. Bạn có thể sử dụng nó với các tệp tin có sẵn hoặc kết hợp với các lệnh khác để xử lý dữ liệu một cách linh động.
Sử dụng tệp tin làm đầu vào:
Đây là cách sử dụng phổ biến nhất. Bạn chỉ cần cung cấp tên của tệp tin ngay sau lệnh sort và các tùy chọn (nếu có).
Ví dụ: sort danh_sach_ten.txt
Lệnh này sẽ đọc nội dung từ tệp danh_sach_ten.txt, sắp xếp các dòng theo thứ tự từ điển và in kết quả ra màn hình.
Sử dụng dữ liệu từ đầu vào dòng lệnh (pipe):
Một trong những sức mạnh lớn nhất của môi trường dòng lệnh Linux là khả năng kết hợp các lệnh lại với nhau bằng toán tử pipe (|). Toán tử này lấy đầu ra của lệnh bên trái và dùng nó làm đầu vào cho lệnh bên phải.
Ví dụ, bạn có thể liệt kê các tệp trong thư mục hiện tại và sau đó sắp xếp chúng theo tên:ls -l | sort
Trong trường hợp này, lệnh ls -l tạo ra một danh sách các tệp và thư mục, và danh sách này được “chuyển” trực tiếp cho lệnh sort để xử lý mà không cần phải lưu vào một tệp trung gian.
Sử dụng dấu ngoặc kép và phân tách trường:
Khi làm việc với dữ liệu có chứa khoảng trắng hoặc các ký tự đặc biệt, việc sử dụng dấu ngoặc kép " là rất quan trọng để đảm bảo dòng lệnh hiểu đúng ý của bạn. Mặc dù sort xử lý theo từng dòng, việc này trở nên quan trọng khi kết hợp với các lệnh khác. Hơn nữa, bạn có thể chỉ định ký tự phân tách các trường (cột) dữ liệu bằng tùy chọn -t, giúp sort hiểu được cấu trúc dữ liệu của bạn, chẳng hạn như trong các tệp CSV.
Các tùy chọn phổ biến để sắp xếp dữ liệu
Lệnh sort không chỉ đơn thuần sắp xếp theo thứ tự chữ cái. Nó cung cấp một loạt các tùy chọn mạnh mẽ cho phép bạn tùy chỉnh quá trình sắp xếp để phù hợp với hầu hết mọi loại dữ liệu, từ văn bản đơn giản đến các bảng dữ liệu phức tạp.

Sắp xếp theo chữ cái và theo số
Mặc định, sort sẽ sắp xếp dữ liệu theo thứ tự từ điển (lexicographical order), dựa trên giá trị ký tự trong bảng mã ASCII. Điều này hoạt động tốt với dữ liệu văn bản, nhưng có thể gây ra kết quả không mong muốn khi làm việc với số.
Tùy chọn mặc định (sắp xếp theo chữ cái):
Khi bạn chạy lệnh sort mà không có tùy chọn nào, nó sẽ so sánh từng dòng ký tự theo ký tự.
Ví dụ, nếu bạn có một tệp numbers.txt chứa:
10 2 1
Lệnh sort numbers.txt sẽ cho ra kết quả:
1 10 2
Lý do là vì sort so sánh ký tự ‘1’ trong “10” với ký tự ‘2’ và thấy rằng ‘1’ đứng trước.
Sắp xếp số với -n (numeric sort):
Để khắc phục vấn đề trên và sắp xếp dữ liệu dạng số một cách chính xác, bạn cần sử dụng tùy chọn -n. Tùy chọn này yêu cầu sort diễn giải các giá trị ở đầu dòng là số thay vì chuỗi ký tự.
Sử dụng cùng tệp numbers.txt, lệnh sort -n numbers.txt sẽ cho kết quả đúng như mong đợi:
1 2 10
Tùy chọn -n là một trong những tùy chọn được sử dụng thường xuyên nhất khi làm việc với dữ liệu số.
Sắp xếp đảo ngược và theo cột cụ thể
Ngoài việc sắp xếp theo thứ tự tăng dần, sort còn cho phép bạn đảo ngược kết quả và chỉ định sắp xếp dựa trên một cột dữ liệu cụ thể, rất hữu ích khi làm việc với các tệp có cấu trúc.
Tùy chọn -r (reverse): đảo ngược thứ tự sắp xếp
Tùy chọn -r hoạt động rất đơn giản: nó đảo ngược kết quả của việc sắp xếp. Thay vì từ A đến Z hoặc từ nhỏ đến lớn, nó sẽ sắp xếp từ Z về A hoặc từ lớn về nhỏ.
Ví dụ, để sắp xếp danh sách số theo thứ tự giảm dần:sort -n -r numbers.txt
Kết quả sẽ là:
10 2 1
Bạn có thể kết hợp -r với bất kỳ kiểu sắp xếp nào khác.
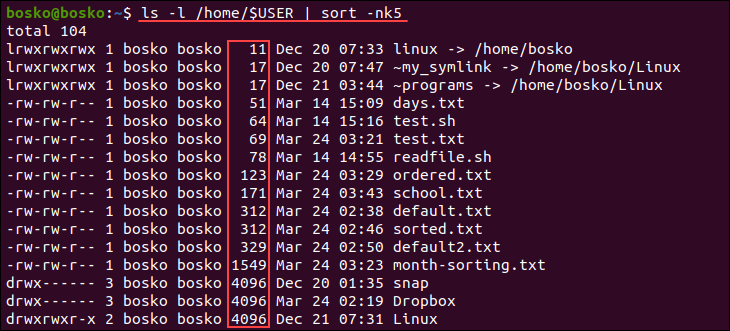
Tùy chọn -k (key): chọn cột dữ liệu để sắp xếp
Đây là một tùy chọn cực kỳ mạnh mẽ khi bạn làm việc với dữ liệu dạng bảng, chẳng hạn như các tệp CSV hoặc đầu ra từ các lệnh như ls -l. Tùy chọn -k cho phép bạn chỉ định cột (hay còn gọi là trường hoặc “key”) nào sẽ được dùng làm khóa để sắp xếp.
Cú pháp: -k [số_thứ_tự_cột]
Mặc định, sort coi khoảng trắng là dấu phân cách giữa các cột.
Ví dụ, bạn có một tệp grades.txt với nội dung:
An 8 Binh 9 Cuong 7
Để sắp xếp danh sách này theo điểm số (cột thứ hai), bạn dùng lệnh:sort -k 2 -n grades.txt
Kết quả:
Cuong 7 An 8 Binh 9
Ở đây, -k 2 chỉ định sắp xếp dựa trên cột thứ hai, và -n đảm bảo rằng việc so sánh được thực hiện theo kiểu số.
Tùy chọn -t (delimiter): định nghĩa dấu phân cách cột
Nếu dữ liệu của bạn không sử dụng khoảng trắng làm dấu phân cách (ví dụ: dùng dấu phẩy , hoặc dấu hai chấm :), bạn cần chỉ định rõ cho sort biết bằng cách sử dụng tùy chọn -t.
Ví dụ, với tệp data.csv:
sanphamA,100,50 sanphamB,50,200 sanphamC,200,150
Để sắp xếp theo số lượng tồn kho (cột thứ hai), bạn dùng lệnh:sort -t ',' -k 2 -n data.csv
Lệnh này báo cho sort rằng dấu phẩy là ký tự phân tách các cột, sau đó sắp xếp dựa trên giá trị số ở cột thứ hai.
Ví dụ minh họa sử dụng lệnh sort
Lý thuyết sẽ trở nên dễ hiểu hơn rất nhiều khi được áp dụng vào các ví dụ thực tế. Dưới đây là một số tình huống phổ biến mà bạn có thể sử dụng lệnh sort để xử lý dữ liệu một cách hiệu quả.

Sắp xếp dữ liệu trong file
Đây là trường hợp sử dụng cơ bản và phổ biến nhất của lệnh sort. Giả sử chúng ta có một tệp tin tên là nhanvien.txt chứa danh sách nhân viên và năm sinh của họ.
Nội dung tệp nhanvien.txt:
Minh 1990 Lan 1985 Tuan 1995 Hoa 1990 Anh 2001
Ví dụ 1: Sắp xếp theo tên (mặc định)
Để sắp xếp danh sách này theo tên (cột đầu tiên), bạn chỉ cần chạy lệnh:sort nhanvien.txt
Kết quả hiển thị trên màn hình sẽ là:
Anh 2001 Hoa 1990 Lan 1985 Minh 1990 Tuan 1995
Các dòng đã được sắp xếp theo thứ tự chữ cái của tên.
Ví dụ 2: Sắp xếp theo năm sinh (tăng dần)
Bây giờ, nếu bạn muốn sắp xếp danh sách này dựa trên năm sinh (cột thứ hai) để biết ai là người lớn tuổi nhất, bạn cần sử dụng tùy chọn -k để chỉ định cột và -n để sắp xếp theo kiểu số.
Lệnh sẽ là: sort -k 2 -n nhanvien.txt
Kết quả:
Lan 1985 Minh 1990 Hoa 1990 Tuan 1995 Anh 2001
Danh sách bây giờ đã được sắp xếp theo năm sinh tăng dần. Lưu ý rằng khi có hai người cùng năm sinh (Minh và Hoa), thứ tự của họ có thể không được đảm bảo. Để ổn định kết quả, bạn có thể thêm một khóa sắp xếp phụ, ví dụ: sort -k 2 -n -k 1 nhanvien.txt sẽ sắp xếp theo năm sinh, sau đó theo tên.

Sắp xếp dữ liệu đầu vào dòng lệnh (pipe)
Sức mạnh của sort được nhân lên gấp bội khi kết hợp với các lệnh khác thông qua cơ chế “pipe” (|). Điều này cho phép bạn xây dựng các chuỗi xử lý dữ liệu phức tạp ngay trên dòng lệnh.
Ví dụ 1: Sắp xếp các tệp trong thư mục theo kích thước
Lệnh ls -l hiển thị thông tin chi tiết về các tệp, trong đó cột thứ 5 là kích thước tệp (tính bằng byte). Để tìm các tệp có dung lượng lớn nhất, bạn có thể kết hợp ls -l với sort.
Lệnh: ls -l | sort -k 5 -n -r
Giải thích từng bước:
1. ls -l: Liệt kê các tệp và thư mục dưới dạng danh sách chi tiết.
2. |: Chuyển toàn bộ đầu ra của ls -l làm đầu vào cho lệnh sort.
3. sort -k 5 -n -r:
-k 5: Sắp xếp dựa trên cột thứ 5 (kích thước tệp).-n: Sắp xếp theo giá trị số.-r: Sắp xếp theo thứ tự giảm dần (từ lớn đến nhỏ).
Kết quả sẽ là một danh sách các tệp và thư mục được sắp xếp theo kích thước từ lớn nhất đến nhỏ nhất, giúp bạn dễ dàng xác định các tệp đang chiếm nhiều dung lượng.
Ví dụ 2: Đếm tần suất xuất hiện của các từ
Một ví dụ kinh điển khác là đếm số lần xuất hiện của mỗi từ trong một tệp văn bản. Chúng ta sẽ kết hợp cat, tr, sort, và uniq.
Giả sử có tệp vanban.txt. Lệnh sẽ là:cat vanban.txt | tr ' ' '\n' | sort | uniq -c | sort -n -r
Giải thích chuỗi lệnh:
1. cat vanban.txt: Đọc nội dung của tệp.
2. tr ' ' '\n': Thay thế tất cả các khoảng trắng bằng ký tự xuống dòng, để mỗi từ nằm trên một dòng riêng.
3. sort: Sắp xếp danh sách các từ theo thứ tự chữ cái. Điều này là cần thiết để lệnh uniq hoạt động đúng.
4. uniq -c: Đếm số lần xuất hiện của các dòng liền kề giống nhau và hiển thị số đếm trước mỗi dòng.
5. sort -n -r: Sắp xếp kết quả cuối cùng theo số đếm (cột đầu tiên) theo thứ tự giảm dần để xem các từ phổ biến nhất.
Những ví dụ này cho thấy sort không chỉ là một công cụ độc lập mà còn là một mắt xích quan trọng trong chuỗi các công cụ xử lý văn bản của Linux.
Các vấn đề thường gặp khi sử dụng lệnh sort
Mặc dù lệnh sort rất mạnh mẽ, người dùng mới (và đôi khi cả những người đã có kinh nghiệm) có thể gặp phải một số vấn đề khiến kết quả không như mong đợi. Hiểu rõ nguyên nhân và cách khắc phục sẽ giúp bạn sử dụng công cụ này hiệu quả hơn.
Dữ liệu không được sắp xếp đúng mong muốn do định dạng
Đây là vấn đề phổ biến nhất. Bạn chạy lệnh sort và kết quả trả về bị lộn xộn hoặc không tuân theo quy tắc bạn đã chỉ định. Nguyên nhân thường nằm ở chính dữ liệu đầu vào.
Nguyên nhân:
1. Kiểu dữ liệu không nhất quán: Bạn cố gắng sắp xếp một cột chứa cả số và chữ bằng tùy chọn -n. Lệnh sort có thể sẽ coi các dòng chứa chữ là có giá trị bằng 0, dẫn đến việc chúng bị đẩy lên đầu danh sách.
2. Khoảng trắng không đồng đều: Mặc định, sort coi một hoặc nhiều khoảng trắng liên tiếp là một dấu phân cách duy nhất. Tuy nhiên, nếu dữ liệu của bạn có các khoảng trắng ở đầu hoặc cuối dòng (leading/trailing spaces), nó có thể ảnh hưởng đến kết quả sắp xếp theo chữ cái.
3. Dấu phân cách không chuẩn: Dữ liệu của bạn có thể sử dụng dấu phẩy (,), dấu chấm phẩy (;), hoặc ký tự tab để phân tách các cột. Nếu bạn không chỉ định đúng dấu phân cách bằng tùy chọn -t, lệnh sort sẽ không thể xác định đúng các cột và việc sắp xếp với -k sẽ thất bại.
Cách khắc phục:
- Luôn kiểm tra dữ liệu trước: Sử dụng các lệnh như
head,tail, hoặccat -Ađể xem qua một vài dòng dữ liệu mẫu.cat -Arất hữu ích vì nó hiển thị các ký tự ẩn như tab (^I) và ký tự kết thúc dòng ($), giúp bạn xác định chính xác dấu phân cách. Tham khảo thêm bài viết Lệnh cd trong Linux để biết thêm về thao tác dòng lệnh và kiểm tra file hiệu quả. - Sử dụng
-tvà-kmột cách chính xác: Nếu dữ liệu của bạn được phân tách bằng dấu phẩy, hãy chắc chắn rằng bạn đã thêm-t ','vào lệnh. Khi chỉ định cột với-k, hãy đảm bảo bạn đã đếm đúng số thứ tự của cột bạn muốn sắp xếp. - Làm sạch dữ liệu trước khi sắp xếp: Đôi khi, cách tốt nhất là sử dụng các công cụ khác như Bash là gì hoặc Kernel là gì để chuẩn hóa dữ liệu (ví dụ: loại bỏ khoảng trắng thừa, chuyển đổi định dạng) trước khi đưa vào
sort.
Xử lý dữ liệu có dấu tiếng Việt và kí tự đặc biệt
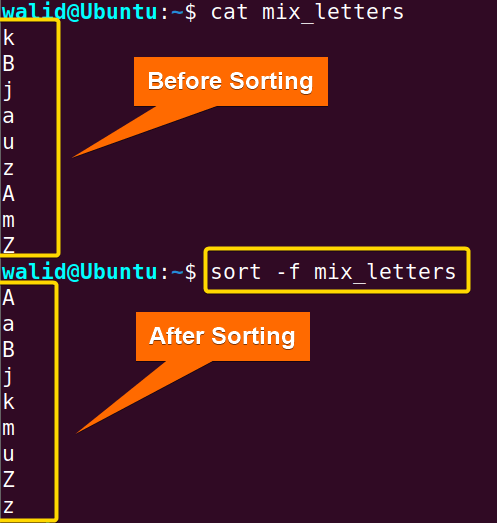
Khi làm việc với ngôn ngữ tự nhiên như tiếng Việt, bạn có thể gặp phải vấn đề với việc sắp xếp các ký tự có dấu. Thứ tự sắp xếp mặc định của sort phụ thuộc vào cài đặt ngôn ngữ (locale) của hệ thống.
Vấn đề về mã hóa và bộ lọc kí tự (Collation):
Trong nhiều hệ thống Linux được cấu hình mặc định với locale là en_US.UTF-8, thứ tự sắp xếp có thể không tuân theo quy tắc từ điển tiếng Việt. Ví dụ, chữ “đ” có thể bị xếp sau chữ “z”, hoặc các chữ “a”, “á”, “à” không được coi là tương đương khi sắp xếp. Điều này là do quy tắc sắp xếp (collation) của locale tiếng Anh không hiểu đúng về các ký tự tiếng Việt.
Giải pháp:
Cách giải quyết hiệu quả nhất là thiết lập biến môi trường LC_COLLATE hoặc LC_ALL sang locale tiếng Việt trước khi thực thi lệnh sort.
Bạn có thể chạy lệnh này trực tiếp trên terminal:export LC_COLLATE="vi_VN.UTF-8"
Hoặc bạn có thể đặt nó trước lệnh sort để chỉ áp dụng cho lệnh đó:LC_COLLATE="vi_VN.UTF-8" sort ten_file_tieng_viet.txt
Bằng cách này, bạn đang yêu cầu sort sử dụng quy tắc sắp xếp của tiếng Việt, giúp nó hiểu và sắp xếp các từ như “an”, “bình”, “đức” theo đúng thứ tự từ điển mà bạn mong muốn. Đảm bảo rằng hệ thống của bạn đã cài đặt locale vi_VN.UTF-8. Bạn có thể kiểm tra bằng lệnh locale -a. Nếu chưa có, bạn sẽ cần cài đặt nó thông qua các công cụ quản lý của hệ điều hành.
Mẹo và lưu ý khi sử dụng lệnh sort để tối ưu hiệu quả
Để thực sự làm chủ lệnh sort và biến nó thành một trợ thủ đắc lực, bạn nên ghi nhớ một vài mẹo và thực hành tốt nhất sau đây. Những lưu ý này không chỉ giúp bạn tránh được các lỗi phổ biến mà còn tối ưu hóa hiệu suất khi làm việc với các tập dữ liệu lớn.

- Luôn kiểm tra định dạng và phân tách trường dữ liệu trước khi sort
Nguyên tắc “rác vào, rác ra” (garbage in, garbage out) đặc biệt đúng vớisort. Trước khi thực hiện bất kỳ thao tác sắp xếp phức tạp nào, hãy dành một chút thời gian để kiểm tra cấu trúc của tệp dữ liệu. Sử dụng lệnhhead ten_fileđể xem vài dòng đầu tiên. Điều này giúp bạn xác định nhanh chóng ký tự phân tách các cột là gì (khoảng trắng, tab, dấu phẩy, v.v.) và liệu có khoảng trắng thừa hay các ký tự không mong muốn nào không. Việc này giúp bạn chọn đúng các tùy chọn-tvà-k, tiết kiệm thời gian gỡ lỗi sau này. - Kết hợp các tùy chọn để phù hợp với mục đích cụ thể
Đừng ngần ngại kết hợp nhiều tùy chọn lại với nhau để đạt được kết quả chính xác nhất. Ví dụ, để sắp xếp danh sách người dùng trong tệp/etc/passwdtheo User ID (cột thứ 3) theo thứ tự giảm dần, bạn có thể dùng:sort -t ':' -k 3 -n -r /etc/passwd
Ở đây, chúng ta đã kết hợp:-t ':': Chỉ định dấu hai chấm là ký tự phân tách.-k 3: Chọn cột thứ ba (UID) làm khóa sắp xếp.-n: Sắp xếp theo kiểu số.-r: Đảo ngược kết quả để có thứ tự giảm dần.
Việc kết hợp thông minh các tùy chọn là chìa khóa để giải quyết các bài toán dữ liệu phức tạp.
- Sử dụng pipeline để tăng tính linh hoạt và tích hợp với các lệnh khác
sorthiếm khi hoạt động một mình. Sức mạnh thực sự của nó được bộc lộ khi bạn kết hợp nó trong một chuỗi lệnh (pipeline). Một cặp bài trùng rất phổ biến làsort | uniq. Lệnhuniqdùng để loại bỏ hoặc đếm các dòng trùng lặp, nhưng nó yêu cầu dữ liệu đầu vào phải được sắp xếp trước. Ví dụ, để tìm các địa chỉ IP duy nhất đã truy cập vào máy chủ của bạn từ một tệp log và đếm số lần truy cập của mỗi IP:awk '{print $1}' access.log | sort | uniq -c | sort -nr
Chuỗi lệnh này lọc ra cột IP, sắp xếp chúng, đếm số lần xuất hiện, và cuối cùng sắp xếp lại theo số lần đếm để thấy IP nào truy cập nhiều nhất. Tìm hiểu thêm về Linux là gì để hiểu sâu hơn về hệ điều hành nơi bạn vận hành các lệnh này. - Tránh dùng sort trên file quá lớn mà không phân đoạn xử lý
Khi làm việc với các tệp tin có dung lượng lên tới hàng gigabyte hoặc terabyte, lệnhsortcó thể tiêu tốn rất nhiều bộ nhớ RAM và thời gian xử lý. Theo mặc định,sortsẽ cố gắng nạp càng nhiều dữ liệu vào bộ nhớ càng tốt để tăng tốc. Nếu tệp quá lớn so với RAM, nó sẽ sử dụng các tệp tạm trên đĩa, làm chậm đáng kể quá trình. Để xử lý các tệp lớn hiệu quả hơn, bạn có thể sử dụng tùy chọn--parallel=<số_luồng>để tận dụng nhiều lõi CPU. Ngoài ra, hãy xem xét việc sử dụng lệnhsplitđể chia tệp lớn thành nhiều tệp nhỏ hơn, sắp xếp từng tệp nhỏ, sau đó hợp nhất chúng lại bằng tùy chọn-m(merge) củasort. Tham khảo thêm các bản phân phối Linux Lite hoặc Mx Linux để có môi trường Linux tối ưu và nhẹ nhàng phù hợp với máy cấu hình thấp.
Kết luận
Qua bài viết này, chúng ta đã cùng nhau khám phá lệnh sort trong Linux, một công cụ tưởng chừng đơn giản nhưng lại vô cùng mạnh mẽ và linh hoạt. Từ cú pháp cơ bản, các tùy chọn phổ biến như -n (số), -r (đảo ngược), -k (theo cột), cho đến việc kết hợp với các lệnh khác qua pipeline, sort chứng tỏ vai trò không thể thiếu trong bộ công cụ của bất kỳ quản trị viên hệ thống hay nhà phát triển nào. Chúng ta cũng đã tìm hiểu các vấn đề thường gặp và cách khắc phục, đặc biệt là khi xử lý dữ liệu có định dạng phức tạp hoặc chứa ký tự tiếng Việt.
Những điểm quan trọng cần nhớ là: hãy luôn kiểm tra dữ liệu trước khi sắp xếp, lựa chọn và kết hợp các tùy chọn một cách thông minh, và tận dụng sức mạnh của pipeline để xây dựng các chuỗi xử lý hiệu quả. Đừng ngần ngại thực hành ngay bây giờ. Hãy thử tạo một tệp văn bản đơn giản, áp dụng các ví dụ trong bài viết và tự mình thử nghiệm các tùy chọn khác nhau. Càng sử dụng nhiều, bạn sẽ càng thấy được sự tiện lợi mà sort mang lại.
Để tiếp tục hành trình khám phá và nâng cao kỹ năng làm việc trên dòng lệnh Linux, bạn có thể tìm hiểu thêm về các lệnh liên quan như Bash là gì, uniq, awk, sed, và grep. Việc kết hợp nhuần nhuyễn các công cụ này sẽ mở ra cho bạn những khả năng xử lý dữ liệu gần như vô hạn.