Bạn có biết rằng grep là một trong những lệnh hữu ích và mạnh mẽ nhất giúp bạn tìm kiếm nhanh chóng trong hệ điều hành Linux không? Đối với các nhà phát triển, quản trị viên hệ thống, hay bất kỳ ai thường xuyên làm việc trên môi trường dòng lệnh, grep thực sự là một cứu cánh. Khi phải xử lý những tệp tin có dung lượng lớn hoặc hàng ngàn dòng dữ liệu, việc tìm kiếm thông tin một cách thủ công không chỉ tốn thời gian mà còn rất dễ gây ra nhầm lẫn. Bạn có thể bỏ lỡ những chi tiết quan trọng hoặc mất hàng giờ chỉ để tìm một đoạn văn bản nhỏ.
Đây chính là lúc lệnh grep phát huy sức mạnh. Nó ra đời để giải quyết vấn đề tìm kiếm một cách nhanh chóng, chính xác và vô cùng hiệu quả. Bài viết này sẽ là kim chỉ nam của bạn, bắt đầu từ việc giới thiệu cơ bản về grep, cách sử dụng, các tùy chọn phổ biến nhất, đi kèm những ví dụ thực hành cụ thể. Hơn nữa, chúng ta sẽ khám phá cách kết hợp grep với các lệnh khác và những mẹo hữu ích để bạn làm chủ công cụ này, biến công việc tìm kiếm phức tạp trở nên đơn giản hơn bao giờ hết.
Tìm hiểu cơ bản về lệnh grep
Lệnh grep là gì? Vai trò và ưu điểm trong Linux
Lệnh grep là một công cụ dòng lệnh thiết yếu trong các hệ điều hành nhân Unix như Linux là gì. Tên gọi “grep” là viết tắt của cụm từ “globally search a regular expression and print”, có nghĩa là “tìm kiếm toàn cục một biểu thức chính quy và in ra”. Đúng như tên gọi, chức năng chính của grep là quét qua một hoặc nhiều tệp tin để tìm kiếm các dòng chứa một mẫu (pattern) nhất định và sau đó in những dòng đó ra màn hình. Mẫu tìm kiếm này có thể là một từ, một cụm từ, hoặc một biểu thức chính quy phức tạp.
Vai trò của grep vô cùng quan trọng trong việc xử lý văn bản, phân tích tệp tin log và tự động hóa các tác vụ bằng script. Thay vì phải mở từng tệp và dò tìm thủ công, bạn chỉ cần một dòng lệnh đơn giản để lọc ra chính xác thông tin mình cần. Ưu điểm lớn nhất của grep là tốc độ và sự linh hoạt. Nó xử lý các tệp lớn cực kỳ nhanh chóng và hỗ trợ biểu thức chính quy (regular expressions – regex), cho phép bạn tạo ra các mẫu tìm kiếm phức tạp để khớp với hầu hết mọi loại dữ liệu bạn có thể tưởng tượng.

Cách sử dụng cơ bản của lệnh grep
Để bắt đầu với grep, bạn chỉ cần nắm vững cú pháp cơ bản của nó. Cú pháp này rất đơn giản và dễ nhớ, giúp bạn nhanh chóng áp dụng vào công việc hàng ngày. Cấu trúc lệnh grep cơ bản như sau: grep [tùy_chọn] "mẫu_tìm_kiếm" [tên_file]. Trong đó, “mẫu_tìm_kiếm” là từ khóa hoặc chuỗi ký tự bạn muốn tìm, và [tên_file] là tệp tin bạn muốn tìm kiếm bên trong.
Hãy bắt đầu với một ví dụ đơn giản nhất: tìm kiếm một từ khóa trong một tệp tin. Giả sử bạn có một tệp tin tên là `vi_du.txt` và bạn muốn tìm tất cả các dòng chứa từ “AZWEB“. Bạn chỉ cần chạy lệnh: grep "AZWEB" vi_du.txt. Ngay lập tức, tất cả các dòng có chứa từ “AZWEB” sẽ được hiển thị trên màn hình của bạn.
Nếu bạn muốn tìm kiếm trong nhiều tệp tin cùng lúc thì sao? Rất đơn giản, bạn chỉ cần liệt kê các tên tệp sau mẫu tìm kiếm. Ví dụ: grep "Hosting" file1.txt file2.txt. Lệnh này sẽ tìm từ “Hosting” trong cả `file1.txt` và `file2.txt`, đồng thời hiển thị tên tệp trước mỗi dòng kết quả để bạn dễ dàng phân biệt. Với những bước cơ bản này, bạn đã có thể bắt đầu khai thác sức mạnh của grep.
Các tùy chọn phổ biến đi kèm lệnh grep
Một số tham số thường dùng
Để biến grep thành một công cụ tìm kiếm thực sự mạnh mẽ, bạn cần làm quen với các tùy chọn (tham số) đi kèm. Những tùy chọn này cho phép bạn tùy chỉnh cách grep hoạt động để phù hợp với nhuoyệu-cau cụ thể. Dưới đây là một số tham số phổ biến và cực kỳ hữu ích mà bạn nên biết.
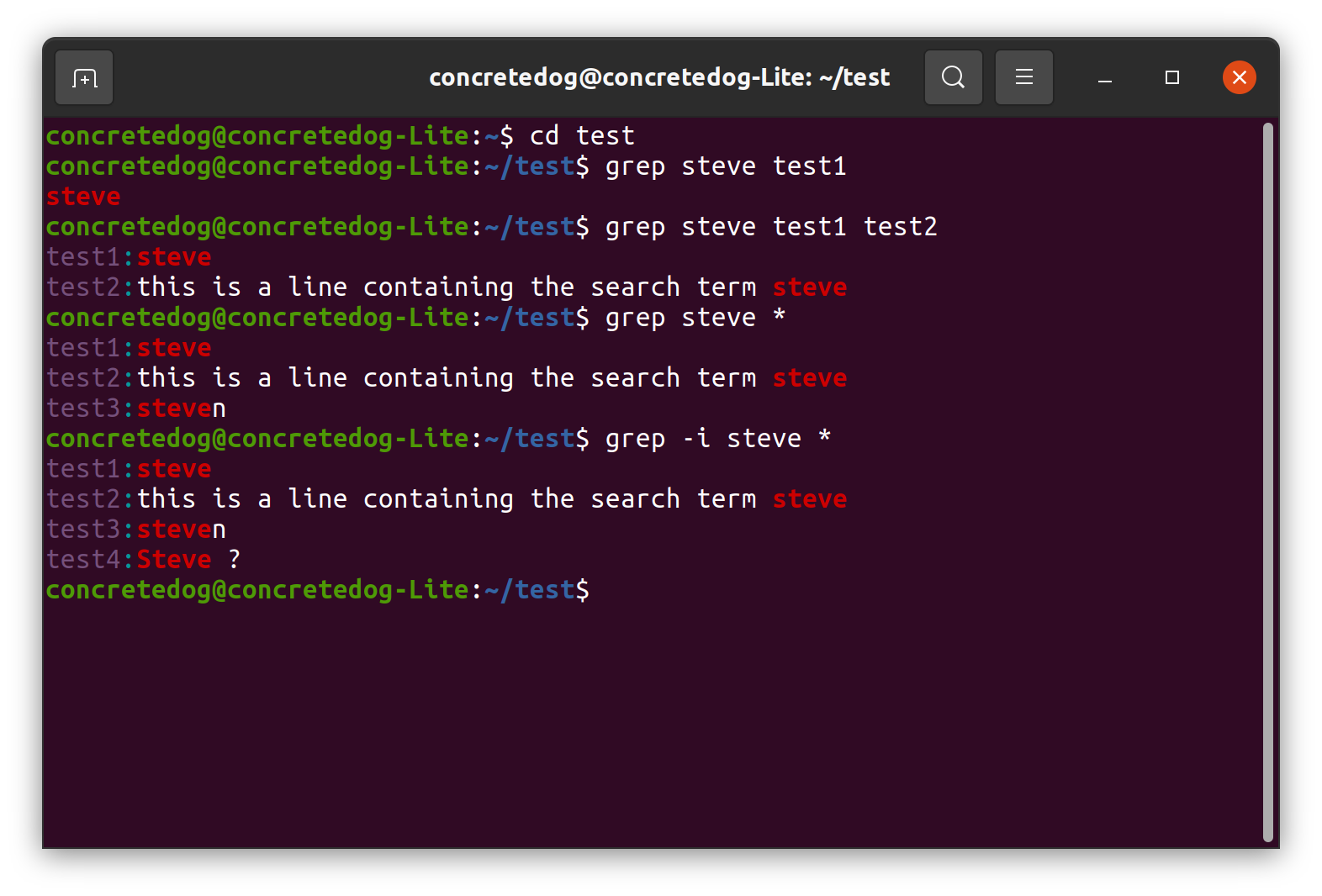
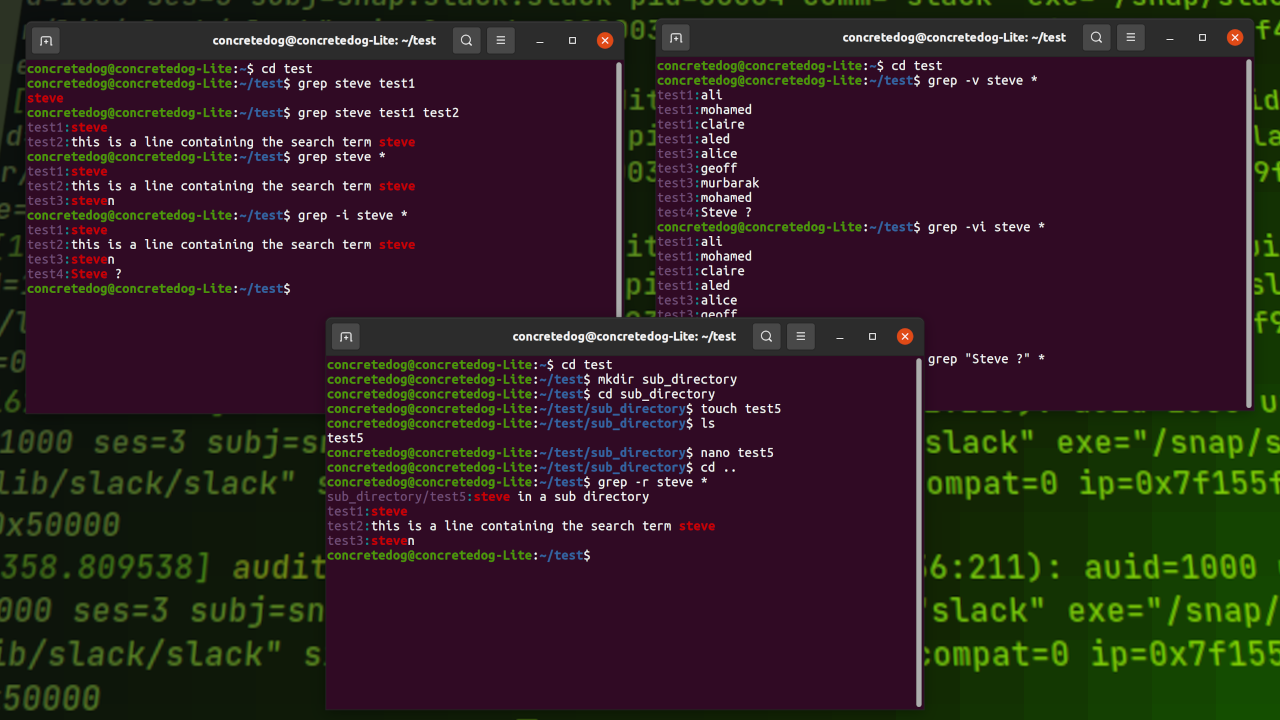
Đầu tiên là tùy chọn -i (ignore case), giúp tìm kiếm mà không phân biệt chữ hoa hay chữ thường. Ví dụ, khi bạn chạy lệnh grep -i "error" log.txt, nó sẽ tìm thấy cả “error”, “Error”, và “ERROR”. Tùy chọn -r hoặc -R (recursive) cho phép bạn tìm kiếm đệ quy trong một thư mục và tất cả các thư mục con của nó. Lệnh grep -r "database_connection" /etc/ sẽ quét toàn bộ thư mục `/etc/` để tìm chuỗi “database_connection”.
Một tùy chọn hữu ích khác là -v (invert match), dùng để hiển thị những dòng KHÔNG chứa từ khóa. Nếu bạn muốn xem tất cả các tiến trình đang chạy ngoại trừ những tiến trình của người dùng “root”, bạn có thể dùng: ps aux | grep -v "root". Để biết kết quả nằm ở dòng nào, hãy dùng -n (line number), nó sẽ thêm số thứ tự dòng vào trước mỗi kết quả. Cuối cùng, nếu bạn chỉ muốn biết có bao nhiêu dòng khớp với mẫu tìm kiếm, hãy dùng -c (count). Ví dụ: grep -c "success" access.log sẽ cho bạn biết số lần truy cập thành công được ghi lại.
Các biến thể nâng cao
Ngoài các tham số cơ bản, grep còn cung cấp các biến thể nâng cao để xử lý những yêu cầu tìm kiếm phức tạp hơn. Một trong những tính năng mạnh mẽ nhất là khả năng sử dụng biểu thức chính quy mở rộng (extended regular expressions) với tùy chọn -E hoặc dùng lệnh egrep. Điều này cho phép bạn tạo ra các mẫu tìm kiếm linh hoạt hơn, ví dụ như tìm các dòng chứa “từ khóa 1” hoặc “từ khóa 2” bằng lệnh: grep -E "keyword1|keyword2" filename.txt.
Đôi khi, bạn chỉ muốn tìm một từ hoàn chỉnh chứ không phải một phần của từ khác. Ví dụ, tìm từ “web” nhưng không muốn kết quả trả về có chứa “website”. Tùy chọn -w (word regexp) sẽ giúp bạn làm điều đó. Lệnh grep -w "web" data.txt sẽ chỉ trả về các dòng chứa chính xác từ “web”.
Để kết quả tìm kiếm trở nên trực quan và dễ đọc hơn, đặc biệt là khi xem qua các tệp log dài, bạn nên sử dụng tùy chọn --color=auto. Tùy chọn này sẽ tự động tô màu từ khóa hoặc mẫu tìm kiếm trong kết quả trả về, giúp bạn nhanh chóng xác định thông tin quan trọng. Hầu hết các bản phân phối Linux hiện đại như Fedora, Debian, hay Ubuntu đều đã cài đặt sẵn alias cho grep để tự động bật tùy chọn này. Nhờ vậy, việc lướt qua hàng trăm dòng kết quả trở nên dễ dàng và đỡ mỏi mắt hơn rất nhiều.
Ví dụ thực hành với lệnh grep trong nhiều tình huống
Tìm kiếm trong file log
Một trong những ứng dụng phổ biến nhất của grep là phân tích tệp tin log. Các tệp log hệ thống thường chứa hàng ngàn, thậm chí hàng triệu dòng thông tin, và việc tìm kiếm lỗi hoặc một sự kiện cụ thể bằng tay là không thể. Đây là lúc grep trở thành người bạn đồng hành không thể thiếu của các quản trị viên hệ thống.
Hãy tưởng tượng bạn đang cần kiểm tra xem có lỗi (error) nào được ghi lại trong tệp log hệ thống hay không. Tệp log này thường nằm ở /var/log/syslog hoặc /var/log/messages. Bạn có thể sử dụng lệnh sau: grep -i "error" /var/log/syslog. Tùy chọn -i đảm bảo rằng bạn sẽ tìm thấy cả “error” và “Error”. Kết quả sẽ hiển thị tất cả các dòng chứa thông tin lỗi, giúp bạn nhanh chóng chẩn đoán sự cố. Để xem thêm ngữ cảnh xung quanh dòng lỗi, bạn có thể dùng tùy chọn -C (context), ví dụ grep -i -C 5 "error" /var/log/syslog sẽ hiển thị 5 dòng trước và 5 dòng sau dòng chứa lỗi.
Tìm kiếm nhiều từ khóa cùng lúc
Trong nhiều trường hợp, bạn không chỉ muốn tìm một từ khóa duy nhất mà cần lọc ra các dòng chứa một trong nhiều từ khóa khác nhau. Grep cung cấp nhiều cách để thực hiện điều này một cách hiệu quả. Cách đơn giản nhất là sử dụng biểu thức chính quy mở rộng với tùy chọn -E.
Giả sử bạn muốn tìm tất cả các dòng trong tệp application.log chứa từ “ERROR” hoặc “WARNING”. Bạn có thể sử dụng toán tử | (OR) trong biểu thức chính quy. Lệnh sẽ là: grep -E "ERROR|WARNING" application.log. Lệnh này sẽ trả về bất kỳ dòng nào khớp với một trong hai mẫu trên, giúp bạn có cái nhìn tổng quan về các vấn đề tiềm ẩn. Đừng quên thêm tùy chọn -i nếu bạn muốn tìm kiếm không phân biệt hoa thường. Một cách khác, tuy dài hơn nhưng cũng hiệu quả, là sử dụng nhiều tùy chọn -e. Lệnh grep -e "ERROR" -e "WARNING" application.log cũng cho kết quả tương tự.
Sử dụng grep trong pipeline với các lệnh khác
Sức mạnh thực sự của grep và triết lý của Linux được thể hiện khi bạn kết hợp nó với các lệnh khác thông qua cơ chế “pipeline” (đường ống), được biểu thị bằng dấu |. Pipeline cho phép bạn lấy đầu ra của một lệnh và dùng nó làm đầu vào cho lệnh tiếp theo. Điều này tạo ra một chuỗi xử lý dữ liệu cực kỳ linh hoạt.
Ví dụ, lệnh ps aux liệt kê tất cả các tiến trình đang chạy trên hệ thống, nhưng kết quả thường rất dài. Nếu bạn chỉ muốn xem các tiến trình liên quan đến máy chủ web Apache, bạn có thể lọc đầu ra của ps bằng grep: ps aux | grep "apache". Lệnh này chỉ hiển thị những dòng từ ps aux có chứa từ “apache”. Tương tự, bạn có thể kết hợp grep với lệnh cd trong Linux hoặc ls -l để tìm các tệp tin có tên cụ thể trong một thư mục lớn: ls -l /var/www/html | grep ".php". Hoặc bạn có thể dùng cat để đọc nội dung file và pipe qua grep: cat access.log | grep "404" để tìm các lỗi 404 Not Found.

Cách kết hợp grep với các lệnh khác để tăng hiệu quả tìm kiếm
Kết hợp với lệnh pipe (|)
Như đã đề cập, lệnh pipe (|) là cầu nối ma thuật trong thế giới dòng lệnh Linux. Nó cho phép các lệnh giao tiếp với nhau, tạo thành một dây chuyền xử lý dữ liệu mạnh mẽ. Khi kết hợp với grep, pipe mở ra vô vàn khả năng lọc và xử lý thông tin. Triết lý ở đây là mỗi công cụ làm tốt một việc, và pipe kết nối chúng lại với nhau.
Bạn có thể dùng grep để lọc đầu ra của hầu hết mọi lệnh. Ví dụ, bạn muốn tìm một gói phần mềm đã cài đặt nhưng không nhớ chính xác tên của nó. Bạn có thể liệt kê tất cả các gói đã cài và dùng grep để lọc: dpkg -l | grep -i "php" (trên hệ thống Debian/Ubuntu) hoặc rpm -qa | grep -i "httpd" (trên hệ thống CentOS/RHEL). Một ví dụ khác là khi bạn theo dõi một tệp log đang thay đổi liên tục bằng lệnh tail -f. Để chỉ xem các dòng lỗi mới xuất hiện, bạn có thể dùng: tail -f /var/log/nginx/error.log | grep --color=auto "critical". Kết quả sẽ được cập nhật trực tiếp trên màn hình và các lỗi nghiêm trọng sẽ được tô màu nổi bật.
Kết hợp với awk, sed và xargs
Để nâng cao khả năng xử lý văn bản lên một tầm cao mới, bạn có thể kết hợp grep với các công cụ mạnh mẽ khác như awk, sed và xargs. Sự kết hợp này cho phép bạn không chỉ tìm kiếm mà còn trích xuất, biến đổi và thực thi hành động trên kết quả tìm được.
awk là một công cụ tuyệt vời để xử lý dữ liệu có cấu trúc theo cột. Giả sử bạn muốn tìm tất cả các tiến trình đang chiếm dụng nhiều bộ nhớ và chỉ lấy ra tên người dùng và mã tiến trình (PID). Bạn có thể làm như sau: ps aux | grep "chrome" | awk '{print $1, $2}'. Ở đây, grep lọc ra các tiến trình Chrome, sau đó awk in ra cột đầu tiên (người dùng) và cột thứ hai (PID).
sed (stream editor) lại mạnh về việc tìm kiếm và thay thế văn bản. Bạn có thể dùng grep để tìm các dòng cần sửa, sau đó dùng sed để thực hiện thay đổi. Ví dụ: tìm tất cả các file cấu hình chứa “old_database_name” và thay thế bằng “new_database_name”.
Cuối cùng, xargs là công cụ dùng để xây dựng và thực thi các dòng lệnh từ đầu vào chuẩn. Ví dụ, bạn muốn tìm tất cả các tệp tin có tên `error.log` trong cây thư mục hiện tại và xóa chúng. Lệnh sẽ là: find . -name "error.log" | xargs rm. Kết hợp với grep, bạn có thể tìm các tệp chứa một chuỗi cụ thể rồi thực hiện một hành động nào đó trên chúng, ví dụ: grep -rl "DEPRECATED" /var/www/project | xargs mv -t /var/www/deprecated_files/.
Các mẹo và lưu ý khi sử dụng lệnh grep
Mẹo tăng tốc tìm kiếm nhanh hơn
Khi làm việc với các tệp tin khổng lồ hoặc cây thư mục phức tạp, tốc độ của grep có thể bị ảnh hưởng. Tuy nhiên, có nhiều mẹo bạn có thể áp dụng để tăng tốc quá trình tìm kiếm. Mẹo quan trọng nhất là hạn chế vùng tìm kiếm càng nhiều càng tốt. Thay vì chạy grep -r "từ_khóa" /, hãy chỉ định một thư mục cụ thể hơn nếu bạn biết nơi có khả năng chứa thông tin, ví dụ: grep -r "từ_khóa" /var/log/. Bạn cũng có thể tham khảo các hướng dẫn nâng cao trong bài viết Bash là gì để phối hợp các shell script tối ưu hơn.
Một kỹ thuật khác là sử dụng các biến thể của grep được tối ưu hóa cho từng trường hợp. Ví dụ, fgrep (tương đương grep -F) được thiết kế để tìm kiếm các chuỗi cố định (fixed strings) thay vì biểu thức chính quy. Nếu bạn chỉ cần tìm một từ khóa đơn giản, fgrep sẽ nhanh hơn đáng kể so với grep thông thường vì nó không cần phải xử lý sự phức tạp của regex. Ngoài ra, hãy cố gắng tránh chạy grep trên các tệp nhị phân bằng cách sử dụng tùy chọn -I (viết hoa i), lệnh sẽ bỏ qua các file binary, giúp quá trình tìm kiếm không bị gián đoạn hoặc trả về kết quả rác.
Lưu ý khi sử dụng biểu thức chính quy
Biểu thức chính quy (regex) là một công cụ cực kỳ mạnh mẽ, nhưng cũng dễ gây ra lỗi nếu không cẩn thận. Một lỗi phổ biến là quên đặt mẫu tìm kiếm trong dấu ngoặc kép ("") hoặc ngoặc đơn (''). Khi mẫu tìm kiếm chứa các ký tự đặc biệt của shell (như *, $, |), việc không có dấu ngoặc sẽ khiến shell diễn giải chúng trước khi truyền cho grep, dẫn đến kết quả sai hoặc lỗi cú pháp.
Một lưu ý khác là sự khác biệt giữa biểu thức chính quy cơ bản (Basic Regular Expressions – BRE) và mở rộng (Extended Regular Expressions – ERE). Theo mặc định, grep sử dụng BRE, trong đó các ký tự đặc biệt như ?, +, {}, |, () mất đi ý nghĩa đặc biệt của chúng và phải được thoát bằng dấu gạch chéo ngược (\) để sử dụng. Ngược lại, khi bạn dùng grep -E hoặc egrep, các ký tự này lại có ý nghĩa đặc biệt. Hiểu rõ sự khác biệt này sẽ giúp bạn tránh được nhiều giờ gỡ lỗi mệt mỏi. Luôn kiểm tra regex của bạn trên một mẫu dữ liệu nhỏ trước khi áp dụng vào các tệp lớn hoặc trong các script tự động hóa.
Các vấn đề thường gặp và cách khắc phục
grep không tìm thấy kết quả dù chắc chắn có từ khóa
Một trong những tình huống khó chịu nhất là khi bạn chắc chắn rằng từ khóa tồn tại trong tệp, nhưng grep lại không trả về kết quả nào. Nguyên nhân phổ biến nhất là do phân biệt chữ hoa và chữ thường. Grep theo mặc định là case-sensitive. Nếu bạn tìm “error” nhưng trong tệp lại ghi là “Error” hoặc “ERROR”, grep sẽ bỏ qua. Giải pháp rất đơn giản: luôn sử dụng tùy chọn -i (grep -i "từ_khóa" tên_file) để tìm kiếm không phân biệt hoa thường, trừ khi bạn có lý do đặc biệt cần sự chính xác tuyệt đối.
Một nguyên nhân khác có thể là do encoding của tệp tin. Grep hoạt động tốt nhất với các tệp văn bản thuần túy (plain text) được mã hóa theo chuẩn UTF-8 hoặc ASCII. Nếu tệp của bạn được lưu ở một định dạng mã hóa khác (như UTF-16), grep có thể không đọc được nội dung một cách chính xác. Bạn có thể kiểm tra encoding của tệp bằng lệnh file tên_file. Nếu vấn đề là encoding, bạn có thể cần chuyển đổi tệp về UTF-8 bằng lệnh iconv trước khi thực hiện tìm kiếm.
Kết quả grep quá nhiều/không chính xác
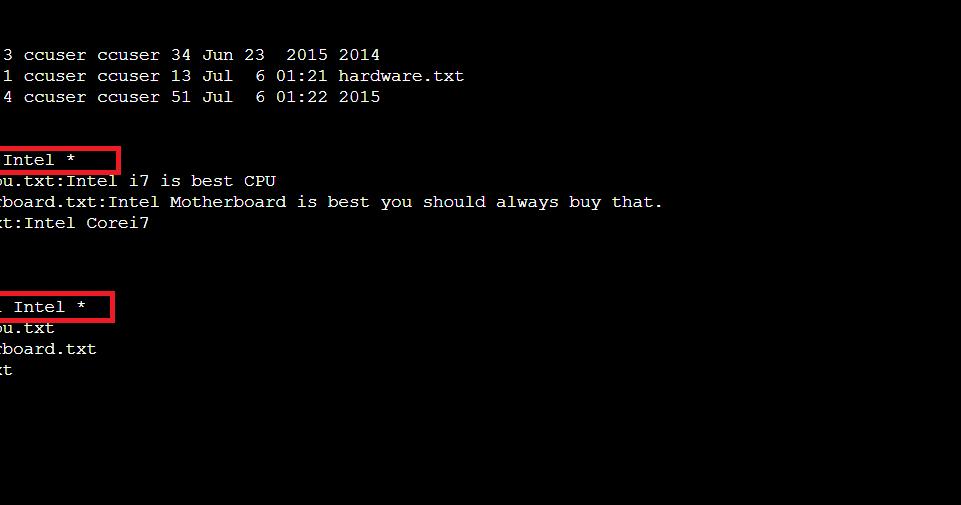
Ngược lại với vấn đề trên, đôi khi grep lại trả về quá nhiều kết quả, khiến bạn bị “ngập” trong thông tin và khó tìm ra thứ mình cần. Điều này thường xảy ra khi từ khóa của bạn quá chung chung. Ví dụ, tìm từ “web” có thể trả về cả “website”, “webserver”, “web-framework”.
Để giải quyết vấn đề này, hãy làm cho mẫu tìm kiếm của bạn cụ thể hơn. Sử dụng tùy chọn -w để grep chỉ tìm các từ hoàn chỉnh. Lệnh grep -w "web" data.txt sẽ chỉ khớp với từ “web” đứng riêng lẻ. Bạn cũng có thể sử dụng biểu thức chính quy để xác định ranh giới từ (\b), ví dụ: grep "\bweb\b" data.txt. Nếu kết quả vẫn còn quá nhiều, bạn có thể kết hợp grep với các lệnh khác như head hoặc tail để chỉ xem một phần kết quả, ví dụ: grep "request" access.log | head -n 20 sẽ chỉ hiển thị 20 kết quả đầu tiên.
Best Practices khi sử dụng lệnh grep
Để sử dụng grep một cách chuyên nghiệp và hiệu quả nhất, hãy tuân thủ một vài quy tắc và thói quen tốt (best practices). Những thói quen này không chỉ giúp bạn làm việc nhanh hơn mà còn đảm bảo kết quả chính xác và dễ quản lý.
Thứ nhất, hãy tập thói quen sử dụng tùy chọn -n (hiển thị số dòng) khi làm việc với các tệp mã nguồn hoặc tệp cấu hình lớn. Biết được số dòng của kết quả giúp bạn nhanh chóng điều hướng đến đúng vị trí trong trình soạn thảo văn bản. Tương tự, hãy dùng -i (không phân biệt hoa thường) một cách mặc định, trừ khi bạn thực sự cần tìm kiếm chính xác theo kiểu chữ.
Thứ hai, luôn cẩn thận khi chạy grep trên các tệp không phải văn bản. Grep được thiết kế để xử lý văn bản, việc chạy nó trên tệp nhị phân (binary file) có thể tạo ra kết quả vô nghĩa và làm đầy màn hình của bạn bằng các ký tự lạ. Hãy sử dụng tùy chọn -I để grep tự động bỏ qua các tệp nhị phân khi tìm kiếm đệ quy.
Thứ ba, đừng chỉ dựa vào grep. Hãy kết hợp nó với các công cụ dòng lệnh khác như awk, sed, sort, uniq, và xargs để tạo thành một chuỗi xử lý mạnh mẽ. Ví dụ, bạn có thể dùng grep để tìm lỗi, sort để sắp xếp, và uniq -c để đếm số lần xuất hiện của mỗi lỗi duy nhất.
Cuối cùng, và quan trọng nhất, luôn kiểm tra lại lệnh và kết quả của bạn trước khi sử dụng chúng trong các script tự động hóa hoặc các lệnh có khả năng thay đổi dữ liệu (như kết hợp với rm hoặc sed -i). Một mẫu tìm kiếm sai có thể dẫn đến những hậu quả không mong muốn. Hãy thử nghiệm trên các tệp mẫu hoặc sử dụng các tùy chọn “dry-run” nếu có.
Kết luận
Qua bài viết này, chúng ta đã cùng nhau khám phá lệnh grep – một trong những công cụ dòng lệnh linh hoạt và không thể thiếu trong hộp đồ nghề của bất kỳ ai làm việc với Linux. Từ những cú pháp cơ bản nhất để tìm một từ khóa, cho đến việc sử dụng các tùy chọn nâng cao, kết hợp với biểu thức chính quy và pipeline, grep chứng tỏ vai trò quan trọng của mình trong việc xử lý văn bản, phân tích log và quản trị hệ thống.
Sức mạnh của grep không chỉ nằm ở tốc độ mà còn ở khả năng biến những tác vụ tìm kiếm phức tạp, tốn thời gian trở nên đơn giản và nhanh chóng. AZWEB khuyến khích bạn hãy bắt đầu thực hành ngay hôm nay. Hãy mở terminal lên, thử tìm kiếm trong các tệp tin của bạn, phân tích các tệp log và dần dần kết hợp grep với các lệnh khác. Càng sử dụng nhiều, bạn sẽ càng thấy được sự kỳ diệu của nó. Đừng ngần ngại học thêm về biểu thức chính quy (regex), vì đó chính là chìa khóa để khai phá toàn bộ tiềm năng của grep, giúp bạn nâng cao kỹ năng quản lý hệ thống và xử lý dữ liệu lên một tầm cao mới.