Trong kỷ nguyên số hóa, dữ liệu được ví như “mỏ vàng” cho mọi doanh nghiệp. Tuy nhiên, việc khai thác “mỏ vàng” này chưa bao giờ là dễ dàng khi chúng ta phải đối mặt với Big Data – dữ liệu khổng lồ. Các nền tảng xử lý truyền thống thường tỏ ra chậm chạp và kém hiệu quả, gây cản trở cho việc phân tích và ra quyết định. Đây chính là lúc Apache Spark xuất hiện như một vị cứu tinh. Apache Spark là một framework xử lý dữ liệu mạnh mẽ, mang đến tốc độ và sự linh hoạt vượt trội. Bài viết này sẽ cùng bạn tìm hiểu sâu hơn về Apache Spark, từ khái niệm, cấu trúc, ưu điểm, đến các ứng dụng thực tế và so sánh với những công cụ khác.
Khái niệm về Apache Spark
Apache Spark là gì?
Apache Spark là một framework mã nguồn mở, dùng cho việc xử lý dữ liệu phân tán quy mô lớn. Nó cung cấp một giao diện lập trình đơn giản để xử lý các tập dữ liệu khổng lồ một cách nhanh chóng và hiệu quả. Bạn có thể hình dung Spark như một công cụ vạn năng, giúp bạn phân tích, xử lý và chuyển đổi dữ liệu từ nhiều nguồn khác nhau mà không cần lo lắng về sự phức tạp của hệ thống phân tán.
![]()
Lịch sử của Spark bắt đầu từ năm 2009 tại phòng thí nghiệm AMPLab của Đại học California, Berkeley. Ban đầu, nó được phát triển để khắc phục những hạn chế về tốc độ của Hadoop MapReduce. Đến năm 2014, Spark trở thành một dự án cấp cao của Apache Software Foundation và nhanh chóng trở thành một trong những dự án mã nguồn mở về dữ liệu lớn phát triển mạnh mẽ nhất thế giới.
Những thành phần chính trong Apache Spark
Apache Spark không phải là một công cụ đơn lẻ mà là một hệ sinh thái gồm nhiều thành phần được tích hợp chặt chẽ. Mỗi thành phần đảm nhận một vai trò riêng, giúp Spark trở nên đa năng và mạnh mẽ. Hãy cùng khám phá những thành phần cốt lõi này.
- Spark Core: Đây là trái tim của Apache Spark. Spark Core cung cấp các chức năng cơ bản như quản lý tác vụ, quản lý bộ nhớ, xử lý lỗi và điều phối các hoạt động I/O. Tất cả các thành phần khác đều được xây dựng trên nền tảng của Spark Core.
- Spark SQL: Thành phần này cho phép bạn truy vấn dữ liệu có cấu trúc bằng cách sử dụng cú pháp SQL quen thuộc. Spark SQL giúp các nhà phân tích dữ liệu và lập trình viên dễ dàng làm việc với dữ liệu mà không cần phải viết các đoạn mã phức tạp. Nó hỗ trợ nhiều định dạng dữ liệu như JSON, Parquet, và Hive. Để hiểu rõ hơn về ngôn ngữ truy vấn trong xử lý dữ liệu, bạn có thể tham khảo SQL là gì và các kiến thức liên quan.
- Spark Streaming: Đối với các ứng dụng cần xử lý dữ liệu theo thời gian thực, Spark Streaming là một lựa chọn hoàn hảo. Nó có khả năng thu thập và xử lý dữ liệu từ các nguồn live stream như Kafka, Flume, hoặc Kinesis, giúp doanh nghiệp đưa ra quyết định nhanh chóng dựa trên dữ liệu mới nhất.
- MLlib (Machine Learning Library): MLlib là thư viện học máy tích hợp của Spark. Nó cung cấp một bộ công cụ phong phú với các thuật toán học máy phổ biến như phân loại, hồi quy, gom cụm và lọc cộng tác. Nhờ khả năng xử lý song song, MLlib giúp việc huấn luyện mô hình trên các tập dữ liệu lớn trở nên nhanh hơn rất nhiều. Bạn có thể tìm hiểu thêm về các ứng dụng Machine Learning là gì để biết cách MLlib hoạt động trong học máy.
- GraphX: Khi cần phân tích các mối quan hệ phức tạp, chẳng hạn như mạng xã hội hoặc chuỗi cung ứng, GraphX sẽ là công cụ đắc lực. Đây là API của Spark dùng để xử lý đồ thị và thực hiện các phép tính song song trên cấu trúc đồ thị.
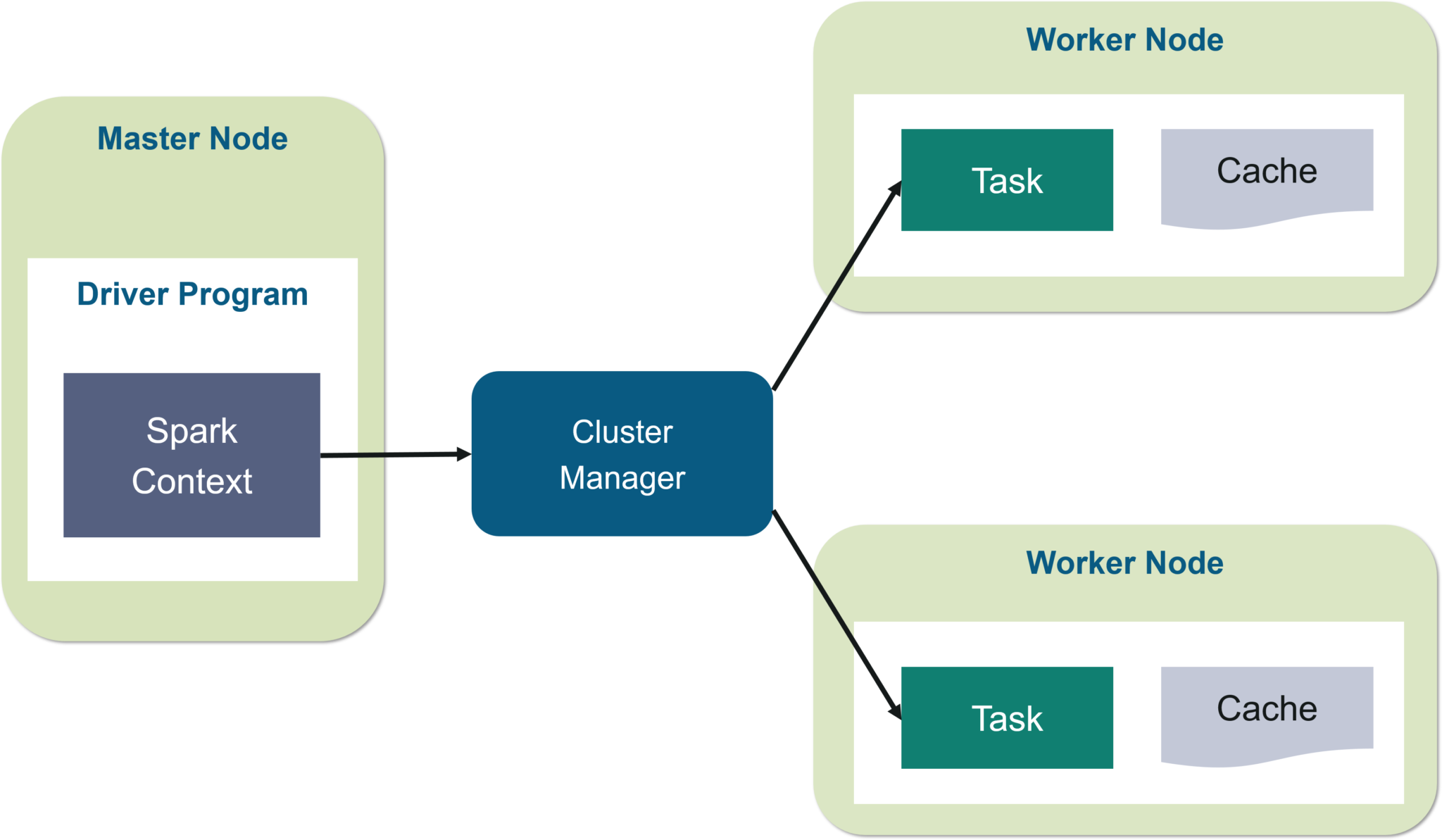
Cấu trúc và các thành phần chính của Apache Spark
Kiến trúc phân tán của Apache Spark
Sức mạnh của Apache Spark nằm ở kiến trúc phân tán thông minh, cho phép nó xử lý khối lượng công việc khổng lồ một cách hiệu quả. Kiến trúc này hoạt động theo mô hình chủ-tớ (master-slave) và bao gồm ba thành phần chính. Bạn có thể tưởng tượng nó giống như một công trường xây dựng được tổ chức tốt.
Đầu tiên là Driver Program, đóng vai trò như người quản lý dự án. Đây là nơi chứa hàm main() của ứng dụng Spark và chịu trách nhiệm tạo ra SparkContext. Driver Program sẽ phân tích, lập kế hoạch và phân phối các tác vụ cho các worker node. Tiếp theo là Cluster Manager, giống như người điều phối tài nguyên, có nhiệm vụ cấp phát tài nguyên tính toán cho ứng dụng. Spark hỗ trợ nhiều loại Cluster Manager khác nhau như Standalone, Apache Mesos, Hadoop YARN, và Kubernetes.

Cuối cùng là các Executor, tương tự như những người công nhân trên công trường. Các Executor chạy trên các worker node, nhận tác vụ từ Driver Program và thực thi chúng. Mỗi Executor có một số lượng “core” (lõi) nhất định để chạy tác vụ song song và quản lý bộ nhớ riêng. Driver Program, Cluster Manager và các Executor cùng nhau tạo thành một hệ thống phối hợp nhịp nhàng để hoàn thành công việc một cách nhanh nhất.
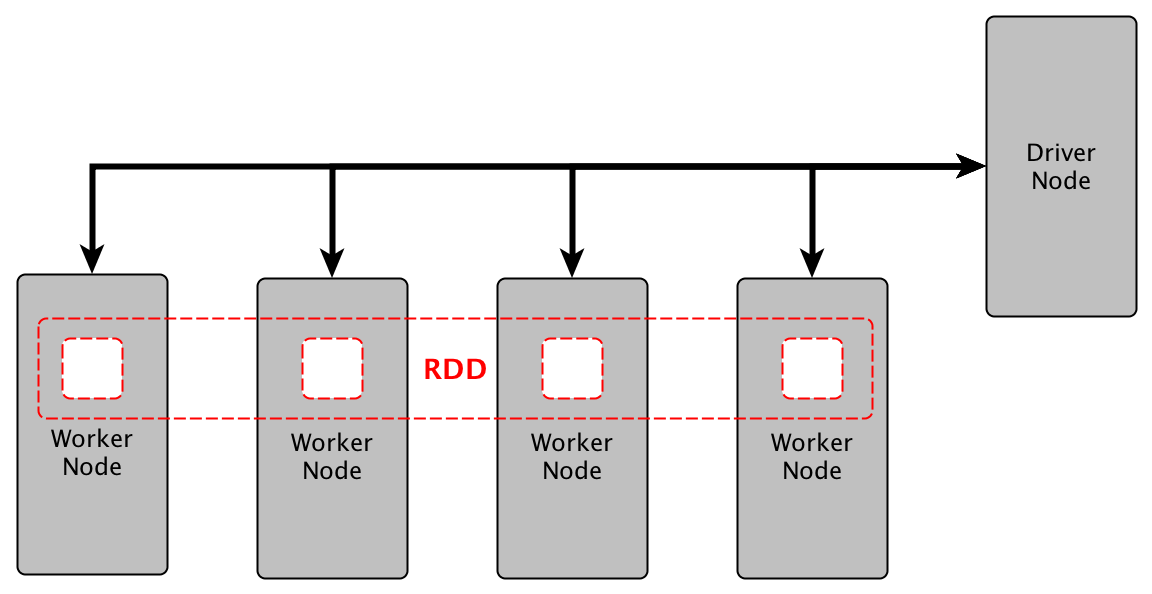
DataFrame và RDD – 2 đối tượng dữ liệu quan trọng
Khi làm việc với Spark, bạn sẽ thường xuyên tiếp xúc với hai khái niệm trừu tượng về dữ liệu là RDD và DataFrame. Hiểu rõ sự khác biệt giữa chúng là chìa khóa để tối ưu hóa hiệu suất ứng dụng. RDD (Resilient Distributed Dataset) là cấu trúc dữ liệu cơ bản và là nền tảng của Spark. Nó là một tập hợp các đối tượng được phân tán trên nhiều máy trong cluster, có khả năng tự phục hồi khi có lỗi xảy ra. RDD cung cấp khả năng kiểm soát ở mức độ thấp, rất linh hoạt nhưng đòi hỏi lập trình viên phải tự tối ưu hóa mã của mình. Bạn có thể xem thêm về Data Science là gì để hiểu thêm về các kỹ thuật xử lý và phân tích dữ liệu.
Mặt khác, DataFrame là một cấu trúc dữ liệu trừu tượng cao cấp hơn, được giới thiệu sau RDD. Một DataFrame tổ chức dữ liệu thành các cột có tên, tương tự như một bảng trong cơ sở dữ liệu quan hệ hoặc một data frame trong Python/R. Sự khác biệt lớn nhất là DataFrame có chứa thông tin về lược đồ (schema), cho phép Spark tối ưu hóa các truy vấn thông qua bộ tối ưu hóa Catalyst. Điều này giúp mã chạy trên DataFrame thường nhanh hơn đáng kể so với mã tương đương trên RDD. Bạn cũng có thể tham khảo thêm Python là gì để biết ngôn ngữ lập trình phổ biến trong xử lý dữ liệu trong Spark.

Vậy khi nào nên dùng cái nào? Lời khuyên chung là hãy ưu tiên sử dụng DataFrame API bất cứ khi nào có thể vì hiệu suất vượt trội và sự dễ sử dụng của nó. Bạn chỉ nên quay lại sử dụng RDD khi cần xử lý dữ liệu phi cấu trúc hoặc khi cần thực hiện các thao tác biến đổi ở mức độ thấp mà DataFrame không hỗ trợ.
Ưu điểm của Apache Spark trong xử lý dữ liệu lớn
Tốc độ xử lý vượt trội
Một trong những lý do chính khiến Apache Spark trở nên phổ biến chính là tốc độ xử lý đáng kinh ngạc. So với Hadoop MapReduce, một trong những framework tiên phong trong xử lý dữ liệu lớn, Spark có thể chạy nhanh hơn tới 100 lần. Vậy bí mật đằng sau tốc độ này là gì? Câu trả lời nằm ở khả năng xử lý dữ liệu trong bộ nhớ (in-memory computing). Thay vì phải đọc và ghi dữ liệu từ đĩa cứng sau mỗi bước xử lý như MapReduce, Spark giữ dữ liệu trung gian trong bộ nhớ RAM của cluster. Việc truy cập dữ liệu từ RAM nhanh hơn rất nhiều so với từ đĩa cứng, giúp giảm đáng kể độ trễ và tăng tốc toàn bộ quy trình.

Cơ chế này đặc biệt hiệu quả đối với các thuật toán lặp, chẳng hạn như trong Machine Learning, nơi một tập dữ liệu cần được xử lý qua lại nhiều lần. Nhờ vậy, các doanh nghiệp có thể rút ngắn thời gian phân tích từ vài giờ xuống chỉ còn vài phút, cho phép họ đưa ra các quyết định kinh doanh nhanh nhạy hơn.
Linh hoạt và đa dạng trong xử lý
Bên cạnh tốc độ, sự linh hoạt cũng là một điểm cộng lớn của Apache Spark. Framework này không giới hạn bạn trong một ngôn ngữ lập trình duy nhất. Nó cung cấp các API phong phú và nhất quán cho nhiều ngôn ngữ phổ biến như Scala, Python, Java, và R. Điều này cho phép các nhóm phát triển với những kỹ năng khác nhau có thể cùng cộng tác trên một nền tảng chung. Dù bạn là một nhà khoa học dữ liệu quen thuộc với Python hay một kỹ sư phần mềm chuyên về Java, bạn đều có thể dễ dàng làm việc với Spark.
Ngoài ra, Spark được thiết kế để tích hợp liền mạch với các công cụ khác trong hệ sinh thái Big Data. Nó có thể đọc dữ liệu từ nhiều nguồn khác nhau như Hadoop Distributed File System (HDFS), Apache Cassandra, Apache HBase, và các dịch vụ lưu trữ đám mây như Amazon S3. Sự kết hợp giữa các thành phần nội tại (Spark SQL, Streaming, MLlib, GraphX) và khả năng tích hợp bên ngoài giúp Spark trở thành một trạm xử lý dữ liệu trung tâm, có thể giải quyết hầu hết mọi bài toán dữ liệu lớn.
Ứng dụng thực tế của Apache Spark trong phân tích và xử lý dữ liệu nhanh
Phân tích dữ liệu thời gian thực
Khả năng xử lý dữ liệu nhanh của Spark mở ra vô số ứng dụng trong việc phân tích thời gian thực. Trong ngành tài chính, các ngân hàng sử dụng Spark Streaming để phát hiện gian lận thẻ tín dụng. Bằng cách phân tích các giao dịch ngay khi chúng phát sinh, hệ thống có thể xác định các mẫu bất thường và chặn giao dịch đáng ngờ chỉ trong vài mili giây, bảo vệ tài sản cho cả khách hàng và ngân hàng.

Trong lĩnh vực thương mại điện tử, Spark giúp các công ty như Amazon hay Tiki cung cấp trải nghiệm cá nhân hóa cho người dùng. Hệ thống sẽ phân tích hành vi duyệt web, lịch sử mua hàng và các tương tác của khách hàng theo thời gian thực để đưa ra các gợi ý sản phẩm phù hợp ngay lập tức. Tương tự, các công ty viễn thông sử dụng Spark để phân tích dữ liệu mạng nhằm phát hiện sớm các sự cố và tối ưu hóa chất lượng dịch vụ.
Machine Learning và trí tuệ nhân tạo
Apache Spark, với thư viện MLlib, đã trở thành một nền tảng không thể thiếu cho các ứng dụng Machine Learning (học máy) và trí tuệ nhân tạo (AI) quy mô lớn. Việc huấn luyện các mô hình học máy đòi hỏi phải xử lý các tập dữ liệu khổng lồ và thực hiện nhiều vòng lặp tính toán. Tốc độ xử lý trong bộ nhớ của Spark giúp giảm đáng kể thời gian huấn luyện mô hình, cho phép các nhà khoa học dữ liệu thử nghiệm và tinh chỉnh mô hình nhanh hơn.
Ví dụ, trong ngành y tế, MLlib được sử dụng để xây dựng các mô hình dự đoán bệnh dựa trên hồ sơ bệnh án và hình ảnh y khoa. Trong ngành bán lẻ, các công ty dùng Spark để xây dựng hệ thống dự đoán nhu cầu khách hàng, giúp tối ưu hóa việc quản lý hàng tồn kho. Netflix cũng sử dụng Spark để xây dựng hệ thống gợi ý phim, phân tích thói quen xem của hàng triệu người dùng để đưa ra những đề xuất cá nhân hóa chính xác.
Xử lý dữ liệu lớn đa dạng
Thế giới hiện đại tạo ra dữ liệu từ vô số nguồn với các định dạng khác nhau, từ dữ liệu có cấu trúc trong cơ sở dữ liệu đến dữ liệu bán cấu trúc như file log hay dữ liệu phi cấu trúc như văn bản, hình ảnh. Spark có khả năng xử lý hiệu quả tất cả các loại dữ liệu này. Ví dụ, các công ty công nghệ thường sử dụng Spark để phân tích hàng terabyte dữ liệu log máy chủ mỗi ngày. Việc này giúp họ giám sát sức khỏe hệ thống, phát hiện lỗi và tìm hiểu hành vi người dùng. Để hiểu thêm về cơ sở dữ liệu và các loại dữ liệu, bạn có thể xem tại Database là gì và NoSQL là gì.

Với sự bùng nổ của Internet vạn vật (IoT), Spark cũng đóng vai trò quan trọng trong việc xử lý dòng dữ liệu liên tục từ hàng triệu cảm biến. Dữ liệu này có thể được dùng để tối ưu hóa hoạt động của nhà máy thông minh, quản lý giao thông đô thị, hoặc theo dõi sức khỏe từ xa. Ngoài ra, Spark còn được dùng để phân tích dữ liệu từ các mạng xã hội (Social Media) nhằm nắm bắt xu hướng thị trường và phân tích cảm tính của khách hàng về thương hiệu.
So sánh Apache Spark với các nền tảng xử lý dữ liệu lớn khác
Apache Spark vs Hadoop MapReduce
Khi so sánh Apache Spark và Hadoop MapReduce, chúng ta đang nói về hai thế hệ công cụ xử lý dữ liệu lớn. Hadoop MapReduce là người tiên phong, đặt nền móng cho cuộc cách mạng Big Data. Điểm mạnh của nó là khả năng xử lý các tập dữ liệu cực lớn một cách ổn định và chịu lỗi tốt. MapReduce xử lý dữ liệu theo lô (batch processing) và ghi kết quả trung gian xuống đĩa cứng (HDFS), điều này làm cho nó rất đáng tin cậy nhưng cũng khá chậm chạp.
Apache Spark ra đời như một sự cải tiến vượt bậc. Điểm mạnh lớn nhất của Spark là tốc độ, nhờ vào cơ chế xử lý trong bộ nhớ (in-memory). Nó có thể nhanh hơn MapReduce đến 100 lần trong một số trường hợp. Spark cũng linh hoạt hơn, hỗ trợ cả xử lý theo lô, xử lý tương tác, xử lý thời gian thực và học máy trên cùng một nền tảng. Tuy nhiên, do phụ thuộc nhiều vào RAM, Spark có thể yêu cầu phần cứng đắt tiền hơn và việc quản lý bộ nhớ cũng phức tạp hơn. Vậy khi nào nên chọn Spark thay vì Hadoop? Nếu ưu tiên của bạn là tốc độ, xử lý lặp hoặc phân tích thời gian thực, Spark là lựa chọn hàng đầu. Nếu bạn cần xử lý các công việc theo lô trên tập dữ liệu khổng lồ với ngân sách phần cứng hạn chế và không quá gấp về thời gian, MapReduce vẫn là một giải pháp khả thi.
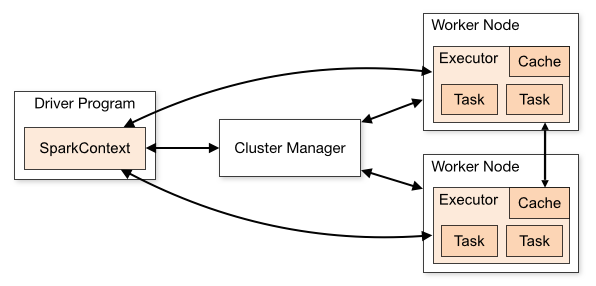
Apache Spark vs Flink và các công cụ khác
Ngoài Hadoop, Apache Flink cũng là một đối thủ đáng gờm của Spark, đặc biệt trong lĩnh vực xử lý dòng dữ liệu (stream processing). Cả Spark và Flink đều là những framework mạnh mẽ, nhưng chúng có triết lý thiết kế khác nhau. Flink được xây dựng từ đầu như một công cụ xử lý dòng dữ liệu thực sự (true streaming), xử lý từng sự kiện một ngay khi nó đến. Điều này mang lại độ trễ cực thấp. Spark Streaming, mặt khác, hoạt động theo cơ chế micro-batching, tức là nó gom dữ liệu thành các lô nhỏ rồi xử lý. Mặc dù cơ chế này cũng cho độ trễ thấp, nhưng về lý thuyết, nó không phải là xử lý thời gian thực “thuần túy” như Flink.
Do đó, Flink thường được ưa chuộng trong các ứng dụng yêu cầu độ trễ cực thấp và tính chính xác cao về mặt thời gian. Ngược lại, Spark có hệ sinh thái trưởng thành hơn, cộng đồng lớn hơn và các API thống nhất cho cả xử lý lô và xử lý dòng, giúp việc phát triển trở nên đơn giản hơn. Về mức độ phổ biến, Spark vẫn chiếm ưu thế do ra đời sớm hơn và có tính đa dụng cao hơn. Lựa chọn giữa Spark và Flink thường phụ thuộc vào yêu cầu cụ thể của bài toán: nếu ứng dụng của bạn tập trung chủ yếu vào xử lý dòng với yêu cầu khắt khe về độ trễ, Flink là lựa chọn tốt. Nếu bạn cần một nền tảng đa năng để giải quyết nhiều loại bài toán dữ liệu khác nhau, Spark sẽ là một lựa chọn an toàn và mạnh mẽ hơn.
Các vấn đề thường gặp khi sử dụng Apache Spark
Vấn đề về quản lý bộ nhớ (Memory Management)
Dù mạnh mẽ, Apache Spark cũng có những thách thức riêng, và vấn đề quản lý bộ nhớ là một trong những điều đau đầu nhất đối với các nhà phát triển. Do cơ chế xử lý trong bộ nhớ, các ứng dụng Spark rất “tham lam” RAM. Lỗi phổ biến nhất mà bạn có thể gặp phải là OutOfMemoryError (OOM). Lỗi này xảy ra khi một Executor không có đủ bộ nhớ để lưu trữ dữ liệu hoặc các đối tượng trung gian trong quá trình tính toán.
Nguyên nhân có thể do dữ liệu bị phân phối không đều (data skew), khiến một vài Executor phải xử lý khối lượng dữ liệu lớn hơn nhiều so với các Executor khác. Hoặc cũng có thể do bạn thực hiện các thao tác tốn nhiều bộ nhớ như collect() một tập dữ liệu lớn về Driver. Để tối ưu, bạn cần cấu hình dung lượng bộ nhớ cho Executor và Driver một cách hợp lý, sử dụng các cơ chế lưu trữ hiệu quả như MEMORY_AND_DISK_SER, và áp dụng kỹ thuật phân vùng (partitioning) lại dữ liệu để phân phối tải đều hơn trên cluster.
Cấu hình và tối ưu hiệu suất Cluster
Việc thiết lập một cluster Spark để đạt hiệu suất tối ưu không phải là chuyện đơn giản. Một cấu hình sai có thể khiến ứng dụng của bạn chạy chậm hơn đáng kể hoặc thậm chí không thể hoàn thành. Một lỗi phổ biến là cấp phát tài nguyên không phù hợp. Ví dụ, cấp phát quá nhiều core cho mỗi Executor có thể gây ra tranh chấp tài nguyên I/O, trong khi cấp phát quá ít lại không tận dụng hết sức mạnh của cluster.
Việc xác định số lượng Executor, dung lượng bộ nhớ và số core cho mỗi Executor là một bài toán cân bằng phụ thuộc vào đặc điểm của ứng dụng và tài nguyên phần cứng có sẵn. Để khắc phục, bạn nên bắt đầu với một cấu hình cơ bản, sau đó sử dụng giao diện web của Spark (Spark UI) để theo dõi hiệu suất, xem xét các chỉ số như thời gian thực thi của các stage, tình trạng sử dụng bộ nhớ, và dữ liệu bị tràn (spill) ra đĩa. Dựa trên những thông tin này, bạn có thể tinh chỉnh các tham số cấu hình dần dần để tìm ra thiết lập tối ưu cho ứng dụng của mình.
Best Practices khi sử dụng Apache Spark
Để khai thác tối đa sức mạnh của Apache Spark, việc áp dụng các phương pháp hay nhất (best practices) là vô cùng quan trọng. Những kinh nghiệm này giúp ứng dụng của bạn chạy nhanh hơn, ổn định hơn và dễ bảo trì hơn.
- Sử dụng cấu hình phù hợp theo nhu cầu xử lý: Đừng sử dụng một cấu hình cho mọi công việc. Hãy phân tích yêu cầu của ứng dụng (lượng dữ liệu, độ phức tạp của thuật toán) để điều chỉnh các tham số như
spark.executor.memory,spark.executor.cores, vàspark.driver.memorycho phù hợp. Việc này giúp tránh lãng phí tài nguyên và tối ưu hóa hiệu suất. - Tối ưu code với DataFrame API thay vì RDD khi có thể: Như đã đề cập, DataFrame API được hưởng lợi từ bộ tối ưu hóa Catalyst của Spark. Do đó, hãy ưu tiên sử dụng DataFrame và Spark SQL. Các thao tác trên DataFrame thường được tối ưu hóa tự động và chạy nhanh hơn đáng kể so với việc bạn tự viết logic xử lý bằng RDD.
- Theo dõi và giám sát tài nguyên cluster thường xuyên: Spark UI là người bạn đồng hành không thể thiếu. Hãy thường xuyên kiểm tra nó để hiểu cách ứng dụng của bạn đang chạy, phát hiện các “nút thắt cổ chai” về hiệu suất, và xem các tác vụ nào đang chiếm nhiều thời gian và tài nguyên nhất.
- Tránh làm việc với dữ liệu không cần thiết để giảm tải hệ thống: Hãy lọc (filter) và chọn (select) dữ liệu càng sớm càng tốt trong quy trình xử lý của bạn. Việc loại bỏ các hàng và cột không cần thiết ngay từ đầu sẽ làm giảm đáng kể lượng dữ liệu cần được di chuyển qua mạng và xử lý, giúp tăng tốc độ đáng kể. Ví dụ, hãy đặt lệnh
filter()trước lệnhmap()hoặcjoin().
Conclusion
Qua bài viết, chúng ta đã cùng nhau khám phá một cách toàn diện về Apache Spark. Từ định nghĩa là một framework xử lý dữ liệu phân tán tốc độ cao, cấu trúc thông minh với các thành phần như Spark Core, SQL, Streaming, MLlib, đến những ưu điểm vượt trội về tốc độ và sự linh hoạt. Spark đã chứng tỏ vai trò không thể thiếu trong kỷ nguyên dữ liệu lớn, giúp các doanh nghiệp giải quyết những bài toán phức tạp từ phân tích thời gian thực, học máy cho đến xử lý dữ liệu IoT.
Vai trò của Apache Spark ngày càng trở nên quan trọng khi dữ liệu tiếp tục bùng nổ. Khả năng xử lý nhanh và hiệu quả của nó là chìa khóa giúp biến dữ liệu thô thành những thông tin chi tiết có giá trị, tạo ra lợi thế cạnh tranh bền vững. AZWEB hy vọng bài viết này đã cung cấp cho bạn một cái nhìn rõ ràng và hữu ích. Đừng ngần ngại bắt đầu hành trình chinh phục Spark. Các bước tiếp theo bạn có thể thực hiện là tìm hiểu sâu hơn qua các tài liệu chính thức, cài đặt thử nghiệm trên máy cá nhân và áp dụng vào các dự án với dữ liệu mẫu. Chúc bạn thành công trên con đường khai phá sức mạnh của dữ liệu!