Trong thế giới phát triển phần mềm và lập trình, hiệu suất và tự động hóa là hai yếu tố then chốt quyết định sự thành công của một dự án. Bạn đã bao giờ gặp phải tình huống các công việc cứ ùn tắc, phải chờ đợi nhau một cách tuần tự, gây lãng phí thời gian và tiềm ẩn nhiều rủi ro lỗi? Đây là một vấn đề rất phổ biến khi các quy trình không được tối ưu hóa. Để giải quyết thách thức này, một khái niệm cực kỳ mạnh mẽ đã ra đời và được áp dụng rộng rãi: đó chính là “pipeline“.
Pipeline, hay “đường ống”, không chỉ là một thuật ngữ kỹ thuật khô khan. Hãy tưởng tượng nó như một dây chuyền lắp ráp tự động trong một nhà máy hiện đại. Thay vì một công nhân phải hoàn thành tất cả các công đoạn từ đầu đến cuối, mỗi công nhân (hoặc một nhóm) sẽ chuyên trách một giai đoạn duy nhất và chuyển sản phẩm cho người tiếp theo. Giải pháp này giúp tối ưu hóa toàn bộ quy trình, tăng tốc độ sản xuất và dễ dàng phát hiện lỗi ở từng khâu. Trong lập trình, pipeline hoạt động với nguyên lý tương tự, biến một chuỗi công việc phức tạp thành một luồng xử lý mượt mà và hiệu quả.
Bài viết này của AZWEB sẽ là kim chỉ nam giúp bạn hiểu rõ từ A-Z về pipeline. Chúng ta sẽ cùng nhau khám phá định nghĩa pipeline là gì, cách nó hoạt động, những lợi ích vượt trội mà nó mang lại, và các ứng dụng thực tế phổ biến nhất hiện nay. Hãy cùng bắt đầu hành trình giải mã công cụ mạnh mẽ này nhé!
Định nghĩa Pipeline trong lập trình và phát triển phần mềm
Để hiểu rõ sức mạnh của pipeline, trước tiên chúng ta cần nắm vững khái niệm cốt lõi và cơ chế vận hành của nó. Đây là nền tảng giúp bạn áp dụng pipeline một cách hiệu quả vào các dự án của mình.
Khái niệm Pipeline là gì?
Trong ngữ cảnh lập trình và phát triển phần mềm, pipeline (đường ống) là một mô hình kiến trúc bao gồm một chuỗi các thành phần xử lý dữ liệu được sắp xếp nối tiếp nhau. Trong mô hình này, đầu ra (output) của một thành phần sẽ trở thành đầu vào (input) cho thành phần kế tiếp ngay sau nó. Mỗi thành phần trong chuỗi được gọi là một “giai đoạn” (stage) và thực hiện một tác vụ cụ thể.

Mối liên hệ giữa pipeline và quy trình xử lý công việc tuần tự rất chặt chẽ, nhưng cũng có sự khác biệt quan trọng. Thay vì thực hiện toàn bộ công việc trong một bước duy nhất, pipeline chia nhỏ quy trình thành nhiều bước độc lập. Điều này cho phép các giai đoạn có thể hoạt động song song trên các đơn vị dữ liệu khác nhau, giống như trên một dây chuyền lắp ráp. Khi giai đoạn đầu tiên xử lý xong một mục và chuyển nó sang giai đoạn thứ hai, nó có thể ngay lập tức bắt đầu xử lý mục tiếp theo mà không cần chờ toàn bộ quy trình kết thúc.
Cách hoạt động của pipeline
Hoạt động của pipeline dựa trên một luồng dữ liệu (data flow) chảy qua các giai đoạn xử lý một cách tuần tự. Hãy hình dung một quy trình đơn giản gồm ba giai đoạn: A, B, và C.
1. Giai đoạn A (Input): Dữ liệu hoặc công việc đầu vào được đưa vào giai đoạn đầu tiên của pipeline. Giai đoạn A thực hiện nhiệm vụ của mình (ví dụ: đọc dữ liệu từ tệp, xác thực thông tin).
2. Giai đoạn B (Processing): Ngay khi giai đoạn A hoàn thành và tạo ra kết quả, kết quả này sẽ được chuyển ngay lập tức đến giai đoạn B. Giai đoạn B tiếp nhận và bắt đầu xử lý (ví dụ: chuyển đổi định dạng dữ liệu, thực hiện tính toán).
3. Giai đoạn C (Output): Tương tự, đầu ra của giai đoạn B trở thành đầu vào cho giai đoạn C. Giai đoạn C thực hiện tác vụ cuối cùng (ví dụ: lưu kết quả vào cơ sở dữ liệu, hiển thị cho người dùng).

Điểm mấu chốt tạo nên hiệu quả của pipeline là khả năng xử lý gối đầu. Trong khi giai đoạn B đang xử lý mục dữ liệu thứ nhất, giai đoạn A đã có thể bắt đầu xử lý mục dữ liệu thứ hai. Tương tự, khi giai đoạn C xử lý mục đầu tiên, giai đoạn B xử lý mục thứ hai và giai đoạn A xử lý mục thứ ba. Luồng công việc liên tục này giúp tối đa hóa việc sử dụng tài nguyên và giảm đáng kể thời gian chờ đợi, mang lại hiệu suất vượt trội so với việc xử lý từng mục một từ đầu đến cuối.
Lợi ích của việc sử dụng pipeline trong quản lý công việc và tối ưu hiệu suất
Việc áp dụng pipeline không chỉ là một thay đổi về mặt kỹ thuật mà còn mang lại những lợi ích to lớn về hiệu suất, độ tin cậy và khả năng quản lý. Đây là lý do tại sao pipeline trở thành một chuẩn mực trong phát triển phần mềm hiện đại.
Tăng hiệu quả xử lý và tiết kiệm thời gian
Lợi ích rõ ràng nhất của pipeline là khả năng tăng tốc độ xử lý một cách đáng kể. Bằng cách chia nhỏ một tác vụ lớn thành nhiều giai đoạn nhỏ hơn và cho phép chúng hoạt động song song trên các luồng dữ liệu khác nhau, pipeline loại bỏ thời gian chết trong hệ thống. Thay vì phải chờ đợi toàn bộ quy trình hoàn thành với một đơn vị dữ liệu trước khi bắt đầu với đơn vị tiếp theo, các giai đoạn có thể làm việc gối đầu lên nhau.
Ví dụ, trong một quy trình xử lý video, các giai đoạn có thể là: Tải lên -> Nén video -> Thêm watermark -> Xuất bản. Với pipeline, ngay khi một video được tải lên xong và chuyển sang giai đoạn nén, hệ thống có thể bắt đầu quá trình tải lên cho video tiếp theo. Điều này giúp hệ thống xử lý được nhiều công việc hơn trong cùng một khoảng thời gian, nâng cao năng suất tổng thể và mang lại trải nghiệm nhanh hơn cho người dùng cuối.
Giảm thiểu lỗi và tối ưu quản lý tài nguyên
Pipeline giúp cải thiện độ tin cậy của hệ thống bằng cách cô lập các giai đoạn xử lý. Mỗi giai đoạn chỉ chịu trách nhiệm cho một tác vụ duy nhất và cụ thể. Khi có lỗi xảy ra, bạn có thể nhanh chóng xác định chính xác giai đoạn nào đang gặp vấn đề thay vì phải dò xét toàn bộ một quy trình phức tạp. Việc sửa lỗi và kiểm thử cũng trở nên đơn giản hơn vì bạn chỉ cần tập trung vào một module nhỏ.
Bên cạnh đó, pipeline cho phép phân bổ tài nguyên một cách hợp lý hơn. Các giai đoạn đòi hỏi nhiều tài nguyên (như CPU hoặc bộ nhớ) có thể được chạy trên các máy chủ mạnh mẽ hơn, trong khi các giai đoạn nhẹ nhàng hơn có thể chạy trên các tài nguyên tiết kiệm hơn. Mô hình này giúp tránh tình trạng một tác vụ nặng làm tê liệt toàn bộ hệ thống. Bằng cách kiểm soát luồng công việc qua từng bước, pipeline đảm bảo rằng tài nguyên được sử dụng một cách tối ưu, tránh lãng phí và quá tải.
Các ứng dụng phổ biến của pipeline trong phát triển phần mềm
Nhờ tính linh hoạt và hiệu quả, pipeline đã trở thành một phần không thể thiếu trong nhiều lĩnh vực của công nghệ. Dưới đây là hai trong số những ứng dụng phổ biến và có tầm ảnh hưởng lớn nhất hiện nay.
Continuous Integration/Continuous Deployment (CI/CD)
CI/CD là một trong những ứng dụng tiêu biểu và mạnh mẽ nhất của pipeline trong phát triển phần mềm. Đây là một phương pháp tự động hóa quy trình đưa phần mềm từ giai đoạn viết mã đến tay người dùng cuối. Pipeline trong CI/CD hoạt động như một “dây chuyền lắp ráp” tự động cho mã nguồn. Tìm hiểu về CI/CD.
Một pipeline CI/CD điển hình bao gồm các giai đoạn sau:
- Build (Xây dựng): Khi lập trình viên đẩy mã nguồn mới lên kho chứa (như GitHub hoặc GitLab), pipeline sẽ tự động kích hoạt. Giai đoạn đầu tiên là biên dịch mã nguồn thành một phiên bản phần mềm có thể chạy được.
- Test (Kiểm thử): Sau khi xây dựng thành công, phiên bản mới sẽ được đưa qua hàng loạt các bài kiểm thử tự động (unit test, integration test) để đảm bảo chất lượng và không gây ra lỗi mới.
- Deploy (Triển khai): Nếu tất cả các bài kiểm thử đều vượt qua, pipeline sẽ tự động triển khai phiên bản mới lên một môi trường (ví dụ: môi trường thử nghiệm – staging, hoặc môi trường sản phẩm – production).
Nhờ có pipeline CI/CD, các nhóm phát triển có thể phát hành phần mềm nhanh hơn, thường xuyên hơn và với độ tin cậy cao hơn. Các thương hiệu lớn như Netflix hay Amazon triển khai mã nguồn hàng nghìn lần mỗi ngày chính là nhờ vào sức mạnh của các hệ thống pipeline CI/CD tinh vi. Công cụ như Jenkins giúp tự động hóa xây dựng và triển khai phần mềm hiệu quả.
Xử lý dữ liệu và Machine Learning Pipeline
Trong lĩnh vực dữ liệu lớn (Big Data) và học máy (Machine Learning), pipeline đóng vai trò xương sống để xử lý và biến đổi một khối lượng dữ liệu khổng lồ thành những thông tin chi tiết có giá trị hoặc các mô hình dự đoán thông minh.
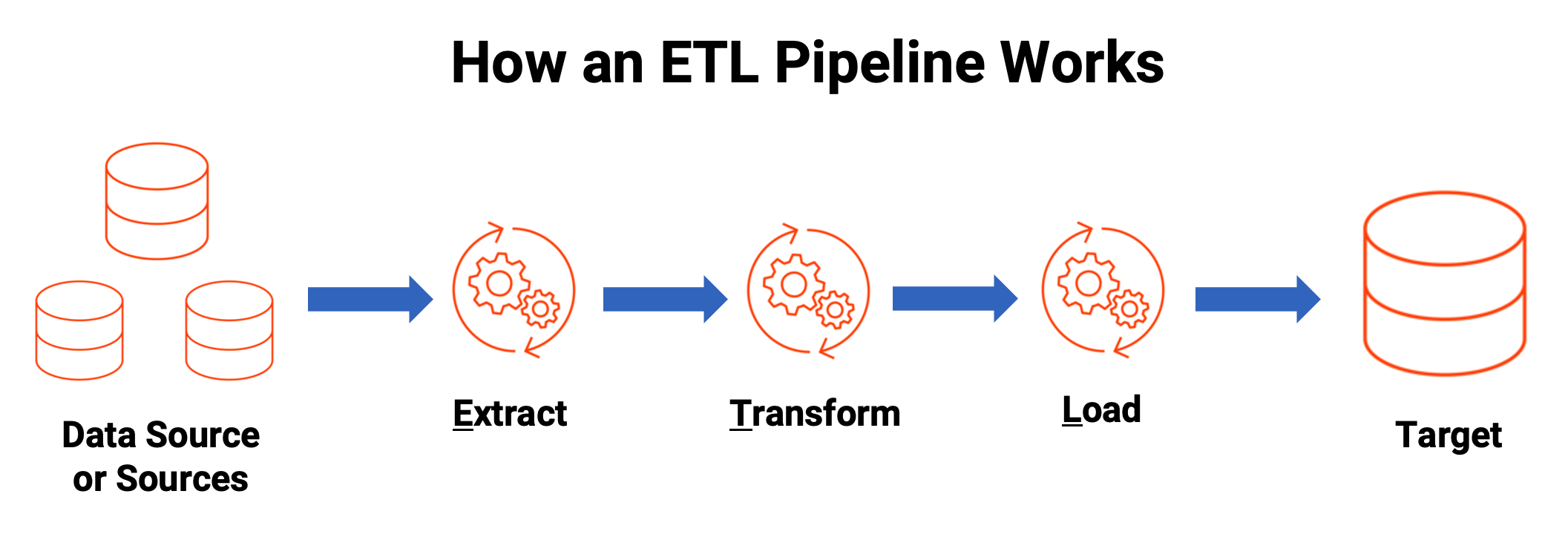
Một pipeline xử lý dữ liệu (ETL/ELT pipeline) thường bao gồm các giai đoạn:
- Extract (Trích xuất): Thu thập dữ liệu thô từ nhiều nguồn khác nhau (cơ sở dữ liệu, API, file log).
- Transform (Biến đổi): Làm sạch, chuẩn hóa, kết hợp và định dạng lại dữ liệu để phù hợp cho việc phân tích.
- Load (Tải): Tải dữ liệu đã qua xử lý vào một kho dữ liệu (Data Warehouse) hoặc hồ dữ liệu (Data Lake).

Tương tự, trong Machine Learning, pipeline (MLOps) tự động hóa quy trình xây dựng và triển khai mô hình:
- Chuẩn bị dữ liệu: Thu thập và tiền xử lý dữ liệu.
- Huấn luyện mô hình: Sử dụng dữ liệu đã chuẩn bị để huấn luyện một mô hình học máy.
- Đánh giá mô hình: Kiểm tra hiệu suất của mô hình với một tập dữ liệu mới.
- Triển khai mô hình: Nếu mô hình đạt yêu cầu, nó sẽ được triển khai để đưa ra các dự đoán thực tế.
Những pipeline này giúp các nhà khoa học dữ liệu và kỹ sư học máy tiết kiệm thời gian, đảm bảo tính nhất quán và cho phép họ dễ dàng thử nghiệm, cập nhật mô hình một cách có hệ thống.
Ví dụ minh họa pipeline trong lập trình thực tế
Lý thuyết sẽ trở nên dễ hiểu hơn rất nhiều khi được áp dụng vào các ví dụ cụ thể. Hãy cùng AZWEB xem xét hai ví dụ thực tế về cách pipeline được triển khai, từ một tác vụ đơn giản đến một quy trình phát triển phần mềm phức tạp.
Ví dụ pipeline đơn giản trong xử lý chuỗi dữ liệu
Hãy tưởng tượng bạn có một danh sách các bình luận của người dùng và cần thực hiện một chuỗi các thao tác để làm sạch chúng trước khi phân tích. Thay vì viết một hàm lớn và phức tạp, chúng ta có thể tạo một pipeline đơn giản.
Giả sử đầu vào là chuỗi: ” AZWEB là Dịch Vụ Thiết kế Website TUYỆT VỜI! “
Pipeline của chúng ta sẽ có 3 giai đoạn:
- Giai đoạn 1: Loại bỏ khoảng trắng thừa. Giai đoạn này nhận chuỗi gốc và cắt bỏ các khoảng trắng ở đầu và cuối.
- Input: ” AZWEB là Dịch Vụ Thiết kế Website TUYỆT VỜI! “
- Output: “AZWEB là Dịch Vụ Thiết kế Website TUYỆT VỜI!”
- Giai đoạn 2: Chuyển thành chữ thường. Đầu ra của giai đoạn 1 được chuyển tiếp đến đây và biến đổi thành chữ thường để chuẩn hóa dữ liệu.
- Input: “AZWEB là Dịch Vụ Thiết kế Website TUYỆT VỜI!”
- Output: “azweb là dịch vụ thiết kế website tuyệt vời!”
- Giai đoạn 3: Loại bỏ dấu câu. Đầu ra của giai đoạn 2 được đưa vào đây để loại bỏ các ký tự đặc biệt.
- Input: “azweb là dịch vụ thiết kế website tuyệt vời!”
- Output: “azweb là dịch vụ thiết kế website tuyệt vời”
Bằng cách này, mỗi giai đoạn chỉ làm một việc duy nhất, giúp mã nguồn dễ đọc, dễ kiểm thử và dễ tái sử dụng. Nếu sau này bạn muốn thêm một bước mới, ví dụ như kiểm tra lỗi chính tả, bạn chỉ cần chèn một giai đoạn mới vào pipeline mà không ảnh hưởng đến các giai đoạn khác.
Ví dụ pipeline trong CI/CD với công cụ Jenkins hoặc GitLab CI
Đây là một ví dụ nâng cao hơn nhưng rất phổ biến trong các công ty công nghệ. Hãy xem một pipeline tự động hóa triển khai website được định nghĩa trong tệp `.gitlab-ci.yml` của GitLab CI.
Khi một lập trình viên đẩy code mới lên nhánh `main`, pipeline sẽ tự động chạy:
stages:
- build
- test
- deploy
build_job:
stage: build
script:
- echo "Đang xây dựng ứng dụng..."
- npm install
- npm run build
test_job:
stage: test
script:
- echo "Đang chạy kiểm thử..."
- npm test
deploy_job:
stage: deploy
script:
- echo "Đang triển khai lên máy chủ..."
- scp -r ./build/* user@your-server:/var/www/html
only:
- main
Hướng dẫn ngắn về pipeline này:
- Giai đoạn `build` (Xây dựng): GitLab Runner sẽ thực thi các lệnh trong `build_job`. Nó cài đặt các thư viện cần thiết (`npm install`) và biên dịch mã nguồn (`npm run build`) để tạo ra các tệp tĩnh cho website.
- Giai đoạn `test` (Kiểm thử): Nếu giai đoạn `build` thành công, `test_job` sẽ được kích hoạt. Nó chạy các bài kiểm thử tự động (`npm test`) để đảm bảo code mới không phá vỡ các chức năng hiện có.
- Giai đoạn `deploy` (Triển khai): Nếu kiểm thử thành công và thay đổi được đẩy lên nhánh `main`, `deploy_job` sẽ thực thi. Nó sao chép các tệp đã được xây dựng ở giai đoạn `build` vào máy chủ sản phẩm, hoàn tất quá trình cập nhật website.

Pipeline này đảm bảo mọi thay đổi trên website đều được xây dựng, kiểm thử và triển khai một cách tự động, nhất quán và an toàn, giảm thiểu sai sót do con người và tăng tốc độ phát triển. Đây là ví dụ thực tế hóa pipeline CI/CD với công cụ được đề cập như Jenkins và GitLab CI.
So sánh pipeline với các phương pháp xử lý công việc khác
Để đánh giá đúng giá trị của pipeline, việc đặt nó lên bàn cân so sánh với các kiến trúc xử lý khác là rất cần thiết. Điều này giúp chúng ta hiểu khi nào nên và không nên sử dụng pipeline.
Pipeline vs xử lý tuần tự truyền thống
Đây là phép so sánh cơ bản nhất, làm nổi bật lý do pipeline ra đời.
- Xử lý tuần tự truyền thống (Sequential Processing):
Trong mô hình này, một tác vụ phải được hoàn thành 100% trước khi tác vụ tiếp theo được bắt đầu. Giống như một người đầu bếp phải tự mình đi chợ, sơ chế, nấu nướng, và dọn dẹp cho một món ăn trước khi bắt đầu chuẩn bị cho món tiếp theo.
- Ưu điểm: Đơn giản để thiết kế và gỡ lỗi vì luồng đi là tuyến tính và dễ đoán.
- Nhược điểm: Rất không hiệu quả, lãng phí tài nguyên. Toàn bộ hệ thống phải chờ đợi một quy trình duy nhất, gây ra độ trễ lớn, đặc biệt với các tác vụ tốn thời gian.
- Phạm vi áp dụng: Phù hợp cho các script đơn giản, các tác vụ không yêu cầu hiệu suất cao hoặc không có tính lặp lại.
- Pipeline:
Như đã phân tích, pipeline chia công việc thành các giai đoạn và xử lý gối đầu. Giống như một dây chuyền nhà bếp, nơi nhiều đầu bếp cùng làm việc: một người sơ chế, người kia nấu, người khác trang trí. Khi người sơ chế làm xong nguyên liệu cho món 1, họ chuyển cho người nấu và ngay lập tức sơ chế nguyên liệu cho món 2.
- Ưu điểm: Hiệu suất cao, tận dụng tối đa tài nguyên, giảm thời gian chờ. Dễ dàng mở rộng và bảo trì nhờ tính module hóa.
- Nhược điểm: Phức tạp hơn trong thiết kế ban đầu. Cần quản lý luồng dữ liệu giữa các giai đoạn và xử lý các vấn đề như tắc nghẽn.
- Phạm vi áp dụng: Lý tưởng cho các hệ thống xử lý luồng dữ liệu, CI/CD, ETL, xử lý hình ảnh/video, nơi các tác vụ có thể được chia nhỏ và lặp lại.

Pipeline vs event-driven và asynchronous processing
Đây là những kiến trúc hiện đại và đôi khi có thể bị nhầm lẫn với pipeline.
- Pipeline:
Đặc điểm chính của pipeline là cấu trúc tuyến tính và có thứ tự. Dữ liệu chảy theo một luồng cố định từ giai đoạn này sang giai đoạn tiếp theo. Mối quan hệ giữa các giai đoạn là chặt chẽ và phụ thuộc trực tiếp vào nhau.
- Xử lý bất đồng bộ (Asynchronous Processing):
Đây là một khái niệm rộng hơn. Một tác vụ bất đồng bộ được khởi chạy và chương trình chính không cần chờ nó hoàn thành mà có thể tiếp tục công việc khác. Pipeline là một dạng cụ thể của xử lý bất đồng bộ, nhưng không phải tất cả xử lý bất đồng bộ đều là pipeline. Ví dụ, bạn có thể khởi chạy 5 tác vụ nén ảnh cùng một lúc mà không cần chúng phải theo một thứ tự nào cả.
- Kiến trúc hướng sự kiện (Event-Driven Architecture):
Trong kiến trúc này, các thành phần của hệ thống giao tiếp với nhau thông qua việc phát và lắng nghe các “sự kiện”. Một thành phần (publisher) phát ra một sự kiện (ví dụ: “Người dùng đã đăng ký”), và các thành phần khác (subscribers) đã đăng ký lắng nghe sự kiện đó sẽ thực hiện hành động của mình. Luồng hoạt động không tuyến tính mà phụ thuộc vào các sự kiện xảy ra. Mối quan hệ giữa các thành phần là lỏng lẻo.
- Điểm khác biệt chính: Pipeline có luồng đi cố định và được định trước, trong khi kiến trúc hướng sự kiện có luồng đi linh hoạt và phụ thuộc vào sự kiện. Pipeline phù hợp cho các quy trình có các bước rõ ràng, còn kiến trúc hướng sự kiện phù hợp cho các hệ thống phức tạp cần sự découplage (ít phụ thuộc) giữa các dịch vụ (microservices).
Các vấn đề thường gặp và cách khắc phục
Mặc dù pipeline rất mạnh mẽ, việc xây dựng và vận hành chúng không phải lúc nào cũng suôn sẻ. Nhận biết trước các vấn đề phổ biến sẽ giúp bạn thiết kế những pipeline bền vững và hiệu quả hơn.
Pipeline bị nghẽn cổ chai (bottleneck)
Đây là vấn đề kinh điển nhất trong các hệ thống pipeline. Một “cổ chai” xảy ra khi một giai đoạn trong pipeline xử lý chậm hơn đáng kể so với các giai đoạn khác, khiến toàn bộ luồng công việc bị ùn tắc và chờ đợi tại điểm đó. Giống như một nút thắt cổ chai, nó làm giảm thông lượng của cả hệ thống.
- Nguyên nhân:
- Giai đoạn đó thực hiện một tác vụ tính toán quá nặng (ví dụ: render video, huấn luyện mô hình ML).
- Tài nguyên cấp cho giai đoạn đó không đủ (ít CPU, RAM hoặc I/O chậm).
- Giai đoạn đó phụ thuộc vào một dịch vụ bên ngoài có tốc độ phản hồi chậm.
- Giải pháp khắc phục:
- Tối ưu hóa giai đoạn bị nghẽn: Xem xét lại mã nguồn hoặc thuật toán của giai đoạn đó để cải thiện hiệu suất.
- Tăng cường tài nguyên: Cấp thêm CPU, bộ nhớ hoặc sử dụng ổ cứng nhanh hơn cho giai đoạn đó.
- Thực thi song song (Parallelization): Nếu có thể, hãy chạy nhiều phiên bản của giai đoạn bị nghẽn cùng một lúc để xử lý nhiều đơn vị dữ liệu song song. Ví dụ, thay vì một máy nén video, hãy chạy 5 máy nén video.
- Chia nhỏ giai đoạn: Nếu một giai đoạn làm quá nhiều việc, hãy thử tách nó thành hai hoặc nhiều giai đoạn nhỏ hơn.
Xử lý lỗi và rollback trong pipeline
Khi một giai đoạn trong pipeline gặp lỗi, điều gì sẽ xảy ra? Nếu không có cơ chế xử lý lỗi tốt, pipeline có thể dừng lại, để lại dữ liệu ở trạng thái không nhất quán và yêu cầu can thiệp thủ công.
- Vấn đề:
- Lỗi ở một giai đoạn giữa chừng có thể làm hỏng toàn bộ quy trình.
- Khó khăn trong việc quay trở lại trạng thái ổn định trước khi lỗi xảy ra (rollback).
- Thiếu thông tin để chẩn đoán nguyên nhân lỗi.
- Cách thiết kế để xử lý lỗi hiệu quả:
- Thiết kế các giai đoạn có tính Idempotent: Một tác vụ idempotent là tác vụ mà việc thực hiện nó nhiều lần cho cùng một đầu vào đều cho ra cùng một kết quả. Điều này cho phép bạn an toàn chạy lại một giai đoạn bị lỗi mà không gây ra tác dụng phụ.
- Triển khai cơ chế thử lại (Retry Mechanism): Đối với các lỗi tạm thời (ví dụ: mất kết nối mạng), hãy tự động cho phép giai đoạn đó thử lại một vài lần trước khi báo lỗi hoàn toàn.
- Chiến lược Rollback tự động: Trong pipeline CI/CD, nếu giai đoạn triển khai (deploy) thất bại, hãy thiết kế một quy trình tự động để quay trở lại phiên bản ổn định trước đó.
- Dead Letter Queue (DLQ): Đối với các đơn vị dữ liệu không thể xử lý được, thay vì làm pipeline bị dừng, hãy chuyển chúng vào một “hàng đợi chờ xử lý” (DLQ). Điều này cho phép pipeline tiếp tục hoạt động, và bạn có thể phân tích và xử lý các trường hợp lỗi này sau.
- Logging và Monitoring: Ghi lại log chi tiết ở mỗi giai đoạn và thiết lập giám sát để nhận được cảnh báo ngay khi có sự cố.
Những thực hành tốt nhất khi xây dựng pipeline
Để xây dựng một pipeline không chỉ hoạt động mà còn hiệu quả, dễ bảo trì và mở rộng, việc tuân thủ các nguyên tắc và thực hành tốt nhất là vô cùng quan trọng. Dưới đây là những lời khuyên từ AZWEB giúp bạn tạo ra các pipeline đẳng cấp chuyên nghiệp.
-
Lập kế hoạch rõ ràng và phân chia bước hợp lý: Trước khi viết bất kỳ dòng mã nào, hãy vẽ ra sơ đồ luồng pipeline của bạn. Xác định rõ ràng từng giai đoạn, trách nhiệm của nó, và dữ liệu đầu vào/đầu ra. Hãy tuân thủ Nguyên tắc Trách nhiệm Đơn (Single Responsibility Principle): mỗi giai đoạn chỉ nên làm một việc và làm thật tốt. Điều này giúp pipeline trở nên module hóa, dễ hiểu và dễ thay thế.
-
Áp dụng tự động hóa kiểm thử và deploy sớm: Đây là linh hồn của CI/CD. Kiểm thử tự động (unit test, integration test, end-to-end test) phải là một phần không thể thiếu trong pipeline của bạn. Chúng giúp phát hiện lỗi sớm, ngay sau khi mã nguồn được thay đổi, đảm bảo chất lượng và sự tự tin khi triển khai. Tự động hóa việc triển khai giúp loại bỏ sai sót của con người và tăng tốc độ phát hành sản phẩm.
-
Giám sát và logging chi tiết xuyên suốt pipeline: Bạn không thể cải thiện thứ mà bạn không thể đo lường. Hãy tích hợp các công cụ giám sát (monitoring) và ghi log (logging) vào mọi giai đoạn của pipeline. Log chi tiết giúp bạn gỡ lỗi nhanh chóng khi có sự cố. Các chỉ số giám sát (như thời gian thực thi mỗi giai đoạn, tỷ lệ lỗi, thông lượng) cung cấp cái nhìn sâu sắc về hiệu suất và giúp bạn xác định các điểm nghẽn cổ chai.
-
Tránh quá tải bước xử lý, ưu tiên modular và tái sử dụng: Đừng cố nhồi nhét quá nhiều logic vào một giai đoạn duy nhất. Các giai đoạn quá lớn và phức tạp sẽ khó bảo trì, khó kiểm thử và dễ trở thành điểm nghẽn. Thay vào đó, hãy giữ cho các giai đoạn nhỏ gọn và tập trung. Thiết kế các giai đoạn theo hướng modular để có thể tái sử dụng chúng trong các pipeline khác, giúp tiết kiệm thời gian và công sức phát triển.
-
Đảm bảo khả năng phục hồi và xử lý lỗi: Một pipeline tốt không phải là một pipeline không bao giờ lỗi, mà là một pipeline có khả năng phục hồi khi lỗi xảy ra. Hãy tích hợp các cơ chế như thử lại tự động (retry) cho các lỗi tạm thời, và chiến lược rollback an toàn để quay về trạng thái ổn định nếu có sự cố nghiêm trọng. Sử dụng Dead Letter Queues để cô lập các dữ liệu gây lỗi mà không làm gián đoạn toàn bộ luồng.
Kết luận
Qua bài viết chi tiết này, chúng ta đã cùng nhau thực hiện một hành trình khám phá toàn diện về pipeline trong lập trình và phát triển phần mềm. Từ định nghĩa cơ bản “pipeline là gì“, cách nó vận hành như một dây chuyền sản xuất hiệu quả, cho đến những lợi ích không thể phủ nhận về năng suất và độ tin cậy, pipeline đã chứng tỏ vai trò xương sống trong các quy trình công nghệ hiện đại. Chúng ta đã thấy sức mạnh của nó qua các ứng dụng thực tế như CI/CD trong phát triển phần mềm hay xử lý dữ liệu lớn và học máy.
Việc áp dụng pipeline không chỉ giúp tối ưu hóa quy trình làm việc, tiết kiệm thời gian, mà còn là một bước đi chiến lược để giảm thiểu rủi ro, nâng cao chất lượng sản phẩm và tăng khả năng cạnh tranh. Bằng cách chia nhỏ công việc phức tạp thành các giai đoạn độc lập, dễ quản lý, bạn và đội nhóm của mình có thể phát triển nhanh hơn, an toàn hơn và hiệu quả hơn.
AZWEB hy vọng rằng những kiến thức này sẽ là nền tảng vững chắc để bạn tự tin ứng dụng pipeline vào các dự án của mình. Đừng ngần ngại bắt đầu! Bước tiếp theo cho bạn chính là tìm hiểu các công cụ hỗ trợ xây dựng pipeline mạnh mẽ như Jenkins, GitLab CI, AWS CodePipeline, hoặc Apache Airflow và bắt tay vào thực hành với một dự án nhỏ. Con đường tối ưu hóa hiệu suất và tự động hóa đang chờ bạn ở phía trước.