Bạn đã từng nghe về “piping” nhưng chưa rõ cách nó hoạt động trong Bash là gì? Đây là một khái niệm quen thuộc với những người làm việc thường xuyên trên môi trường Linux. Tuy nhiên, việc kết nối đầu ra của một lệnh với đầu vào của một lệnh khác là kỹ năng cơ bản nhưng nhiều người mới vẫn còn lúng túng. Nếu không nắm vững, bạn có thể gặp khó khăn trong việc xử lý dữ liệu và tự động hóa các tác vụ quản trị hệ thống. Bài viết này sẽ giải thích chi tiết về piping, từ khái niệm cơ bản đến cách sử dụng và các ứng dụng thực tiễn. Chúng ta sẽ cùng nhau khám phá tổng quan về Bash, cách dùng piping qua các ví dụ cụ thể, các mẹo tối ưu và cách khắc phục lỗi thường gặp.
Tổng quan về Bash và vai trò của kỹ thuật piping
Để hiểu rõ về piping, trước tiên chúng ta cần làm quen với môi trường mà nó hoạt động: Bash. Đây là nền tảng cho mọi thao tác dòng lệnh mạnh mẽ trên Linux.
Bash là gì và vai trò trong Linux
Bash, viết tắt của “Bourne Again SHell,” là một trình thông dịch dòng lệnh (command-line interpreter) và cũng là một ngôn ngữ kịch bản. Nó là shell mặc định trên hầu hết các bản phân phối Linux là gì và macOS. Về cơ bản, Bash là cầu nối cho phép bạn giao tiếp trực tiếp với nhân hệ điều hành thông qua các lệnh văn bản. Thay vì nhấp chuột vào giao diện đồ họa, bạn gõ lệnh để yêu cầu hệ thống thực hiện một tác vụ cụ thể.

Vai trò của Bash trong Linux là vô cùng quan trọng. Nó không chỉ dùng để chạy các lệnh đơn lẻ mà còn cung cấp các tính năng lập trình mạnh mẽ như biến, vòng lặp, và cấu trúc điều kiện. Nhờ đó, các quản trị viên hệ thống có thể viết các kịch bản (scripts) để tự động hóa những công việc lặp đi lặp lại. Các công việc này có thể là sao lưu dữ liệu, giám sát tài nguyên hệ thống, hoặc quản lý người dùng một cách hiệu quả.
Bash trao cho bạn quyền kiểm soát hệ thống một cách linh hoạt và chi tiết. Việc thành thạo Bash là một kỹ năng không thể thiếu đối với bất kỳ ai muốn làm việc chuyên sâu với Linux, từ nhà phát triển phần mềm đến các chuyên gia bảo mật.
Piping trong Bash là gì?
Piping là một trong những tính năng mạnh mẽ và thanh lịch nhất của Bash. Khái niệm này cho phép bạn lấy đầu ra (output) tiêu chuẩn của một lệnh và chuyển nó trực tiếp làm đầu vào (input) tiêu chuẩn cho một lệnh khác. Kỹ thuật này được thực hiện bằng cách sử dụng dấu sổ dọc `|`, còn được gọi là ký tự “pipe”.
.webp)
Hãy tưởng tượng một dây chuyền lắp ráp trong nhà máy. Mỗi công nhân (một lệnh) thực hiện một nhiệm vụ cụ thể rồi chuyển sản phẩm cho công nhân tiếp theo. Unix là gì và Linux là gì cũng dựa trên triết lý này. Piping trong Bash hoạt động tương tự: dữ liệu được xử lý tuần tự qua một chuỗi các lệnh, mỗi lệnh thực hiện một bước tinh chỉnh hoặc lọc dữ liệu trước khi chuyển sang bước tiếp theo.
Ví dụ, thay vì lưu kết quả của một lệnh vào một tệp tạm thời rồi sau đó dùng một lệnh khác để đọc tệp đó, piping cho phép bạn kết nối chúng trực tiếp. Điều này không chỉ giúp tiết kiệm không gian lưu trữ mà còn làm cho chuỗi lệnh của bạn trở nên ngắn gọn, dễ đọc và hiệu quả hơn rất nhiều. Đây chính là triết lý cốt lõi của Unix/Linux: mỗi công cụ làm tốt một việc và kết hợp chúng lại với nhau để giải quyết các vấn đề phức tạp.
Cách sử dụng kỹ thuật piping trong Bash
Nắm được khái niệm cơ bản là bước đầu tiên. Giờ hãy cùng đi sâu vào cú pháp và các ví dụ thực tế để bạn có thể tự tin áp dụng kỹ thuật piping vào công việc hàng ngày.
Cách truyền đầu ra làm đầu vào
Cú pháp để sử dụng piping vô cùng đơn giản. Bạn chỉ cần đặt dấu `|` giữa hai lệnh. Lệnh ở bên trái dấu `|` sẽ thực thi trước, và toàn bộ đầu ra của nó sẽ được chuyển hướng để làm đầu vào cho lệnh ở bên phải. Cú pháp chung là: `lenh_1 | lenh_2`.

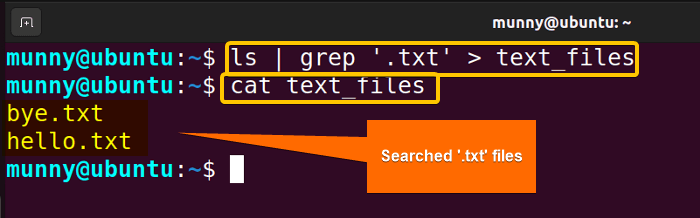
Hãy xem một ví dụ kinh điển để hiểu rõ hơn. Giả sử bạn muốn liệt kê tất cả các tệp trong thư mục hiện tại và chỉ hiển thị những tệp có đuôi là “.txt”.
Lệnh để liệt kê tệp chi tiết là `ls -l`. Đầu ra của nó sẽ là một danh sách dài các tệp và thư mục. Bây giờ, chúng ta muốn lọc danh sách này. Lệnh `grep “.txt”` được dùng để tìm kiếm các dòng chứa chuỗi “.txt”. Bằng cách kết hợp chúng, ta có lệnh: `ls -l | grep “.txt”`.
Trong lệnh này, `ls -l` chạy trước và tạo ra một danh sách tất cả các tệp. Thay vì hiển thị danh sách này ra màn hình, dấu `|` chuyển toàn bộ đầu ra đó cho lệnh `grep`. Lệnh `grep` nhận danh sách này làm đầu vào và tiến hành lọc, chỉ giữ lại những dòng nào có chứa “.txt”. Kết quả cuối cùng hiển thị ra màn hình chính là danh sách các tệp tin văn bản mà bạn cần tìm.
Kết hợp nhiều lệnh trong chuỗi pipe phức tạp
Sức mạnh thực sự của piping được thể hiện khi bạn kết nối nhiều hơn hai lệnh với nhau. Bằng cách này, bạn có thể tạo ra các chuỗi xử lý dữ liệu phức tạp chỉ trong một dòng lệnh duy nhất. Cú pháp vẫn tương tự: `lenh_1 | lenh_2 | lenh_3 | …`

Hãy xem xét một kịch bản thực tế trong quản trị hệ thống. Bạn muốn tìm mã tiến trình (Process ID – PID) của dịch vụ web server Apache (thường có tên là `httpd` hoặc `apache2`). Bạn có thể làm điều này bằng cách kết hợp ba lệnh: `ps`, `grep`, và `awk`.
Lệnh đầy đủ sẽ là: `ps aux | grep httpd | awk ‘{print $2}’`.
Hãy phân tích từng bước trong chuỗi này:
1. `ps aux`: Lệnh này liệt kê tất cả các tiến trình đang chạy trên hệ thống với thông tin chi tiết. Đầu ra của nó là một bảng lớn chứa hàng trăm dòng.
2. `| grep httpd`: Đầu ra từ `ps aux` được chuyển cho `grep httpd`. Lệnh này sẽ lọc và chỉ giữ lại những dòng chứa từ khóa “httpd”. Bây giờ, danh sách đã thu hẹp lại chỉ còn vài dòng liên quan đến tiến trình Apache.
3. `| awk ‘{print $2}’`: Kết quả sau khi lọc lại được chuyển tiếp cho `awk`. `awk` là một công cụ xử lý văn bản mạnh mẽ. Ở đây, `{print $2}` yêu cầu `awk` in ra cột thứ hai của mỗi dòng đầu vào. Trong đầu ra của lệnh `ps`, cột thứ hai chính là mã PID. Kết quả cuối cùng bạn nhận được chỉ là một con số – mã PID của tiến trình Apache.
Như bạn thấy, bằng cách nối các lệnh đơn giản, chúng ta đã thực hiện một tác vụ phức tạp một cách nhanh chóng và hiệu quả. Đây là minh chứng cho sức mạnh của việc xây dựng các công cụ nhỏ, chuyên dụng và kết hợp chúng thông qua piping.
Ứng dụng thực tế của piping trong quản trị hệ thống Linux
Lý thuyết là vậy, nhưng piping thực sự tỏa sáng khi được áp dụng vào các tác vụ quản trị hệ thống hàng ngày. Nó giúp bạn xử lý thông tin nhanh chóng và tự động hóa công việc một cách hiệu quả.
Xử lý và lọc dữ liệu log hệ thống
Một trong những công việc phổ biến nhất của quản trị viên hệ thống là kiểm tra các tệp log. Các tệp log hệ thống, chẳng hạn như `/var/log/syslog` hoặc log của ứng dụng, có thể chứa hàng nghìn hoặc thậm chí hàng triệu dòng. Việc đọc toàn bộ tệp để tìm một thông tin cụ thể là không khả thi. Đây là lúc piping phát huy tác dụng.
Giả sử bạn cần tìm tất cả các dòng ghi lỗi (error) trong tệp `syslog`. Thay vì mở tệp bằng một trình soạn thảo văn bản, bạn có thể sử dụng một chuỗi pipe. Lệnh `cat /var/log/syslog` sẽ đọc toàn bộ nội dung của tệp và in ra đầu ra tiêu chuẩn.
Tuy nhiên, nếu tệp quá lớn, màn hình của bạn sẽ bị tràn ngập văn bản. Chúng ta có thể dùng pipe để xử lý nó: `cat /var/log/syslog | grep error`.
Lệnh này sẽ chỉ hiển thị những dòng chứa từ “error”. Nhưng nếu kết quả vẫn còn quá dài để xem? Chúng ta có thể thêm một pipe nữa với lệnh `less`. Lệnh `less` cho phép bạn xem nội dung theo từng trang, cuộn lên xuống một cách dễ dàng. Lệnh cuối cùng sẽ là: `cat /var/log/syslog | grep error | less`. Chuỗi lệnh này giúp bạn điều hướng qua các thông báo lỗi một cách có kiểm soát và hiệu quả.
Tự động hóa tạo chuỗi lệnh phức tạp
Piping không chỉ dùng để lọc thông tin mà còn là một công cụ mạnh mẽ để tự động hóa các hành động phức tạp. Bằng cách kết hợp với các lệnh như `find` và `xargs`, bạn có thể thực hiện một hành động trên nhiều tệp cùng lúc. `xargs` là một lệnh đặc biệt, nó đọc các mục từ đầu vào tiêu chuẩn và thực thi một lệnh khác với các mục đó làm đối số.

Hãy tưởng tượng bạn muốn tìm tất cả các tệp có đuôi `.log` trong thư mục `/home/user` và xóa chúng đi. Lệnh `find /home/user -type f -name “*.log”` sẽ tìm và liệt kê tất cả các tệp phù hợp.
Bây giờ, làm thế nào để xóa chúng? Bạn có thể dùng pipe để chuyển danh sách tệp này cho lệnh `xargs`, và `xargs` sẽ gọi lệnh `rm` cho từng tệp. Lệnh hoàn chỉnh sẽ là: `find /home/user -type f -name “*.log” | xargs rm`.
Tương tự, nếu bạn muốn tìm một từ khóa cụ thể bên trong tất cả các tệp văn bản trong một thư mục, bạn có thể dùng lệnh: `find /home/user -type f -name “*.txt” | xargs grep “keyword”`. Lệnh này đầu tiên tìm tất cả các tệp `.txt`, sau đó `xargs` sẽ chạy `grep “keyword”` trên từng tệp trong danh sách đó. Piping giúp tạo ra các kịch bản quản trị nhanh gọn mà không cần viết các vòng lặp phức tạp trong một tệp script riêng biệt.
Những lưu ý khi sử dụng kỹ thuật piping để tối ưu hiệu suất và tránh lỗi
Mặc dù piping rất mạnh mẽ, việc sử dụng không đúng cách có thể dẫn đến lỗi hoặc làm giảm hiệu suất của hệ thống. Hiểu rõ những cạm bẫy tiềm ẩn sẽ giúp bạn viết các chuỗi lệnh hiệu quả và an toàn hơn.
Tránh lỗi phổ biến khi sử dụng piping
Một trong những lỗi phổ biến nhất là đầu vào và đầu ra không tương thích. Mỗi lệnh được thiết kế để xử lý một loại dữ liệu nhất định. Ví dụ, các lệnh xử lý văn bản như `grep`, `sed`, `awk` mong đợi đầu vào là văn bản thuần túy. Nếu bạn pipe đầu ra của một lệnh tạo ra dữ liệu nhị phân (binary data), chẳng hạn như một tệp ảnh hoặc một tệp nén, vào các công cụ này, kết quả sẽ không thể đoán trước và thường là lỗi.

Một lỗi khác là quên rằng mỗi lệnh trong chuỗi pipe chạy trong một subshell (tiến trình con) riêng của nó. Điều này có nghĩa là nếu bạn thay đổi một biến môi trường trong một phần của pipe, sự thay đổi đó sẽ không ảnh hưởng đến các phần khác hoặc shell cha. Ví dụ, trong lệnh `echo “data” | read my_var`, biến `my_var` sẽ không được đặt trong shell hiện tại của bạn vì lệnh `read` chạy trong một subshell riêng.
Ngoài ra, cần hết sức cẩn trọng khi sử dụng piping với các lệnh có thể gây ra thay đổi lớn trên hệ thống, chẳng hạn như `rm`. Một lỗi nhỏ trong lệnh `find` có thể khiến bạn xóa nhầm các tệp quan trọng. Luôn luôn chạy lệnh `find` một mình trước để kiểm tra danh sách tệp nó trả về trước khi pipe vào `xargs rm`.
Tối ưu hiệu suất sử dụng piping trong Bash
Hiệu suất là một yếu tố quan trọng, đặc biệt khi làm việc với lượng dữ liệu lớn. Mặc dù piping rất tiện lợi, mỗi lệnh trong chuỗi pipe sẽ tạo ra một tiến trình mới, gây tốn tài nguyên hệ thống. Do đó, nếu có thể thực hiện một tác vụ bằng một lệnh duy nhất, đó thường là lựa chọn tốt hơn. Ví dụ, thay vì viết `cat filename | grep “pattern”`, bạn nên viết `grep “pattern” filename`. Lệnh `grep` có khả năng đọc trực tiếp từ tệp, việc sử dụng `cat` ở đây là không cần thiết và tạo thêm một tiến trình thừa.

Một mẹo khác để tối ưu là sử dụng các lệnh tích hợp sẵn của shell (built-in) bất cứ khi nào có thể, vì chúng không cần tạo tiến trình mới. Đồng thời, hãy cố gắng giới hạn số lượng lệnh trong một chuỗi pipe. Một chuỗi quá dài và phức tạp không chỉ khó đọc, khó bảo trì mà còn có thể chạy chậm hơn do chi phí khởi tạo nhiều tiến trình.
Khi xử lý các tệp lớn, hãy xem xét các công cụ được thiết kế để xử lý dữ liệu theo dòng (stream processing) một cách hiệu quả. Các công cụ như awk và `sed` thường hiệu quả hơn so với việc viết các vòng lặp trong script shell để xử lý từng dòng một. Việc lựa chọn công cụ phù hợp cho từng bước trong chuỗi pipe sẽ giúp tối ưu hóa đáng kể hiệu suất tổng thể.
Các vấn đề thường gặp và cách khắc phục
Ngay cả những người dùng kinh nghiệm đôi khi cũng gặp phải những hành vi không mong muốn khi sử dụng pipe. Hiểu rõ nguyên nhân và cách khắc phục sẽ giúp bạn gỡ lỗi nhanh hơn.
Lỗi vòng lặp vô tận do pipe sai cú pháp
Một vấn đề khá phổ biến xảy ra khi kết hợp pipe với vòng lặp `while`. Giả sử bạn có một chuỗi lệnh như `command_produces_output | while read line; do … done`. Vấn đề ở đây là vòng lặp `while` chạy trong một subshell. Bất kỳ biến nào bạn tạo hoặc sửa đổi bên trong vòng lặp này sẽ bị mất ngay khi vòng lặp kết thúc.

Ví dụ, đoạn mã sau sẽ không hoạt động như mong đợi:
`count=0`
`ls -1 | while read filename; do`
` ((count++))`
`done`
`echo “Total files: $count”`
Kết quả in ra sẽ là “Total files: 0” vì biến `count` trong subshell của vòng lặp `while` là một bản sao riêng biệt. Để khắc phục, bạn có thể sử dụng “process substitution” trong Bash: `while read filename; do … done < <(command_produces_output)`. Bằng cách này, vòng lặp `while` sẽ chạy trong shell hiện tại, và các biến sẽ được giữ lại.
Ngoài ra, cú pháp pipe sai có thể gây ra lỗi. Ví dụ, đặt dấu `|` ở cuối dòng mà không có lệnh nào theo sau sẽ khiến shell chờ đợi đầu vào và có thể trông giống như bị treo. Luôn đảm bảo rằng mỗi dấu `|` đều có một lệnh ở cả hai bên.
Đầu ra bị cắt hoặc mất dữ liệu khi sử dụng pipe
Đôi khi bạn có thể thấy rằng đầu ra từ một chuỗi pipe dường như bị thiếu hoặc không đầy đủ. Nguyên nhân phổ biến nhất của vấn đề này là do cơ chế đệm (buffering). Các lệnh thường sử dụng bộ đệm để tối ưu hóa hiệu suất I/O. Khi đầu ra không phải là một terminal (ví dụ, khi nó được pipe cho một lệnh khác), nó có thể sử dụng bộ đệm khối (block buffering) thay vì bộ đệm dòng (line buffering).
Điều này có nghĩa là lệnh sẽ không gửi dữ liệu qua pipe ngay lập tức sau mỗi dòng mới, mà sẽ đợi cho đến khi bộ đệm đầy. Nếu lệnh tiếp theo trong chuỗi pipe xử lý dữ liệu và kết thúc sớm, nó có thể không nhận được toàn bộ dữ liệu từ lệnh trước đó.
Để khắc phục vấn đề này, nhiều lệnh cung cấp các tùy chọn để thay đổi hành vi đệm. Ví dụ, lệnh `grep` có tùy chọn `–line-buffered`. Một công cụ phổ biến khác là `stdbuf`, cho phép bạn sửa đổi cơ chế đệm cho bất kỳ lệnh nào. Ví dụ: `stdbuf -oL command1 | command2` sẽ buộc `command1` sử dụng bộ đệm dòng cho đầu ra của nó. Hiểu và kiểm soát được cơ chế đệm là rất quan trọng khi xử lý dữ liệu thời gian thực hoặc khi gỡ lỗi các chuỗi pipe phức tạp.
Best Practices khi sử dụng kỹ thuật piping trong Bash
Để khai thác tối đa sức mạnh của piping và giữ cho các script của bạn luôn sạch sẽ, hiệu quả và dễ bảo trì, hãy tuân thủ một vài nguyên tắc thực hành tốt nhất sau đây.
- Luôn kiểm tra kỹ từng lệnh trước khi kết nối: Trước khi xây dựng một chuỗi pipe dài, hãy chạy riêng lẻ từng lệnh để đảm bảo chúng hoạt động đúng như bạn mong đợi. Kiểm tra đầu ra của `lenh_1` để chắc chắn nó có định dạng phù hợp làm đầu vào cho `lenh_2`. Điều này giúp bạn xác định và sửa lỗi ở từng bước một cách dễ dàng hơn.
- Không dùng pipe cho những thao tác không cần thiết: Tránh các trường hợp dư thừa như cat file | grep ‘pattern’. Lệnh `grep` có thể đọc trực tiếp từ tệp với cú pháp `grep ‘pattern’ file`. Loại bỏ các lệnh không cần thiết giúp giảm số lượng tiến trình được tạo ra, tiết kiệm tài nguyên và tăng tốc độ thực thi.
- Giữ cho chuỗi pipe rõ ràng và dễ hiểu: Mặc dù bạn có thể tạo ra những chuỗi pipe rất dài, nhưng một chuỗi lệnh phức tạp sẽ rất khó để người khác (và chính bạn trong tương lai) đọc và gỡ lỗi. Nếu một chuỗi pipe trở nên quá rối, hãy cân nhắc chia nó thành nhiều bước hoặc viết một script hoàn chỉnh với các biến trung gian để tăng tính rõ ràng.
- Sử dụng hiệu quả các công cụ grep, awk, và sed: Đây là bộ ba công cụ xử lý văn bản kinh điển trên Linux và là những người bạn đồng hành tuyệt vời của piping. Hãy dành thời gian để học các tính năng mạnh mẽ của chúng. `grep` dùng để lọc dòng, `sed` dùng để chỉnh sửa dòng, và `awk` dùng để trích xuất và định dạng lại các cột dữ liệu. Việc kết hợp chúng một cách khéo léo sẽ giải quyết được vô số vấn đề.
Tuân thủ những nguyên tắc này không chỉ giúp bạn viết code tốt hơn mà còn hình thành tư duy giải quyết vấn đề một cách có hệ thống và hiệu quả theo triết lý của Unix.
Kết luận
Qua bài viết này, chúng ta đã cùng nhau khám phá kỹ thuật piping trong Bash, từ những khái niệm cơ bản nhất đến các ứng dụng thực tiễn trong công việc quản trị hệ thống Linux. Piping không chỉ là một tính năng, nó là hiện thân của triết lý “làm một việc và làm thật tốt” của Unix. Bằng cách kết hợp các công cụ đơn giản, chuyên dụng, bạn có thể giải quyết các vấn đề phức tạp một cách thanh lịch và hiệu quả. Lợi ích của việc thành thạo piping là rất lớn, giúp bạn tiết kiệm thời gian, tự động hóa các tác vụ lặp đi lặp lại và tăng cường khả năng kiểm soát hệ thống.
Để thực sự làm chủ kỹ thuật này, không có cách nào tốt hơn là thực hành thường xuyên. Đừng ngần ngại thử nghiệm với các chuỗi lệnh khác nhau, phân tích các tệp log trên hệ thống của bạn, hay tự động hóa một công việc nhỏ trong quy trình làm việc hàng ngày. Mỗi lần thử nghiệm là một cơ hội để bạn hiểu sâu hơn về cách các lệnh tương tác với nhau.
Hãy bắt đầu áp dụng kỹ thuật piping vào các dự án thực tế của bạn ngay hôm nay. Tham khảo thêm các tài liệu về Bash scripting nâng cao để khám phá thêm nhiều công cụ và kỹ thuật mạnh mẽ khác. Chúc bạn thành công trên hành trình chinh phục dòng lệnh Linux