Bạn đã từng nghe đến Apache Kafka nhưng chưa rõ Kafka là gì và vì sao nó lại quan trọng trong thế giới xử lý dữ liệu hiện đại? Hằng ngày, chúng ta đang tạo ra một lượng dữ liệu khổng lồ từ mạng xã hội, giao dịch trực tuyến, đến các thiết bị IoT. Khi lượng dữ liệu ngày càng lớn và thay đổi nhanh chóng, các hệ thống truyền thống bắt đầu gặp khó khăn. Doanh nghiệp cần một giải pháp nhắn tin phân tán hiệu quả để có thể xử lý luồng dữ liệu này theo thời gian thực, nếu không muốn bỏ lỡ những thông tin kinh doanh quý giá.
Apache Kafka chính là nền tảng mã nguồn mở được thiết kế để đáp ứng chính xác nhu cầu này. Nó không chỉ là một hệ thống lưu trữ log đơn thuần, mà còn là một cỗ máy mạnh mẽ có khả năng truyền tải và xử lý hàng tỷ sự kiện mỗi ngày với độ trễ cực thấp. Với Kafka, các công ty có thể xây dựng những ứng dụng phản ứng tức thì với dữ liệu mới, từ việc phát hiện gian lận, gợi ý sản phẩm cho khách hàng, cho đến giám sát hệ thống theo thời gian thực.
Trong bài viết này, AZWEB sẽ cùng bạn đi sâu vào thế giới của Apache Kafka. Chúng ta sẽ bắt đầu từ những khái niệm cơ bản nhất, khám phá nguồn gốc ra đời, tìm hiểu chi tiết về cấu trúc và các thành phần cốt lõi. Hơn nữa, bài viết cũng sẽ phân tích những tính năng nổi bật, các ứng dụng thực tế, so sánh ưu nhược điểm và cung cấp hướng dẫn cài đặt cơ bản để bạn có thể tự mình trải nghiệm. Hãy cùng bắt đầu hành trình khám phá công cụ quyền năng này nhé!
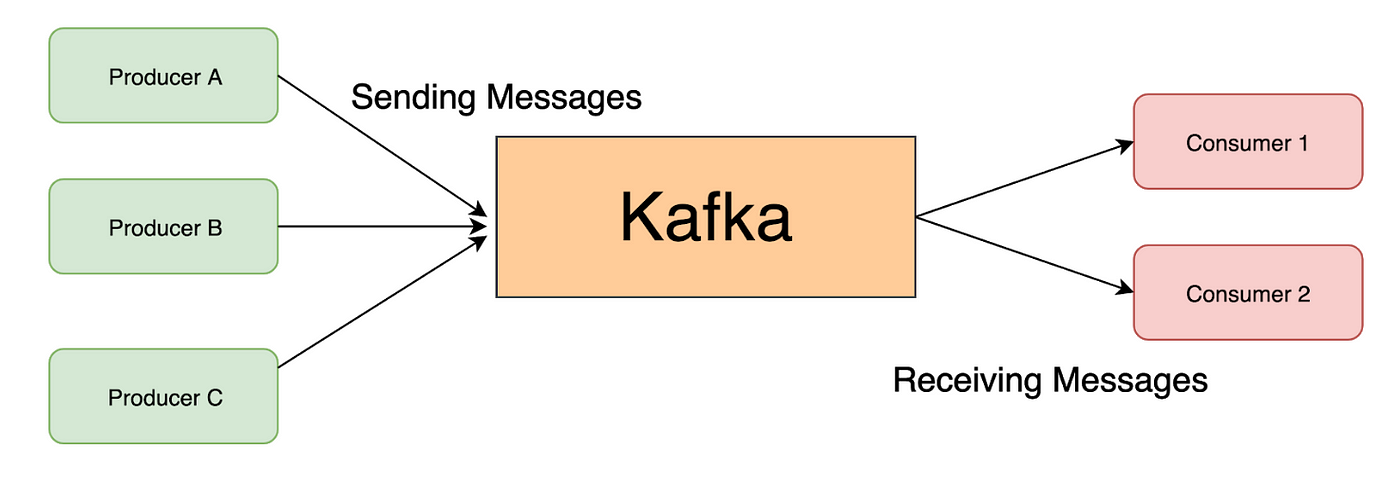
Apache Kafka là gì và nguồn gốc
Để hiểu rõ sức mạnh của Kafka, trước tiên chúng ta cần nắm vững khái niệm và lịch sử hình thành của nó. Kafka không chỉ là một công cụ, mà là một giải pháp được sinh ra từ nhu cầu thực tế của các hệ thống quy mô lớn.
Khái niệm cơ bản về Apache Kafka
Vậy, Kafka là gì? Nói một cách đơn giản, Apache Kafka là một nền tảng streaming sự kiện phân tán (distributed event streaming platform). Bạn có thể hình dung nó như một hệ thống thần kinh trung ương cho dữ liệu của một công ty. Hệ thống này có khả năng thu thập, xử lý và lưu trữ các luồng sự kiện (dữ liệu) theo thời gian thực một cách bền bỉ và có khả năng chịu lỗi cao.
Không giống như các hàng đợi tin nhắn (message queue) truyền thống, Kafka được thiết kế ngay từ đầu để xử lý thông lượng cực lớn. Nó hoạt động như một trung gian, cho phép các ứng dụng khác nhau có thể “nói chuyện” với nhau bằng cách gửi và nhận dữ liệu mà không cần kết nối trực tiếp. Điều này giúp tạo ra một kiến trúc hệ thống linh hoạt, dễ dàng mở rộng và bảo trì. Kafka là công cụ lý tưởng cho việc xây dựng các đường ống dữ liệu (data pipeline) thời gian thực và các ứng dụng streaming.
Lịch sử và sự phát triển của Kafka
Apache Kafka có một khởi đầu khá thú vị. Nó được sáng tạo ra tại LinkedIn vào khoảng năm 2010 bởi một nhóm kỹ sư tài năng bao gồm Jay Kreps, Neha Narkhede và Jun Rao. Mục tiêu ban đầu của họ là giải quyết một vấn đề rất cụ thể: làm thế nào để xử lý một lượng log sự kiện khổng lồ được tạo ra từ hoạt động của người dùng trên nền tảng LinkedIn một cách hiệu quả.
Các giải pháp lúc bấy giờ không đáp ứng được yêu cầu về khả năng mở rộng và hiệu suất. Vì vậy, họ đã quyết định xây dựng một hệ thống hoàn toàn mới. Hệ thống này không chỉ giải quyết được bài toán của LinkedIn mà còn cho thấy tiềm năng to lớn trong nhiều lĩnh vực khác. Nhận thấy giá trị đó, LinkedIn đã quyết định mở mã nguồn của Kafka và tặng nó cho Apache Software Foundation (ASF) vào năm 2011. Dưới sự bảo trợ của Apache, Kafka đã phát triển vượt bậc, trở thành một trong những dự án mã nguồn mở thành công nhất. Ngày nay, nó được hàng ngàn công ty trên toàn thế giới tin dùng, từ các startup nhỏ cho đến những gã khổng lồ công nghệ.
Cấu trúc và thành phần chính của Kafka
Để Kafka có thể hoạt động một cách mạnh mẽ và linh hoạt, nó được xây dựng dựa trên một kiến trúc phân tán với các thành phần cốt lõi phối hợp nhịp nhàng với nhau. Hiểu rõ cấu trúc này là chìa khóa để bạn có thể triển khai và vận hành Kafka hiệu quả.
Thành phần Broker, Topic, Partition và Producer/Consumer
Kiến trúc của Kafka xoay quanh bốn thành phần chính. Hãy tưởng tượng Kafka như một thư viện số khổng lồ.
- Broker: Đây là các máy chủ trong cụm Kafka. Mỗi Broker giống như một tòa nhà trong khu phức hợp thư viện, chịu trách nhiệm lưu trữ dữ liệu. Một cụm Kafka thường bao gồm nhiều Broker để đảm bảo tính sẵn sàng cao và khả năng chịu lỗi. Nếu một Broker gặp sự cố, các Broker khác vẫn tiếp tục hoạt động.
- Topic: Đây là các danh mục hoặc kênh để tổ chức dữ liệu. Bạn có thể xem mỗi Topic như một giá sách dành riêng cho một chủ đề nhất định, ví dụ: “log_nguoi_dung” hay “giao_dich_thanh_toan”. Khi một ứng dụng muốn gửi dữ liệu, nó sẽ gửi vào một Topic cụ thể.
- Partition (Phân vùng): Để tăng tốc độ xử lý, mỗi Topic được chia thành nhiều Partition. Partition giống như các kệ sách riêng lẻ trên một giá sách lớn. Dữ liệu trong một Topic sẽ được phân bổ đều vào các Partition này. Việc chia nhỏ dữ liệu cho phép nhiều người (Consumer) có thể “đọc” dữ liệu từ cùng một Topic một cách song song, giúp tăng thông lượng lên đáng kể.
- Producer và Consumer: Đây là các “diễn viên” chính tương tác với Kafka.
- Producer là ứng dụng hoặc hệ thống gửi dữ liệu (tin nhắn) vào các Topic của Kafka. Producer giống như một tác giả, liên tục viết và gửi sách mới vào thư viện.
- Consumer là ứng dụng hoặc hệ thống đọc dữ liệu từ các Topic. Consumer giống như những độc giả, đến thư viện để lấy sách về đọc. Nhiều Consumer có thể đọc cùng một Topic để phục vụ các mục đích khác nhau.
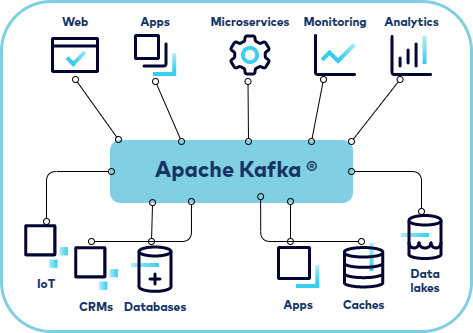
Cơ chế hoạt động và lưu trữ dữ liệu
Kafka lưu trữ dữ liệu một cách rất đặc biệt và hiệu quả. Dữ liệu được ghi vào các Partition dưới dạng một chuỗi các bản ghi không thể thay đổi, gọi là “log” và hoạt động theo cơ chế append-only. Điều này có nghĩa là các tin nhắn mới sẽ luôn được thêm vào cuối của file log, tương tự như việc ghi chép vào một cuốn sổ tay. Cách tiếp cận này giúp tối ưu hóa cho việc ghi dữ liệu tuần tự, đạt được tốc độ cực nhanh.
Một trong những sức mạnh lớn nhất của Kafka là cơ chế Data Replication (Nhân bản dữ liệu). Để đảm bảo an toàn và độ bền của dữ liệu, mỗi Partition sẽ có một bản chính (leader) và một hoặc nhiều bản sao (replicas). Mọi thao tác ghi dữ liệu đều được thực hiện trên Partition leader trước, sau đó dữ liệu sẽ được đồng bộ hóa tới các replicas. Nếu Broker chứa Partition leader gặp sự cố, một trong các replicas sẽ tự động được bầu làm leader mới. Nhờ vậy, hệ thống có thể tiếp tục hoạt động mà không bị gián đoạn hay mất mát dữ liệu.
Các tính năng nổi bật của Kafka trong xử lý dữ liệu thời gian thực
Sự phổ biến của Kafka không phải là ngẫu nhiên. Nó đến từ những tính năng vượt trội được thiết kế đặc biệt để giải quyết các thách thức của dữ liệu lớn và xử lý thời gian thực. Hãy cùng điểm qua những đặc điểm làm nên tên tuổi của Apache Kafka.

Tính khả mở và khả năng chịu lỗi cao
Một trong những lý do hàng đầu khiến các doanh nghiệp lựa chọn Kafka là khả năng mở rộng (scalability) gần như vô hạn. Kiến trúc phân tán của Kafka cho phép bạn bắt đầu với một cụm nhỏ chỉ vài Broker. Khi nhu cầu xử lý dữ liệu tăng lên, bạn có thể dễ dàng mở rộng quy mô hệ thống bằng cách thêm các Broker mới vào cụm mà không gây gián đoạn hoạt động. Kafka sẽ tự động phân bổ lại dữ liệu và tải công việc qua các Broker mới, giúp hệ thống luôn hoạt động ổn định dù lượng dữ liệu có tăng đột biến.
Bên cạnh đó, khả năng chịu lỗi (fault tolerance) là một yếu tố cốt lõi. Như đã đề cập, cơ chế nhân bản dữ liệu (replication) giữa các Broker đảm bảo rằng dữ liệu của bạn luôn an toàn. Nếu một máy chủ Broker bị lỗi, bị sập hoặc cần bảo trì, Kafka sẽ tự động chuyển hướng các tác vụ sang các Broker khác đang hoạt động. Các Consumer và Producer sẽ không hề bị ảnh hưởng. Khả năng tự động phục hồi này giúp xây dựng các hệ thống có độ tin cậy và độ sẵn sàng cao, hoạt động 24/7.
Hiệu suất và độ trễ thấp
Trong các ứng dụng thời gian thực, tốc độ là yếu tố sống còn. Kafka được thiết kế để mang lại hiệu suất cực cao và độ trễ (latency) cực thấp. Nó có thể xử lý hàng trăm nghìn, thậm chí hàng triệu tin nhắn mỗi giây trên một cụm máy chủ thông thường. Bí quyết đằng sau hiệu suất ấn tượng này là gì?
Thứ nhất, Kafka tối ưu hóa việc đọc và ghi dữ liệu bằng cách sử dụng kỹ thuật truy cập đĩa tuần tự (sequential disk access) và tận dụng page cache của hệ điều hành. Điều này nhanh hơn rất nhiều so với việc truy cập ngẫu nhiên. Thứ hai, Kafka sử dụng cơ chế batching (gom nhóm). Thay vì gửi từng tin nhắn một, Producer có thể gom nhiều tin nhắn lại thành một lô (batch) rồi mới gửi đi. Tương tự, Consumer cũng có thể lấy về một lô tin nhắn trong một lần yêu cầu. Việc này giúp giảm đáng kể chi phí mạng và tăng thông lượng tổng thể, đảm bảo dữ liệu được truyền tải nhanh chóng và hiệu quả, hoàn toàn phù hợp cho các ứng dụng đòi hỏi phản ứng tức thì.
Ứng dụng thực tế của Kafka trong các hệ thống phân tán
Lý thuyết là vậy, nhưng Kafka thực sự tỏa sáng ở đâu trong thế giới thực? Sức mạnh của Kafka được minh chứng rõ nét qua việc nó trở thành xương sống cho hệ thống dữ liệu của rất nhiều công ty công nghệ hàng đầu.

Đối với doanh nghiệp lớn và hệ thống phân tán
Trong môi trường doanh nghiệp, Kafka được ứng dụng vào vô số bài toán quan trọng. Nó thường đóng vai trò là “trung tâm dữ liệu”, kết nối các hệ thống và ứng dụng khác nhau một cách linh hoạt.
- Streaming Dữ Liệu (Real-time Data Pipelines): Đây là ứng dụng phổ biến nhất. Kafka được dùng để xây dựng các đường ống dữ liệu, thu thập dữ liệu từ nhiều nguồn (như web logs, ứng dụng di động, cảm biến IoT) và chuyển tiếp đến các hệ thống xử lý khác như Spark, Flink hoặc các kho dữ liệu (data warehouse) để phân tích.
- Tích hợp Hệ thống dựa trên Sự kiện (Event-Driven Architecture): Kafka giúp các microservices giao tiếp với nhau một cách bất đồng bộ. Thay vì gọi API trực tiếp, một service sẽ phát ra một sự kiện vào Kafka. Các service khác quan tâm đến sự kiện đó sẽ lắng nghe và xử lý. Kiến trúc này giúp hệ thống trở nên linh hoạt, dễ bảo trì và mở rộng hơn.
- Giám sát và Phân tích Hoạt động: Các công ty sử dụng Kafka để thu thập dữ liệu logs và metrics từ hàng ngàn máy chủ và ứng dụng. Dữ liệu này sau đó được đẩy vào các công cụ như Elasticsearch hoặc Prometheus để giám sát hiệu suất hệ thống, phát hiện sự cố và phân tích hành vi người dùng theo thời gian thực.
- Xử lý Luồng (Stream Processing): Kết hợp với các framework như Kafka Streams hoặc ksqlDB, Kafka cho phép bạn xử lý và biến đổi dữ liệu ngay khi nó vừa được tạo ra. Ví dụ, bạn có thể tính toán, tổng hợp hoặc phát hiện các mẫu bất thường trên luồng dữ liệu một cách liên tục.
Một số ví dụ tiêu biểu
Để thấy rõ hơn sức ảnh hưởng của Kafka, hãy xem cách các “ông lớn” công nghệ đang sử dụng nó:
- Netflix: Gã khổng lồ streaming này sử dụng Kafka để xử lý hàng nghìn tỷ sự kiện mỗi ngày. Mọi thứ từ việc bạn nhấn nút “play”, đề xuất phim, cho đến việc theo dõi hiệu suất hệ thống đều đi qua Kafka. Nó giúp Netflix thu thập dữ liệu hoạt động của người dùng trong thời gian thực để cá nhân hóa trải nghiệm một cách tốt nhất.
- LinkedIn: Là nơi khai sinh ra Kafka, LinkedIn vẫn tiếp tục sử dụng nó làm nền tảng cho việc theo dõi hoạt động người dùng, xây dựng biểu đồ quan hệ xã hội (social graph) và cung cấp các tin tức liên quan.
- Uber: Uber dựa vào Kafka để xử lý dữ liệu vị trí từ tài xế và hành khách, tính toán giá cước động, và dự báo nhu cầu di chuyển theo thời gian thực. Mỗi chuyến đi bạn thực hiện đều tạo ra các sự kiện được đẩy qua hệ thống Kafka khổng lồ của họ.
Những ví dụ này cho thấy Kafka không chỉ là một công cụ mạnh mẽ mà còn là một thành phần không thể thiếu trong kiến trúc của các hệ thống hiện đại, đòi hỏi khả năng xử lý dữ liệu lớn và tức thời.
Lợi ích và hạn chế khi sử dụng Apache Kafka
Bất kỳ công nghệ nào cũng có hai mặt, và Kafka cũng không ngoại lệ. Việc hiểu rõ cả ưu điểm và nhược điểm sẽ giúp bạn quyết định liệu Kafka có phải là lựa chọn phù hợp cho dự án của mình hay không.
Lợi ích
Apache Kafka mang lại rất nhiều lợi ích vượt trội, đặc biệt cho các hệ thống quy mô lớn:
- Thông lượng Cực cao (High Throughput): Như đã phân tích, nhờ vào cơ chế ghi log tuần tự và gom nhóm tin nhắn, Kafka có thể xử lý hàng triệu tin nhắn mỗi giây, đáp ứng nhu cầu của những ứng dụng có lượng dữ liệu khổng lồ.
- Độ trễ Thấp (Low Latency): Kafka được tối ưu để truyền tải dữ liệu gần như ngay lập tức (vài mili giây), rất lý tưởng cho các ứng dụng yêu cầu phản ứng nhanh như phát hiện gian lận hay gợi ý sản phẩm.
- Khả năng Mở rộng Linh hoạt (Scalability): Bạn có thể dễ dàng tăng cường năng lực của hệ thống bằng cách thêm các máy chủ (Broker) mới vào cụm Kafka mà không cần dừng hệ thống.
- Độ bền và Độ tin cậy Cao (Durability and Reliability): Với cơ chế nhân bản dữ liệu (replication), dữ liệu được sao lưu an toàn trên nhiều máy chủ. Điều này đảm bảo rằng bạn sẽ không bị mất dữ liệu ngay cả khi một vài máy chủ gặp sự cố.
- Hệ sinh thái Phong phú (Rich Ecosystem): Kafka được hỗ trợ bởi một cộng đồng lớn và có một hệ sinh thái mạnh mẽ với các công cụ tích hợp như Kafka Connect (để kết nối với các nguồn dữ liệu khác), Kafka Streams (để xử lý luồng), và ksqlDB (truy vấn dữ liệu luồng bằng SQL).
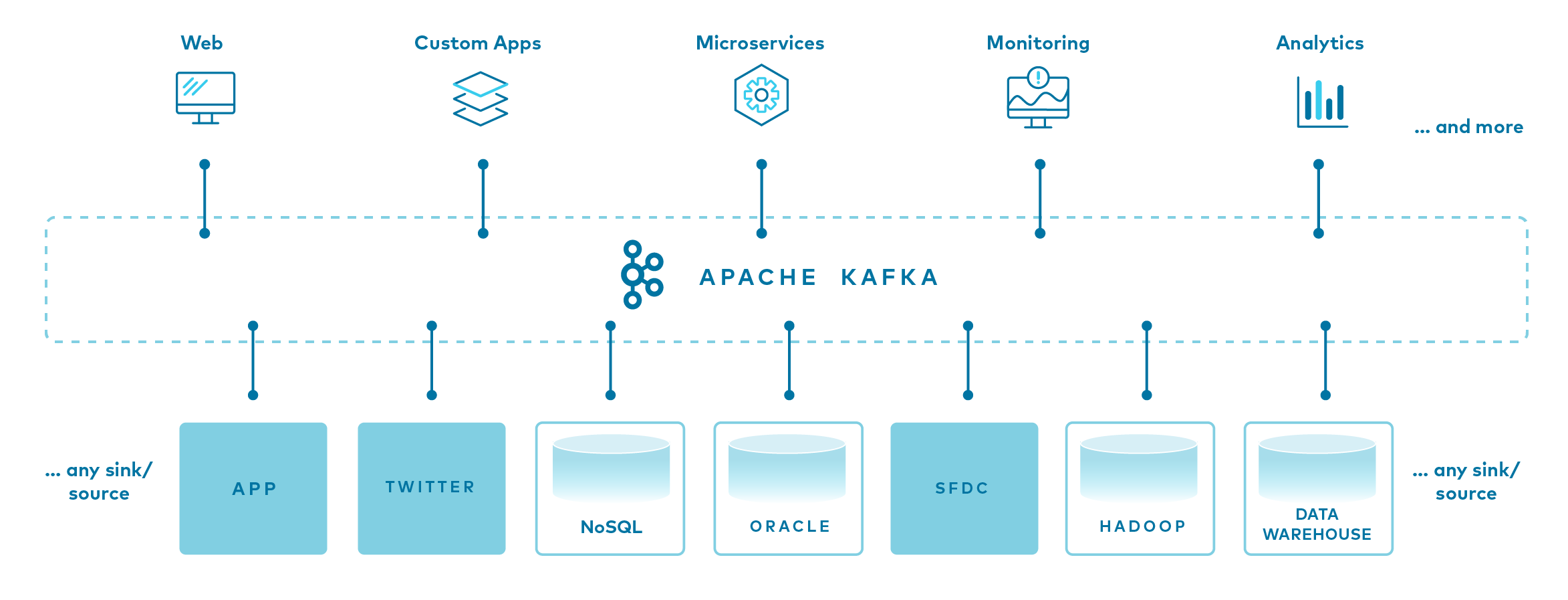
Hạn chế
Tuy nhiên, việc triển khai Kafka cũng đi kèm với một số thách thức:
- Độ phức tạp trong Vận hành: Kafka là một hệ thống phân tán phức tạp. Việc cài đặt, cấu hình, giám sát và bảo trì một cụm Kafka đòi hỏi kiến thức chuyên sâu về cả Kafka lẫn hệ thống phân tán. Đây không phải là một công nghệ “cắm và chạy“.
- Yêu cầu về Tài nguyên: Để vận hành ổn định, đặc biệt là với Zookeeper (một thành phần quản lý của Kafka), hệ thống cần một lượng tài nguyên phần cứng (CPU, RAM, đĩa) nhất định.
- Không phù hợp cho các bài toán nhỏ lẻ: Nếu bạn chỉ cần một hàng đợi tin nhắn đơn giản cho một ứng dụng nhỏ với lượng tải thấp, Kafka có thể là một giải pháp quá mức cần thiết (overkill). Các công cụ nhẹ nhàng hơn như RabbitMQ hay Redis Pub/Sub có thể là lựa chọn tốt hơn.
- Quản lý Consumer phức tạp: Mặc dù Kafka quản lý việc gửi tin nhắn rất tốt, việc xử lý logic phía Consumer (như đảm bảo xử lý tin nhắn đúng một lần, xử lý lỗi) đôi khi có thể phức tạp và đòi hỏi lập trình viên phải cẩn thận.
Hướng dẫn cơ bản cài đặt và triển khai Kafka
Sau khi đã tìm hiểu về lý thuyết, phần thú vị nhất chính là bắt tay vào thực hành. Phần này sẽ hướng dẫn bạn các bước cơ bản để cài đặt và chạy thử một cụm Kafka đơn giản trên máy của mình.
Điều kiện cần chuẩn bị
Trước khi bắt đầu, bạn cần đảm bảo môi trường của mình đã sẵn sàng với một vài yêu cầu sau:
- Môi trường Java (Java Development Kit – JDK): Kafka được viết bằng Java và Scala, vì vậy bạn cần cài đặt JDK (phiên bản 8 trở lên) trên máy tính của mình. Bạn có thể kiểm tra phiên bản Java bằng lệnh
java -versiontrong terminal. Nếu bạn chưa rõ Java là gì, có thể tham khảo để nắm bắt cơ bản. - Zookeeper: Kafka sử dụng Apache Zookeeper để quản lý và điều phối các Broker trong cụm. Nó lưu trữ các thông tin metadata quan trọng như danh sách Broker, cấu hình Topic, và ai là leader của các Partition. Tin vui là các phiên bản Kafka gần đây đã tích hợp sẵn Zookeeper, bạn chỉ cần khởi chạy nó từ gói tải về của Kafka là được.
- Máy chủ để chạy Kafka: Bạn có thể cài đặt trên máy tính cá nhân (Windows, macOS, Linux) để thử nghiệm hoặc trên một máy chủ riêng cho môi trường production. Đảm bảo máy chủ có đủ RAM (khuyến nghị tối thiểu 4GB) và dung lượng đĩa.

Các bước cài đặt cơ bản
Dưới đây là quy trình rút gọn để bạn có thể nhanh chóng “chạm” vào Kafka:
- Tải Kafka: Truy cập trang chủ của Apache Kafka và tải về phiên bản binary mới nhất. Giải nén file vừa tải về vào một thư mục bất kỳ trên máy của bạn.
- Khởi chạy Zookeeper: Mở terminal, di chuyển vào thư mục Kafka đã giải nén. Chạy lệnh sau để khởi động Zookeeper server. Zookeeper sẽ chạy ngầm và lắng nghe ở cổng 2181.
bin/zookeeper-server-start.sh config/zookeeper.properties - Khởi chạy Kafka Broker: Mở một terminal mới khác. Chạy lệnh sau để khởi động Kafka Broker. Broker sẽ lắng nghe kết nối từ client ở cổng 9092.
bin/kafka-server-start.sh config/server.properties - Tạo một Topic: Bây giờ cụm Kafka của bạn đã hoạt động. Hãy tạo một Topic tên là
azweb-testvới 1 partition và 1 replica. Mở một terminal thứ ba và chạy lệnh:bin/kafka-topics.sh --create --topic azweb-test --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 - Chạy Producer để gửi tin nhắn: Mở một terminal nữa để khởi động một producer console. Từ đây, bạn có thể gõ các tin nhắn và nhấn Enter để gửi vào Topic
azweb-test.bin/kafka-console-producer.sh --topic azweb-test --bootstrap-server localhost:9092
Gõ thử: Xin chao AZWEB
Gõ tiếp: Day la tin nhan dau tien cua toi - Chạy Consumer để nhận tin nhắn: Cuối cùng, mở một terminal thứ năm để khởi động consumer console. Nó sẽ lắng nghe và in ra tất cả các tin nhắn được gửi đến Topic
azweb-test.bin/kafka-console-consumer.sh --topic azweb-test --from-beginning --bootstrap-server localhost:9092
Nếu mọi thứ thành công, bạn sẽ thấy các tin nhắn mình đã gõ ở bước 5 xuất hiện trên màn hình của consumer. Chúc mừng, bạn đã cài đặt và tương tác thành công với cụm Kafka đầu tiên của mình!
Common Issues/Troubleshooting
Khi làm việc với một hệ thống phức tạp như Kafka, việc gặp phải lỗi là điều khó tránh khỏi. Dưới đây là một số vấn đề phổ biến và gợi ý cách xử lý để giúp bạn gỡ rối nhanh hơn.
Lỗi kết nối giữa Producer/Consumer và Broker
Đây là một trong những lỗi thường gặp nhất, đặc biệt là khi mới thiết lập. Biểu hiện là Producer không thể gửi tin nhắn hoặc Consumer không thể nhận được dữ liệu.
- Nguyên nhân:
- Sai địa chỉ
bootstrap.servers: Đây là lỗi cơ bản nhất. Bạn có thể đã nhập sai địa chỉ IP hoặc cổng của Kafka Broker trong cấu hình của Producer/Consumer. Cổng mặc định là 9092. - Tường lửa (Firewall): Tường lửa trên máy chủ Kafka hoặc trên máy client có thể đang chặn kết nối đến cổng 9092. Hãy kiểm tra và mở cổng nếu cần thiết.
- Lỗi cấu hình
listenerstrongserver.properties: Trong môi trường có nhiều network interface (ví dụ như Docker hoặc cloud), Kafka Broker cần được cấu hình đúnglistenersvàadvertised.listenersđể các client từ bên ngoài có thể kết nối được. Nếu không, Broker có thể quảng bá một địa chỉ IP nội bộ mà client không thể truy cập.
- Sai địa chỉ
- Cách xử lý:
- Kiểm tra kỹ lại địa chỉ và cổng trong file cấu hình.
- Sử dụng các công cụ như
telnethoặcncđể kiểm tra kết nối mạng từ máy client đến máy chủ Kafka trên cổng 9092 (ví dụ:telnet <kafka_host> 9092). - Xem lại file
server.propertiestrên Broker để chắc chắn rằngadvertised.listenersđược đặt thành địa chỉ IP hoặc hostname mà client có thể phân giải và kết nối.
Vấn đề đồng bộ dữ liệu giữa các Broker
Trong một cụm Kafka có nhiều Broker, việc đồng bộ dữ liệu giữa các replica là rất quan trọng để đảm bảo tính chịu lỗi. Đôi khi, quá trình này có thể gặp trục trặc.
- Nguyên nhân:
- Mạng chậm hoặc không ổn định: Nếu mạng giữa các Broker bị chậm hoặc gián đoạn, các replica sẽ không thể sao chép dữ liệu từ leader kịp thời. Điều này dẫn đến tình trạng “Under-replicated Partitions” (phân vùng không đủ bản sao).
- Broker quá tải: Nếu một Broker leader đang phải xử lý quá nhiều yêu cầu ghi, nó có thể không đủ tài nguyên để gửi dữ liệu đến các follower.
- Broker bị sập: Khi một Broker chứa replica bị sập, các partition trên đó sẽ tạm thời không đồng bộ được cho đến khi Broker đó khởi động lại.
- Cách xử lý:
- Sử dụng các công cụ giám sát Kafka (như Kafka Manager, Confluent Control Center, hoặc Prometheus/Grafana) để theo dõi số lượng “Under-replicated Partitions”. Nếu con số này lớn hơn 0, đó là dấu hiệu cần kiểm tra.
- Kiểm tra tình trạng mạng giữa các Broker.
- Phân tích tải trên từng Broker để xem có Broker nào đang bị quá tải hay không. Nếu có, bạn có thể cần phải cân bằng lại phân vùng (rebalance partitions) hoặc thêm Broker mới vào cụm.
- Kiểm tra log của Kafka Broker để tìm các thông báo lỗi liên quan đến việc đồng bộ hóa replica.
Best Practices
Để khai thác tối đa sức mạnh của Kafka và đảm bảo hệ thống hoạt động ổn định, bền vững, việc tuân thủ các thực hành tốt nhất là vô cùng quan trọng. Dưới đây là những khuyến nghị hàng đầu từ AZWEB.

- Theo dõi và giám sát hệ thống Kafka thường xuyên: Đừng bao giờ vận hành Kafka mà không có công cụ giám sát. Bạn cần theo dõi các chỉ số quan trọng như độ trễ của Consumer (consumer lag), số lượng partition không đồng bộ, thông lượng mạng, và việc sử dụng CPU/bộ nhớ của các Broker. Việc phát hiện sớm các dấu hiệu bất thường sẽ giúp bạn ngăn chặn các sự cố lớn.
- Tối ưu hóa cấu hình phân vùng và replication: Số lượng partition cho một topic ảnh hưởng trực tiếp đến khả năng xử lý song song. Hãy chọn số partition dựa trên thông lượng mong muốn và số lượng consumer. Đồng thời, luôn đặt
replication.factorít nhất là 3 trong môi trường production để đảm bảo dữ liệu an toàn ngay cả khi một Broker bị lỗi và một Broker khác đang bảo trì. - Không nên sử dụng Kafka làm hệ thống lưu trữ lâu dài (primary database): Mặc dù Kafka có khả năng lưu trữ dữ liệu bền bỉ, nó không được thiết kế để thay thế một cơ sở dữ liệu truyền thống. Kafka được tối ưu cho việc streaming và truy cập tuần tự, không phải cho các truy vấn phức tạp hay cập nhật bản ghi ngẫu nhiên. Hãy sử dụng Kafka như một hệ thống trung gian, một bộ đệm tin cậy, và đẩy dữ liệu vào các hệ thống lưu trữ chuyên dụng khác (như PostgreSQL, Elasticsearch, hoặc HDFS) để lưu trữ lâu dài và phân tích sâu.
- Thiết kế hệ thống tiêu thụ dữ liệu phù hợp: Logic của Consumer rất quan trọng. Hãy đảm bảo bạn xử lý các trường hợp lỗi một cách hợp lý. Cân nhắc về ngữ nghĩa xử lý tin nhắn: “at-most-once”, “at-least-once”, hay “exactly-once” tùy thuộc vào yêu cầu của ứng dụng. Ví dụ, với các giao dịch tài chính, bạn sẽ cần đảm bảo xử lý chính xác một lần (exactly-once) để tránh mất tiền hoặc ghi nhận trùng lặp.
Conclusion
Qua một hành trình chi tiết, chúng ta đã cùng nhau khám phá Kafka là gì, từ khái niệm cơ bản, kiến trúc cốt lõi cho đến các ứng dụng thực tiễn đầy ấn tượng. Có thể thấy, Apache Kafka không chỉ đơn thuần là một hàng đợi tin nhắn, mà là một nền tảng streaming sự kiện phân tán toàn diện, đóng vai trò xương sống cho việc xử lý dữ liệu thời gian thực trong kỷ nguyên số. Nó cho phép các doanh nghiệp xây dựng những hệ thống linh hoạt, có khả năng mở rộng và phản ứng tức thì với dòng chảy dữ liệu không ngừng.
Với khả năng xử lý thông lượng khổng lồ, độ trễ thấp và tính chịu lỗi cao, Kafka đã chứng minh được giá trị không thể thiếu trong các bài toán từ tích hợp microservices, xây dựng đường ống dữ liệu, cho đến phân tích hành vi người dùng trực tiếp. Mặc dù việc triển khai và vận hành đòi hỏi sự đầu tư về kiến thức, nhưng lợi ích mà nó mang lại cho các dự án lớn là vô cùng xứng đáng. AZWEB tin rằng việc nắm vững công nghệ này sẽ mở ra rất nhiều cơ hội cho các nhà phát triển và kiến trúc sư hệ thống.
Nếu bạn cảm thấy hứng thú và muốn đi sâu hơn vào thế giới của Kafka, đừng ngần ngại. Bước tiếp theo cho bạn là hãy tham khảo các tài liệu chính thức trên trang chủ của Apache Kafka và thử cài đặt, vận hành một cụm Kafka nhỏ theo hướng dẫn. Trải nghiệm thực tế chính là cách tốt nhất để biến lý thuyết thành kỹ năng. Chúc bạn thành công trên con đường chinh phục dòng chảy dữ liệu cùng Apache Kafka