Trong thế giới công nghệ luôn thay đổi, các giao diện lập trình ứng dụng (API là gì) đóng vai trò xương sống cho hầu hết các ứng dụng hiện đại. Tuy nhiên, khi nhu cầu ngày càng phức tạp, công nghệ truy vấn API truyền thống như RESTful API là gì bắt đầu bộc lộ những hạn chế. Lập trình viên thường xuyên đối mặt với tình trạng “over-fetching” (lấy quá nhiều dữ liệu) hoặc “under-fetching” (phải gọi nhiều request để lấy đủ dữ liệu), gây lãng phí tài nguyên và làm chậm ứng dụng. Đây chính là lúc GraphQL xuất hiện như một giải pháp đột phá. Được phát triển bởi Facebook, GraphQL mang đến một cách tiếp cận linh hoạt, cho phép client yêu cầu chính xác những gì họ cần. Bài viết này của AZWEB sẽ cùng bạn tìm hiểu GraphQL là gì, cách nó hoạt động, những ưu điểm vượt trội so với REST API và cách ứng dụng vào các dự án thực tế.
Định nghĩa GraphQL và tổng quan về công nghệ truy vấn API
Để hiểu rõ sức mạnh của GraphQL, trước tiên chúng ta cần nắm vững khái niệm cơ bản và vai trò của công nghệ truy vấn API trong thế giới phần mềm.
GraphQL là gì?
GraphQL là một ngôn ngữ truy vấn cho API và cũng là một môi trường thực thi phía máy chủ để thực hiện các truy vấn đó. Nó được Facebook phát triển nội bộ vào năm 2012 và phát hành công khai vào năm 2015. Không giống như REST API có cấu trúc cứng nhắc với nhiều endpoint khác nhau, GraphQL chỉ sử dụng một endpoint duy nhất.
Điểm khác biệt cốt lõi nằm ở chỗ GraphQL cho phép client định rõ cấu trúc dữ liệu mà họ muốn nhận về. Thay vì nhận một gói dữ liệu cố định từ server, client sẽ gửi một “query” mô tả chi tiết các trường thông tin cần thiết. Server sẽ dựa vào query này để trả về một file JSON với cấu trúc tương ứng. Cách tiếp cận này giúp loại bỏ hoàn toàn tình trạng thừa hoặc thiếu dữ liệu, một vấn đề phổ biến của REST.

Tổng quan về công nghệ truy vấn API
API (Application Programming Interface) là cầu nối giao tiếp giữa các thành phần phần mềm khác nhau. Trong ứng dụng web, API thường đóng vai trò trung gian giữa client (giao diện người dùng) và server (nơi lưu trữ và xử lý dữ liệu). Client gửi yêu cầu (request) đến API để lấy hoặc thay đổi dữ liệu, và server phản hồi (response) lại.
Sự phát triển của công nghệ API đã trải qua nhiều giai đoạn, từ SOAP đến REST và bây giờ là GraphQL. REST (Representational State Transfer) đã từng là tiêu chuẩn vàng trong nhiều năm nhờ sự đơn giản và kiến trúc linh hoạt. Tuy nhiên, với sự bùng nổ của các ứng dụng di động và thiết bị IoT, nhu cầu về hiệu suất và tính linh hoạt ngày càng cao. GraphQL ra đời như một bước tiến hóa tự nhiên, giải quyết những nhược điểm cố hữu của REST, giúp tối ưu hóa luồng dữ liệu và mang lại trải nghiệm tốt hơn cho cả lập trình viên lẫn người dùng cuối.
Ưu điểm của GraphQL so với REST API truyền thống
GraphQL không chỉ là một sự thay thế, mà là một cải tiến đáng kể so với REST API. Những ưu điểm của nó tập trung vào việc tăng hiệu suất, cải thiện trải nghiệm cho lập trình viên và mang lại sự linh hoạt vượt trội.
Lấy dữ liệu linh hoạt và tối ưu
Đây là lợi ích nổi bật nhất của GraphQL. Với REST, bạn thường phải gọi đến nhiều endpoint khác nhau để thu thập đủ thông tin cho một màn hình ứng dụng. Ví dụ, để hiển thị thông tin người dùng và danh sách bài viết của họ, bạn có thể phải gọi `/users/<id>` và `/users/<id>/posts`. Quá trình này được gọi là “under-fetching”. Ngược lại, một endpoint như `/users/<id>` có thể trả về quá nhiều thông tin không cần thiết (ngày sinh, địa chỉ,…) trong khi bạn chỉ cần tên người dùng. Đây là “over-fetching”.
GraphQL giải quyết cả hai vấn đề này một cách triệt để. Client có thể gửi một truy vấn duy nhất để lấy chính xác thông tin người dùng và danh sách bài viết của họ cùng lúc. Bạn chỉ định rõ các trường mình cần (ví dụ: name, email, và posts { title }), và server sẽ trả về đúng những dữ liệu đó. Điều này giúp giảm đáng kể số lượng request và dung lượng dữ liệu truyền tải, đặc biệt quan trọng cho các ứng dụng di động có kết nối mạng không ổn định.
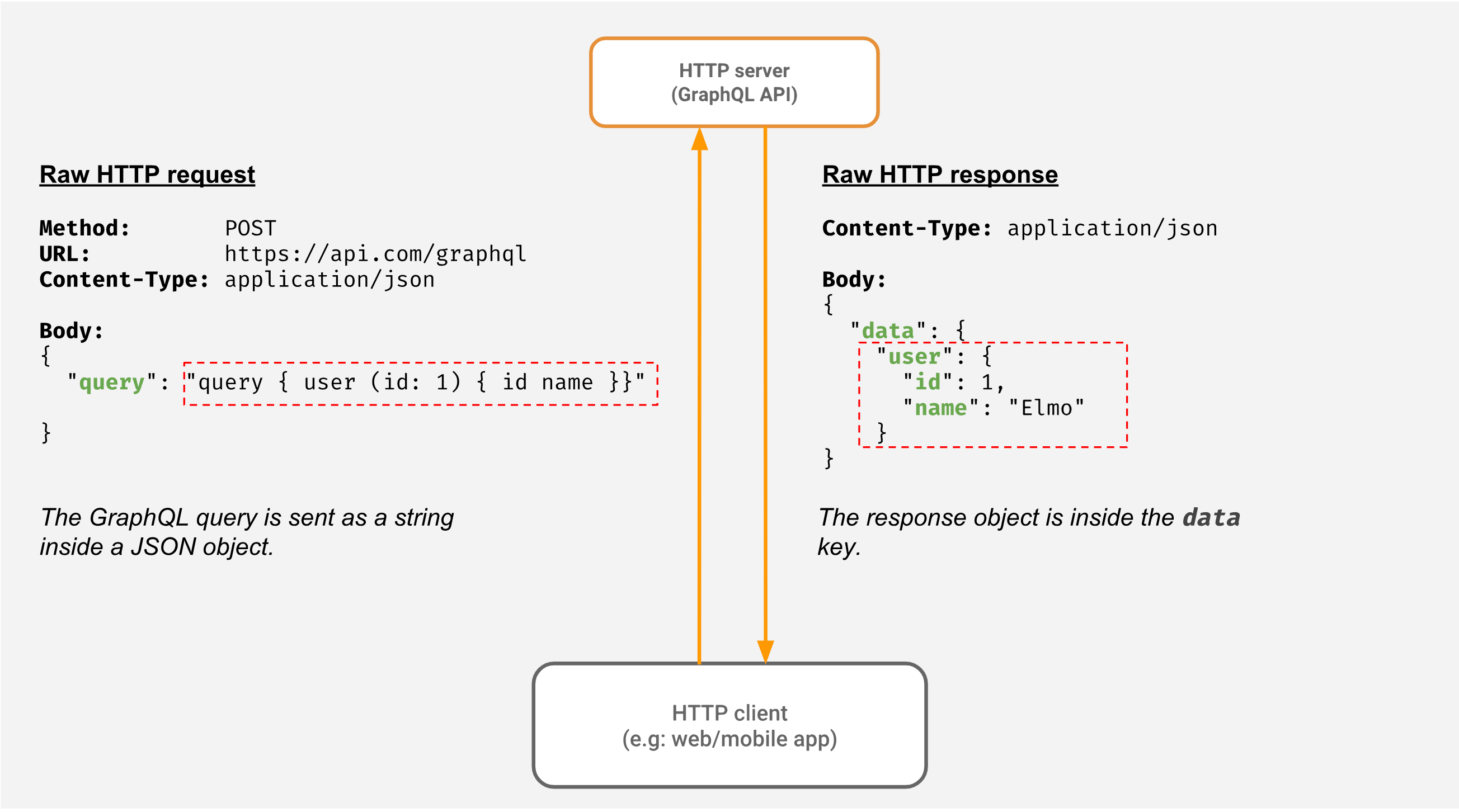
Cấu trúc và kiểu dữ liệu rõ ràng
GraphQL sử dụng một hệ thống kiểu mạnh (strongly-typed system) thông qua Schema Definition Language (SDL). Schema hoạt động như một “hợp đồng” giữa client và server, định nghĩa rõ ràng mọi loại dữ liệu, các trường có sẵn và các thao tác (query, mutation) có thể thực hiện.
Sự rõ ràng này mang lại nhiều lợi ích. Lập trình viên frontend biết chính xác dữ liệu nào có thể truy vấn và cấu trúc của nó sẽ như thế nào. Lỗi cú pháp trong truy vấn sẽ được phát hiện ngay lập tức thay vì gây ra lỗi không mong muốn ở phía server. Đối với backend, schema giúp việc bảo trì và mở rộng API trở nên dễ dàng hơn rất nhiều. Mọi thay đổi đều được ghi lại trong schema, giúp các nhóm phát triển đồng bộ và tránh phá vỡ các chức năng hiện có. Nhờ vậy, quá trình phát triển trở nên nhanh chóng và ít lỗi hơn.

Cách hoạt động cơ bản của GraphQL
Hiểu được cách GraphQL hoạt động sẽ giúp bạn khai thác tối đa sức mạnh của nó. Về cơ bản, mọi tương tác trong GraphQL đều xoay quanh việc định nghĩa dữ liệu qua Schema và thực hiện các thao tác thông qua Query và Mutation.
Query và Mutation trong GraphQL
Trong GraphQL, có hai loại thao tác chính bạn cần biết:
- Query (Truy vấn): Dùng để đọc hoặc lấy dữ liệu. Khi bạn cần hiển thị thông tin, bạn sẽ sử dụng query. Một query cho phép bạn chỉ định chính xác các đối tượng và các trường bạn muốn nhận về. Ví dụ, bạn có thể viết một query để lấy tên và email của một người dùng cụ thể.
- Mutation (Thay đổi): Dùng để ghi, tạo mới, cập nhật hoặc xóa dữ liệu. Bất cứ khi nào bạn muốn thay đổi thông tin trên server, bạn sẽ dùng mutation. Về cú pháp, mutation trông rất giống query, nhưng nó được thiết kế để thể hiện rõ ý định là một hành động gây ra sự thay đổi.
Ví dụ, một truy vấn đơn giản để lấy thông tin sản phẩm có thể trông như sau:
query {
product(id: "123") {
name
price
description
}
}
Server sẽ trả về một đối tượng JSON chỉ chứa name, price, và description của sản phẩm có ID “123”.

Các thành phần chính trong GraphQL
Một hệ thống GraphQL hoàn chỉnh được cấu thành từ ba thành phần cốt lõi:
- Schema: Đây là bản thiết kế của API. Schema định nghĩa tất cả các loại dữ liệu (ví dụ:
User,Product,Post), các trường trong mỗi loại và mối quan hệ giữa chúng. Nó cũng xác định các query và mutation nào được phép thực hiện. Schema là nguồn sự thật duy nhất (single source of truth), đảm bảo client và server luôn “hiểu” nhau. - Resolver: Đây là các hàm ở phía server chịu trách nhiệm lấy dữ liệu cho từng trường trong schema. Khi một query được gửi đến, GraphQL server sẽ duyệt qua từng trường trong query và gọi resolver tương ứng để lấy dữ liệu. Resolver có thể lấy dữ liệu từ bất kỳ đâu: cơ sở dữ liệu SQL, NoSQL, một REST API khác, hoặc thậm chí là một giá trị được mã hóa cứng. Sự linh hoạt của resolver giúp GraphQL có thể hoạt động như một lớp trung gian hợp nhất nhiều nguồn dữ liệu khác nhau.
- Query và Mutation: Như đã giải thích ở trên, đây là các ngôn ngữ thao tác mà client sử dụng để tương tác với dữ liệu được định nghĩa trong schema.
Ba thành phần này phối hợp nhịp nhàng với nhau: client gửi một query, server xác thực nó dựa trên schema, sau đó thực thi các resolver tương ứng để thu thập và trả về dữ liệu.
Ứng dụng của GraphQL trong phát triển ứng dụng web hiện đại
Với những ưu điểm vượt trội, GraphQL đang ngày càng được áp dụng rộng rãi trong các dự án phát triển web, từ các startup năng động đến những gã khổng lồ công nghệ.
Tích hợp GraphQL trong frontend và backend
GraphQL không phải là một công nghệ độc quyền cho backend hay frontend, mà là một cầu nối hiệu quả giữa hai thế giới này.
- Phía Frontend: Các thư viện frontend phổ biến như React JS là gì, Vuejs là gì, và Angular là gì đều có hệ sinh thái hỗ trợ GraphQL mạnh mẽ. Các công cụ như Apollo Client và Relay giúp việc gửi query, quản lý state và caching dữ liệu trở nên cực kỳ đơn giản. Lập trình viên frontend có thể tự do lấy dữ liệu mình cần mà không cần chờ backend tạo ra các endpoint mới. Điều này thúc đẩy sự độc lập và tăng tốc độ phát triển giao diện.
- Phía Backend: GraphQL có thể được triển khai với hầu hết các ngôn ngữ lập trình như JavaScript (Node.js là gì), Python, Ruby, Java, Go… Các thư viện như Apollo Server, Express-GraphQL giúp việc xây dựng một server GraphQL trở nên nhanh chóng. Các resolver trong server sẽ kết nối với cơ sở dữ liệu (MongoDB là gì, PostgreSQL, MySQL…) hoặc các dịch vụ microservices là gì khác để lấy dữ liệu. Kiến trúc này cho phép GraphQL đóng vai trò như một “API Gateway”, hợp nhất nhiều nguồn dữ liệu phức tạp thành một API duy nhất, gọn gàng.
Lợi ích khi sử dụng GraphQL cho dự án thực tế
Việc áp dụng GraphQL vào một dự án mang lại nhiều giá trị hữu hình:
- Tăng tốc độ phát triển: Nhờ schema rõ ràng và khả năng truy vấn linh hoạt, đội ngũ frontend và backend có thể làm việc song song hiệu quả hơn. Frontend không còn bị chặn bởi việc chờ đợi API từ backend. Các công cụ tự động tạo tài liệu từ schema cũng giúp giảm thời gian giao tiếp và tìm hiểu API.
- Trải nghiệm người dùng tốt hơn: Vì client chỉ tải những dữ liệu cần thiết, ứng dụng sẽ chạy nhanh hơn và phản hồi mượt mà hơn. Thời gian tải trang giảm, dữ liệu được cập nhật tức thì, mang lại trải nghiệm liền mạch cho người dùng cuối. Điều này đặc biệt quan trọng trên các thiết bị di động có băng thông hạn chế.
- Dễ dàng bảo trì và mở rộng: Schema đóng vai trò như một tài liệu sống. Việc thêm các trường mới vào API không làm ảnh hưởng đến các client cũ. Việc loại bỏ các trường không còn sử dụng cũng trở nên an toàn hơn nhờ các công cụ phân tích. Điều này giúp hệ thống phát triển bền vững theo thời gian.
Với các giải pháp thiết kế website chuyên nghiệp tại AZWEB, chúng tôi luôn tư vấn và áp dụng những công nghệ tiên tiến như GraphQL để đảm bảo sản phẩm cuối cùng không chỉ đẹp về giao diện mà còn mạnh mẽ và hiệu quả về hiệu năng.
Ví dụ minh họa truy vấn và lấy dữ liệu với GraphQL
Lý thuyết sẽ dễ hiểu hơn khi đi kèm với các ví dụ thực tế. Dưới đây là cách bạn có thể sử dụng query và mutation trong GraphQL để tương tác với dữ liệu.
Ví dụ truy vấn đơn giản
Giả sử chúng ta có một ứng dụng blog và cần hiển thị thông tin của một người dùng cùng với tiêu đề ba bài viết gần nhất của họ.
Cấu trúc câu query:
Thay vì phải gọi hai API riêng biệt (RESTful API là gì), với GraphQL, bạn chỉ cần một query duy nhất:
query GetUserAndPosts {
user(id: "1") {
name
email
posts(last: 3) {
title
}
}
}
Trong query này, chúng ta yêu cầu đối tượng user có id là “1”. Từ người dùng đó, chúng ta muốn lấy name và email. Đồng thời, chúng ta cũng yêu cầu danh sách posts, chỉ lấy 3 bài cuối cùng (last: 3), và trong mỗi bài viết, chúng ta chỉ cần trường title.
Mô tả kết quả trả về:
Server GraphQL sẽ xử lý query này và trả về một đối tượng JSON có cấu trúc chính xác như những gì bạn đã yêu cầu:
{
"data": {
"user": {
"name": "Nguyễn Văn A",
"email": "nguyenvana@example.com",
"posts": [
{
"title": "GraphQL là gì?"
},
{
"title": "Bắt đầu với ReactJS"
},
{
"title": "Tối ưu hiệu năng website"
}
]
}
}
}
Kết quả này gọn gàng, không có dữ liệu thừa, và được lấy về chỉ bằng một request duy nhất.

Ví dụ mutation chỉnh sửa dữ liệu
Bây giờ, giả sử người dùng muốn cập nhật tên của họ. Chúng ta sẽ sử dụng một mutation.
Ví dụ cập nhật thông tin người dùng:
Một mutation để cập nhật tên người dùng sẽ trông như sau:
mutation UpdateUserName {
updateUser(id: "1", newName: "Nguyễn Văn B") {
id
name
email
}
}
Ở đây, updateUser là tên của mutation. Chúng ta truyền vào các tham số là id của người dùng cần cập nhật và newName là tên mới. Điều thú vị là sau khi thực hiện thay đổi, bạn cũng có thể yêu cầu GraphQL trả về trạng thái mới của đối tượng. Trong ví dụ này, chúng ta yêu cầu trả về id, name và email mới của người dùng vừa được cập nhật.
Cách xử lý lỗi trong mutation:
GraphQL có cơ chế xử lý lỗi rất tường minh. Nếu có lỗi xảy ra trong quá trình thực thi mutation (ví dụ: id người dùng không tồn tại, dữ liệu không hợp lệ), server sẽ không trả về data mà thay vào đó là một mảng errors mô tả chi tiết vấn đề.
{
"errors": [
{
"message": "User with id 1 not found.",
"locations": [ { "line": 2, "column": 3 } ],
"path": [ "updateUser" ]
}
],
"data": null
}
Cơ chế này giúp client dễ dàng bắt lỗi và hiển thị thông báo phù hợp cho người dùng.

Các vấn đề thường gặp và cách khắc phục
Mặc dù GraphQL rất mạnh mẽ, nhưng trong quá trình sử dụng, bạn có thể gặp phải một số vấn đề. Hiểu rõ chúng và cách khắc phục sẽ giúp bạn xây dựng các ứng dụng ổn định và hiệu quả hơn.
Lỗi truy vấn sai định dạng hoặc thiếu trường dữ liệu
Đây là lỗi phổ biến nhất khi mới bắt đầu. Do GraphQL có hệ thống kiểu và schema nghiêm ngặt, bất kỳ sai sót nào trong cú pháp query cũng sẽ bị từ chối.
- Nguyên nhân: Lỗi này thường xảy ra do gõ sai tên trường, truy vấn một trường không tồn tại trong schema, hoặc định dạng query không đúng (thiếu dấu ngoặc, sai kiểu dữ liệu tham số).
- Cách khắc phục:
- Sử dụng công cụ hỗ trợ: Các môi trường phát triển tích hợp (IDE) như VS Code với các extension GraphQL có thể cung cấp tính năng tự động hoàn thành (autocomplete) và kiểm tra lỗi cú pháp ngay khi bạn gõ.
- Công cụ Playground/GraphiQL: Hầu hết các server GraphQL đều cung cấp một giao diện web tương tác (như GraphiQL) cho phép bạn viết và thử nghiệm query. Nó sẽ tự động kiểm tra lỗi và hiển thị tài liệu schema, giúp bạn dễ dàng debug và xây dựng query đúng.
- Kiểm tra lại schema: Luôn đối chiếu query của bạn với schema để đảm bảo bạn đang yêu cầu đúng các trường và đối tượng đã được định nghĩa.
Vấn đề hiệu năng khi truy vấn phức tạp
GraphQL cho phép client yêu cầu rất nhiều dữ liệu trong một query duy nhất, nhưng đây cũng có thể là một con dao hai lưỡi nếu không được quản lý cẩn thận. Một query quá phức tạp hoặc lồng nhau quá sâu có thể gây áp lực lớn lên server và cơ sở dữ liệu.
- Nguyên nhân: Vấn đề nổi tiếng nhất là “N+1 query”. Ví dụ, khi bạn truy vấn danh sách 100 người dùng và thông tin bài viết của mỗi người, resolver có thể thực hiện 1 truy vấn để lấy 100 người dùng, sau đó thực hiện thêm 100 truy vấn riêng lẻ để lấy bài viết cho từng người, tổng cộng là 101 truy vấn.
- Cách khắc phục:
- Batching (Gộp yêu cầu): Sử dụng một thư viện như DataLoader (trong môi trường Node.js) để gộp nhiều yêu cầu lấy dữ liệu cá nhân thành một yêu cầu duy nhất. Thay vì thực hiện 100 truy vấn riêng lẻ, DataLoader sẽ thu thập tất cả các ID cần thiết và thực hiện một truy vấn duy nhất (ví dụ:
SELECT * FROM posts WHERE user_id IN (...)). - Caching (Bộ nhớ đệm): Lưu trữ kết quả của các truy vấn thường xuyên được yêu cầu vào bộ nhớ đệm (caching) ở cả phía client và server. Điều này giúp giảm số lần phải truy cập vào cơ sở dữ liệu.
- Giới hạn độ sâu và độ phức tạp của query: Server có thể được cấu hình để từ chối các query vượt quá một độ sâu hoặc độ phức tạp nhất định, ngăn chặn các truy vấn lạm dụng có thể làm sập hệ thống.
- Batching (Gộp yêu cầu): Sử dụng một thư viện như DataLoader (trong môi trường Node.js) để gộp nhiều yêu cầu lấy dữ liệu cá nhân thành một yêu cầu duy nhất. Thay vì thực hiện 100 truy vấn riêng lẻ, DataLoader sẽ thu thập tất cả các ID cần thiết và thực hiện một truy vấn duy nhất (ví dụ:

Các best practices khi sử dụng GraphQL
Để khai thác tối đa tiềm năng của GraphQL và xây dựng một hệ thống API bền vững, việc tuân thủ các nguyên tắc và thực hành tốt nhất là vô cùng quan trọng.
- Thiết kế schema rõ ràng, dễ mở rộng: Schema là trái tim của GraphQL API. Hãy dành thời gian để thiết kế nó một cách cẩn thận. Sử dụng tên gọi nhất quán, mô tả rõ ràng cho các trường và kiểu dữ liệu. Hãy suy nghĩ về tương lai, thiết kế schema sao cho việc thêm các tính năng mới không làm phá vỡ các client hiện tại.
- Tránh truy vấn quá sâu hoặc quá phức tạp: Trao quyền cho client không có nghĩa là cho phép họ làm mọi thứ. Hãy triển khai các cơ chế để giới hạn độ sâu của các truy vấn lồng nhau và phân tích độ phức tạp của query trước khi thực thi. Điều này giúp bảo vệ server khỏi các yêu cầu độc hại hoặc không hiệu quả.
- Sử dụng phân trang và giới hạn dữ liệu trả về: Đối với các danh sách có thể chứa nhiều mục (như danh sách bài viết, sản phẩm), đừng bao giờ trả về tất cả trong một lần. Luôn luôn triển khai phân trang (pagination), thường là sử dụng con trỏ (cursor-based) hoặc offset/limit. Điều này đảm bảo hiệu suất và trải nghiệm người dùng tốt hơn.
- Kiểm soát bảo mật truy cập bằng authorization / authentication: GraphQL không có sẵn cơ chế xác thực (authentication) và phân quyền (authorization). Bạn phải tự triển khai nó. Xác định người dùng là ai (authentication) trước khi họ có thể thực hiện bất kỳ truy vấn nào. Sau đó, trong mỗi resolver, hãy kiểm tra xem người dùng đó có quyền truy cập vào dữ liệu hoặc thực hiện hành động đó không (authorization). Ví dụ, một người dùng không thể chỉnh sửa bài viết của người khác.
Việc tuân thủ những nguyên tắc này không chỉ giúp API của bạn an toàn và hiệu quả mà còn giúp quá trình bảo trì và phát triển trong tương lai trở nên dễ dàng hơn rất nhiều.

Kết luận
Qua bài viết này, AZWEB đã cùng bạn khám phá một cách toàn diện về GraphQL – từ định nghĩa cơ bản, cách hoạt động, cho đến những ưu điểm vượt trội so với REST API truyền thống. Chúng ta đã thấy GraphQL giải quyết hiệu quả các vấn đề về “over-fetching” và “under-fetching” bằng cách cho phép client yêu cầu chính xác dữ liệu họ cần, giúp tối ưu hóa hiệu suất và tăng tốc độ phát triển ứng dụng. Với cấu trúc schema mạnh mẽ và hệ sinh thái công cụ hỗ trợ phong phú, GraphQL đang khẳng định vị thế là một công nghệ không thể thiếu trong các dự án web hiện đại.
Nếu bạn là một lập trình viên đang tìm cách xây dựng các ứng dụng nhanh hơn, linh hoạt hơn và dễ bảo trì hơn, đây chính là thời điểm thích hợp để bắt đầu tìm hiểu và áp dụng GraphQL. Đừng ngần ngại thử nghiệm với một dự án nhỏ hoặc tích hợp nó vào một phần của hệ thống hiện tại. Sức mạnh và sự linh hoạt mà nó mang lại chắc chắn sẽ làm bạn bất ngờ.
Để nâng cao kiến thức, bạn có thể tham khảo thêm các tài liệu chính thức từ trang chủ GraphQL, khám phá các khóa học trực tuyến và tham gia vào cộng đồng các nhà phát triển để học hỏi kinh nghiệm thực tế. AZWEB tin rằng việc nắm vững GraphQL sẽ là một lợi thế cạnh tranh lớn trên con đường sự nghiệp của bạn.