Chào bạn, trong kỷ nguyên số mà chúng ta đang sống, dữ liệu được ví như “mỏ vàng” mới. Mỗi ngày, hàng tỷ gigabyte dữ liệu được tạo ra từ website, ứng dụng di động, mạng xã hội và các hệ thống doanh nghiệp. Nhưng làm thế nào để khai thác “mỏ vàng” đó một cách hiệu quả? Việc quản lý, tìm kiếm và phân tích khối lượng thông tin khổng lồ này đặt ra một thách thức không hề nhỏ. Đây chính là lúc Elasticsearch xuất hiện như một giải pháp cứu cánh. Vậy Elasticsearch là gì? Nó không chỉ là một công cụ tìm kiếm, mà còn là một hệ thống phân tích dữ liệu mạnh mẽ, giúp bạn tìm thấy thông tin cần thiết chỉ trong tích tắc. Bài viết này của AZWEB sẽ cùng bạn khám phá từ A-Z về Elasticsearch: từ cấu trúc, nguyên lý hoạt động, các tính năng nổi bật, cho đến ứng dụng thực tế và hướng dẫn cài đặt cơ bản.
Giới thiệu về Elasticsearch là gì
Bạn đã bao giờ tự hỏi làm thế nào các trang thương mại điện tử lớn có thể trả về kết quả tìm kiếm sản phẩm gần như ngay lập tức, dù bạn gõ sai chính tả? Hoặc làm thế nào các quản trị viên hệ thống có thể theo dõi hàng triệu dòng log mỗi phút để phát hiện sự cố? Câu trả lời thường nằm ở một công nghệ cốt lõi: Elasticsearch.
Sự bùng nổ của Big Data đã tạo ra một nhu cầu cấp thiết về các công cụ có khả năng xử lý nhanh và thông minh. Các hệ quản trị cơ sở dữ liệu truyền thống, dù rất mạnh mẽ, lại thường gặp khó khăn khi phải đối mặt với các tác vụ tìm kiếm văn bản phức tạp hoặc phân tích dữ liệu phi cấu trúc trên quy mô lớn. Vấn đề chính là tốc độ và sự linh hoạt. Khi dữ liệu của bạn lên đến hàng terabyte hoặc petabyte, một truy vấn đơn giản cũng có thể mất hàng giờ để hoàn thành.
Đây là lúc Elasticsearch tỏa sáng. Được xây dựng dựa trên Apache Lucene, Elasticsearch là một công cụ tìm kiếm và phân tích dữ liệu phân tán, mã nguồn mở. Nó cho phép bạn lưu trữ, tìm kiếm và phân tích khối lượng dữ liệu khổng lồ theo thời gian thực. Hãy tưởng tượng nó như một “Google” dành riêng cho dữ liệu của bạn, cực kỳ nhanh chóng và thông minh. Trong bài viết này, chúng ta sẽ đi sâu vào cấu trúc cốt lõi, khám phá các tính năng mạnh mẽ, xem xét các ứng dụng thực tế, phân tích ưu nhược điểm và hướng dẫn bạn các bước cài đặt đầu tiên để bắt đầu hành trình chinh phục công cụ này.

Cấu trúc và nguyên lý hoạt động của Elasticsearch
Để hiểu tại sao Elasticsearch lại mạnh mẽ đến vậy, chúng ta cần nhìn vào kiến trúc nền tảng của nó. Sức mạnh của Elasticsearch không đến từ một thành phần duy nhất mà là sự kết hợp hài hòa của một hệ thống được thiết kế để mở rộng và chịu lỗi.
Kiến trúc phân tán và mô hình cluster
Elasticsearch hoạt động dựa trên một kiến trúc phân tán. Thay vì lưu trữ tất cả dữ liệu trên một máy chủ duy nhất, nó phân phối dữ liệu và khối lượng công việc trên nhiều máy chủ. Các máy chủ này được gọi là node và chúng kết hợp với nhau để tạo thành một cluster.
- Node: Là một thực thể máy chủ đơn lẻ trong cluster, chịu trách nhiệm lưu trữ dữ liệu và tham gia vào quá trình lập chỉ mục (indexing) và tìm kiếm.
- Cluster: Là một tập hợp các node làm việc cùng nhau, chia sẻ dữ liệu và tải. Khi bạn gửi yêu cầu đến cluster, nó sẽ tự động điều phối công việc đến các node phù hợp.
- Shard (Phân mảnh): Vì dữ liệu có thể rất lớn, Elasticsearch chia một chỉ mục (index) thành các phần nhỏ hơn gọi là shard. Mỗi shard là một chỉ mục Lucene độc lập và có thể được lưu trữ trên bất kỳ node nào trong cluster. Việc này cho phép bạn mở rộng theo chiều ngang – khi dữ liệu tăng lên, bạn chỉ cần thêm node mới và Elasticsearch sẽ tự động phân bổ lại các shard.
- Replica (Bản sao): Để đảm bảo tính sẵn sàng cao và phòng tránh mất mát dữ liệu, mỗi shard có thể có một hoặc nhiều bản sao, gọi là replica. Replica không bao giờ được đặt trên cùng một node với shard gốc. Nếu một node gặp sự cố, Elasticsearch sẽ tự động sử dụng replica trên một node khác để phục vụ yêu cầu, đảm bảo hệ thống hoạt động không gián đoạn.

Mô hình này mang lại sự linh hoạt và khả năng chịu lỗi vượt trội. Bạn có thể bắt đầu với một node duy nhất và dễ dàng mở rộng thành một cluster hàng trăm node khi nhu cầu tăng lên.
Nguyên lý lập chỉ mục và tìm kiếm tương tự như full-text search
Điều làm nên tốc độ “thần sầu” của Elasticsearch chính là cách nó lập chỉ mục dữ liệu. Thay vì quét toàn bộ văn bản mỗi khi có yêu cầu tìm kiếm (như một số cơ sở dữ liệu truyền thống), Elasticsearch sử dụng một cấu trúc gọi là inverted index (chỉ mục đảo ngược).
Hãy tưởng tượng bạn có một cuốn sách. Thay vì đọc từ đầu đến cuối để tìm một từ khóa, bạn sẽ lật đến phần chỉ mục ở cuối sách. Phần chỉ mục này liệt kê tất cả các từ khóa quan trọng và số trang chứa chúng. Inverted index hoạt động theo nguyên lý tương tự.
Khi bạn đưa một tài liệu (ví dụ: một bài viết blog, một mô tả sản phẩm) vào Elasticsearch, nó sẽ:
- Phân tích (Analyze): Tách văn bản thành các từ riêng lẻ (gọi là token).
- Chuẩn hóa (Normalize): Chuyển các token về dạng chuẩn (ví dụ: viết thường, loại bỏ các từ không quan trọng như “là”, “và”, “thì”).
- Lập chỉ mục (Index): Tạo ra một danh sách các từ đã chuẩn hóa và ghi lại ID của tất cả các tài liệu chứa từ đó.
Khi bạn thực hiện một truy vấn tìm kiếm, Elasticsearch không cần phải duyệt qua từng tài liệu. Thay vào đó, nó chỉ cần tra cứu từ khóa của bạn trong inverted index, lấy ra danh sách ID các tài liệu phù hợp và trả về kết quả gần như tức thì. Đây chính là bí mật đằng sau khả năng tìm kiếm full-text search mạnh mẽ và nhanh chóng của nó.

Tính năng chính của Elasticsearch trong tìm kiếm và phân tích dữ liệu
Elasticsearch không chỉ dừng lại ở việc tìm kiếm nhanh. Nó còn cung cấp một bộ công cụ phân tích dữ liệu vô cùng đa dạng, giúp bạn khai thác sâu hơn những thông tin giá trị ẩn sau các con số và văn bản.
Tìm kiếm full-text và truy vấn đa dạng
Đây là tính năng cốt lõi và nổi bật nhất của Elasticsearch. Nó vượt xa khả năng tìm kiếm từ khóa đơn giản. Bạn có thể thực hiện các truy vấn phức tạp để trích xuất thông tin một cách chính xác nhất.
- Full-Text Search: Tìm kiếm không chỉ dựa trên sự trùng khớp chính xác mà còn cả mức độ liên quan. Elasticsearch có thể xử lý các yếu tố như lỗi chính tả (fuzzy search), từ đồng nghĩa, và thậm chí hiểu được ý định của người dùng. Ví dụ, tìm kiếm “giày chạy bộ” có thể trả về kết quả chứa cả “giày điền kinh”.
- Truy vấn phức hợp (Compound Queries): Bạn có thể kết hợp nhiều điều kiện tìm kiếm bằng các toán tử logic như
AND,OR,NOT. Ví dụ: tìm tất cả sản phẩm “laptop” của thương hiệu “Dell” có giá dưới “20 triệu” và còn hàng. - Gợi ý và tự động hoàn thành (Suggestions & Autocomplete): Cung cấp trải nghiệm người dùng mượt mà bằng cách gợi ý các từ khóa tìm kiếm phổ biến ngay khi người dùng bắt đầu gõ.
- Xếp hạng kết quả (Relevance Scoring): Mỗi kết quả trả về đều có một điểm số relevancy, cho biết mức độ phù hợp của nó với truy vấn. Điều này đảm bảo những kết quả quan trọng nhất luôn được hiển thị ở trên cùng.
Phân tích dữ liệu theo thời gian thực
Sức mạnh của Elasticsearch còn được thể hiện qua khả năng phân tích dữ liệu gần như ngay lập tức sau khi nó được đưa vào hệ thống. Tính năng này được thực hiện thông qua Aggregations Framework.
Aggregations cho phép bạn nhóm và trích xuất các số liệu thống kê từ dữ liệu của mình. Bạn có thể coi nó như một công cụ tạo báo cáo siêu mạnh mẽ.
- Metric Aggregations: Tính toán các chỉ số như tổng, trung bình, giá trị lớn nhất/nhỏ nhất, đếm số lượng. Ví dụ: tính doanh thu trung bình của một cửa hàng trong tháng qua.
- Bucket Aggregations: Phân nhóm các tài liệu vào các “xô” (bucket) dựa trên một tiêu chí nào đó, chẳng hạn như theo khoảng giá, theo danh mục sản phẩm, hoặc theo vị trí địa lý.
- Pipeline Aggregations: Thực hiện tính toán trên kết quả của các aggregation khác. Ví dụ: sau khi nhóm doanh thu theo tháng, bạn có thể tính toán tỷ lệ tăng trưởng so với tháng trước.
Khi kết hợp với công cụ trực quan hóa như Kibana (một phần của bộ công cụ ELK Stack), bạn có thể dễ dàng biến những con số khô khan thành các biểu đồ, đồ thị và dashboard sinh động, giúp theo dõi hiệu suất kinh doanh, giám sát sức khỏe hệ thống hoặc phân tích hành vi người dùng trong thời gian thực.
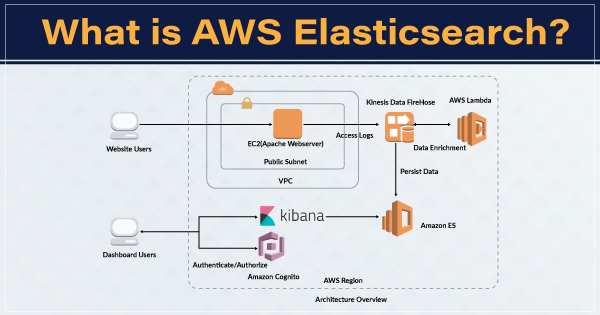
Ứng dụng thực tế của Elasticsearch trong các hệ thống kỹ thuật
Nhờ vào sự linh hoạt và hiệu năng cao, Elasticsearch đã trở thành một thành phần không thể thiếu trong nhiều hệ thống hiện đại, từ các trang web thương mại điện tử cho đến các nền tảng phân tích dữ liệu lớn.
Hỗ trợ tìm kiếm cho website, ứng dụng thương mại điện tử
Đây là một trong những ứng dụng phổ biến nhất của Elasticsearch. Trải nghiệm người dùng trên một trang web hay ứng dụng phụ thuộc rất nhiều vào tốc độ và sự chính xác của chức năng tìm kiếm.
- Tìm kiếm sản phẩm nhanh và chính xác: Hãy tưởng tượng một khách hàng truy cập vào website bán lẻ của bạn, được thiết kế bởi AZWEB, và gõ “giày thể thao nam màu đỏ size 42”. Với Elasticsearch, hệ thống có thể phân tích truy vấn này, áp dụng các bộ lọc về danh mục, giới tính, màu sắc, kích cỡ và trả về kết quả chính xác chỉ trong vài mili giây.
- Gợi ý sản phẩm liên quan: Dựa trên lịch sử tìm kiếm và hành vi của người dùng, Elasticsearch có thể đề xuất các sản phẩm tương tự hoặc các mặt hàng thường được mua cùng nhau, giúp tăng khả năng bán hàng (cross-sell, up-sell).
- Tự động sửa lỗi chính tả và tìm kiếm thông minh: Nếu người dùng gõ nhầm “điện thoai samsung”, Elasticsearch có thể hiểu và trả về kết quả cho “điện thoại Samsung”, giúp giảm tỷ率 thoát trang do tìm kiếm không thành công.
Việc tích hợp Elasticsearch giúp nâng cao đáng kể sự hài lòng của khách hàng và thúc đẩy doanh số bán hàng.

Phân tích log, giám sát hệ thống và bảo mật
Trong lĩnh vực quản trị hệ thống và an ninh mạng, dữ liệu log là nguồn thông tin vô giá. Tuy nhiên, các hệ thống hiện đại tạo ra một lượng log khổng lồ mỗi ngày. Việc phân tích chúng theo cách thủ công là không thể. Đây là nơi bộ ba ELK Stack (Elasticsearch, Logstash, Kibana) phát huy sức mạnh.
- Quản lý và phân tích log tập trung (Centralized Logging): Logstash thu thập log từ nhiều nguồn khác nhau (web server, database, ứng dụng), xử lý và gửi chúng đến Elasticsearch để lưu trữ và lập chỉ mục. Điều này giúp các quản trị viên có một cái nhìn tổng quan về toàn bộ hệ thống từ một nơi duy nhất.
- Giám sát hiệu suất ứng dụng (APM – Application Performance Monitoring): Bằng cách phân tích log và các chỉ số hiệu suất, đội ngũ phát triển có thể nhanh chóng xác định các điểm nghẽn, truy vấn chậm hoặc lỗi phát sinh trong ứng dụng.
- Phát hiện bất thường và phân tích bảo mật (SIEM – Security Information and Event Management): Elasticsearch có thể phân tích các mẫu truy cập và log hệ thống trong thời gian thực để phát hiện các hoạt động đáng ngờ, chẳng hạn như các cuộc tấn công brute-force, quét cổng hoặc các hành vi truy cập trái phép, giúp đội ngũ bảo mật phản ứng kịp thời.
Với các dịch vụ Hosting chất lượng cao và VPS mạnh mẽ từ AZWEB, việc triển khai một hệ thống giám sát dựa trên Elasticsearch sẽ giúp bạn đảm bảo sự ổn định và an toàn cho website và ứng dụng của mình.

Ưu điểm và hạn chế khi sử dụng Elasticsearch
Bất kỳ công nghệ nào cũng có hai mặt, và Elasticsearch cũng không ngoại lệ. Hiểu rõ ưu điểm và hạn chế của nó sẽ giúp bạn quyết định xem đây có phải là giải pháp phù hợp cho dự án của mình hay không.
Ưu điểm nổi bật
Elasticsearch được ưa chuộng rộng rãi nhờ vào những lợi thế vượt trội sau:
- Tốc độ cực nhanh: Nhờ vào inverted index, Elasticsearch có thể thực hiện các truy vấn full-text phức tạp trên hàng tỷ bản ghi và trả về kết quả trong thời gian dưới một giây.
- Khả năng mở rộng linh hoạt: Kiến trúc phân tán cho phép bạn dễ dàng mở rộng hệ thống bằng cách thêm các node mới vào cluster (scale-out). Hệ thống sẽ tự động phân phối lại dữ liệu và tải mà không cần ngừng hoạt động.
- Tính sẵn sàng và chịu lỗi cao: Với cơ chế replica, dữ liệu của bạn được sao lưu trên nhiều node. Nếu một node gặp sự cố, hệ thống vẫn có thể tiếp tục hoạt động bình thường, đảm bảo tính liên tục cho dịch vụ.
- Hỗ trợ đa dạng loại dữ liệu: Elasticsearch có thể xử lý nhiều loại dữ liệu khác nhau, từ văn bản, số, dữ liệu địa lý (geospatial) cho đến dữ liệu có cấu trúc và phi cấu trúc.
- API mạnh mẽ và linh hoạt: Cung cấp RESTful API đơn giản, giúp việc tích hợp với các ngôn ngữ lập trình và ứng dụng khác trở nên dễ dàng.
- Hệ sinh thái phong phú: Là một phần của ELK Stack (cùng với Logstash và Kibana), nó cung cấp một giải pháp toàn diện cho việc thu thập, lưu trữ, tìm kiếm, phân tích và trực quan hóa dữ liệu.
- Cộng đồng lớn và mã nguồn mở: Là một dự án mã nguồn mở, Elasticsearch có một cộng đồng người dùng và nhà phát triển khổng lồ trên toàn thế giới, luôn sẵn sàng hỗ trợ, chia sẻ kinh nghiệm và đóng góp vào sự phát triển của sản phẩm.
Hạn chế cần lưu ý
Bên cạnh những ưu điểm, bạn cũng cần cân nhắc một số thách thức khi làm việc với Elasticsearch:
- Tiêu tốn tài nguyên: Elasticsearch, đặc biệt là các thành phần của nó, khá “ngốn” RAM. Để đảm bảo hiệu suất tốt nhất, bạn cần cung cấp một môi trường phần cứng đủ mạnh.
- Đường cong học tập (Learning Curve): Mặc dù các thao tác cơ bản khá đơn giản, việc thiết kế, cấu hình và tối ưu hóa một cluster Elasticsearch cho các hệ thống lớn và phức tạp đòi hỏi kiến thức chuyên sâu và kinh nghiệm.
- Không hỗ trợ transaction như cơ sở dữ liệu quan hệ: Elasticsearch không được thiết kế để thay thế hoàn toàn các cơ sở dữ liệu quan hệ (như MySQL, PostgreSQL) trong các tác vụ yêu cầu tính toàn vẹn giao dịch (ACID transactions) nghiêm ngặt.
- Split-Brain: Trong một số trường hợp cấu hình mạng không tốt, cluster có thể bị “chia đôi” (split-brain), dẫn đến tình trạng các node không đồng nhất dữ liệu. Việc này đòi hỏi cấu hình cẩn thận để phòng tránh.
Việc lựa chọn Elasticsearch cần dựa trên bài toán cụ thể. Nếu nhu cầu chính của bạn là tìm kiếm, phân tích log, và xử lý dữ liệu lớn, thì đây chắc chắn là một trong những lựa chọn hàng đầu.
Hướng dẫn cài đặt và triển khai cơ bản Elasticsearch
Bạn đã sẵn sàng để tự tay trải nghiệm sức mạnh của Elasticsearch chưa? AZWEB sẽ hướng dẫn bạn các bước cài đặt cơ bản nhất. Quá trình này khá đơn giản và bạn có thể thực hiện ngay trên máy tính cá nhân của mình.
Yêu cầu hệ thống và chuẩn bị môi trường
Trước khi bắt đầu, hãy đảm bảo hệ thống của bạn đáp ứng các yêu cầu sau:
- Hệ điều hành: Elasticsearch có thể chạy trên Linux, MacOS và Windows.
- Java Development Kit (JDK): Elasticsearch được xây dựng bằng Java, vì vậy bạn cần cài đặt JDK. Phiên bản được khuyến nghị thường được ghi rõ trong tài liệu của phiên bản Elasticsearch bạn định cài. Bạn có thể kiểm tra xem Java đã được cài đặt hay chưa bằng lệnh
java -versiontrong terminal hoặc command prompt. - Phần cứng: Đối với mục đích học tập và thử nghiệm, một máy tính có ít nhất 4GB RAM là đủ. Đối với môi trường production, yêu cầu sẽ cao hơn nhiều.
Các bước cơ bản để cài đặt và khởi chạy Elasticsearch
Chúng ta sẽ thực hiện cài đặt trên một môi trường tương tự Linux/MacOS. Các bước trên Windows cũng tương tự.
- Tải xuống Elasticsearch: Truy cập trang web chính thức của Elastic và tải xuống phiên bản Elasticsearch phù hợp với hệ điều hành của bạn. Thường thì bạn sẽ tải về một file nén
.tar.gz(cho Linux/MacOS) hoặc.zip(cho Windows). - Giải nén tệp tin: Sử dụng lệnh
tar -xzf elasticsearch-<version>.tar.gzđể giải nén tệp tin vừa tải về. Sau khi giải nén, bạn sẽ có một thư mụcelasticsearch-<version>. - Cấu hình cơ bản (Tùy chọn nhưng khuyến khích): Di chuyển vào thư mục vừa giải nén, tìm đến thư mục
configvà mở fileelasticsearch.yml. Đây là file cấu hình chính. Để bắt đầu, bạn có thể đặt tên cho cluster và node của mình:cluster.name: my-azweb-clusternode.name: node-1
Việc đặt tên giúp bạn dễ dàng quản lý khi có nhiều cluster hoặc node sau này. - Khởi chạy Elasticsearch: Quay trở lại thư mục gốc của Elasticsearch, di chuyển vào thư mục
bin. Chạy file thực thi để khởi động dịch vụ:./elasticsearch(trên Linux/MacOS)elasticsearch.bat(trên Windows)
Bạn sẽ thấy rất nhiều thông tin log xuất hiện trên màn hình. Nếu không có lỗi nào, Elasticsearch đã khởi động thành công.

- Kiểm tra hoạt động: Mở trình duyệt web hoặc sử dụng một công cụ như
curlvà truy cập vào địa chỉhttp://localhost:9200. Nếu cài đặt thành công, bạn sẽ nhận được một phản hồi JSON chứa thông tin về node và cluster của bạn, tương tự như sau:
{
"name" : "node-1",
"cluster_name" : "my-azweb-cluster",
"cluster_uuid" : "...",
"version" : { ... },
"tagline" : "You Know, for Search"
}
.png)
Chúc mừng! Bạn đã cài đặt thành công một node Elasticsearch đầu tiên. Từ đây, bạn có thể bắt đầu khám phá các API để thêm và truy vấn dữ liệu.
Các vấn đề thường gặp và cách khắc phục
Trong quá trình làm việc với Elasticsearch, đặc biệt là khi mới bắt đầu, bạn có thể gặp phải một số sự cố. Dưới đây là hai vấn đề phổ biến và hướng giải quyết cơ bản.
Elasticsearch không khởi động được do cấu hình sai
Đây là lỗi phổ biến nhất đối với người mới. Bạn chạy lệnh khởi động nhưng tiến trình lại dừng ngay lập tức hoặc báo lỗi.
- Nguyên nhân: Thường là do có lỗi cú pháp trong file cấu hình
elasticsearch.yml. File này sử dụng định dạng YAML, rất nhạy cảm với việc thụt lề (indentation). Một dấu cách thừa hoặc thiếu cũng có thể gây lỗi. Các nguyên nhân khác có thể là do xung đột cổng (port 9200 hoặc 9300 đã bị ứng dụng khác sử dụng) hoặc thiếu quyền truy cập vào thư mục dữ liệu/log. - Cách khắc phục:
- Kiểm tra log: Đây là bước quan trọng nhất. Hãy mở file log của Elasticsearch (thường nằm trong thư mục
logscủa thư mục cài đặt). Log sẽ cho bạn biết chính xác nguyên nhân gây ra lỗi. - Kiểm tra file
elasticsearch.yml: Rà soát lại file cấu hình một cách cẩn thận. Đảm bảo rằng bạn sử dụng dấu cách thay vì tab để thụt lề. Sử dụng một công cụ kiểm tra cú pháp YAML trực tuyến nếu cần. - Kiểm tra cổng: Sử dụng các lệnh như
netstatđể kiểm tra xem cổng 9200 và 9300 có đang được sử dụng hay không. Nếu có, bạn có thể đổi cổng mặc định trong fileelasticsearch.yml.
- Kiểm tra log: Đây là bước quan trọng nhất. Hãy mở file log của Elasticsearch (thường nằm trong thư mục
Hiệu suất chậm khi xử lý khối lượng dữ liệu lớn
Khi dữ liệu của bạn tăng lên, bạn có thể nhận thấy tốc độ truy vấn hoặc lập chỉ mục bắt đầu chậm lại.
- Nguyên nhân: Vấn đề có thể đến từ nhiều phía: tài nguyên phần cứng không đủ (RAM, CPU, I/O ổ đĩa), cấu hình shard và replica không tối ưu, hoặc các truy vấn quá phức tạp gây tải nặng cho cluster.
- Cách khắc phục:
- Tối ưu hóa tài nguyên: Đảm bảo rằng bạn đã cấp đủ bộ nhớ Heap cho Elasticsearch (thông qua file
jvm.options), nhưng không quá 50% tổng RAM của hệ thống. Sử dụng ổ đĩa SSD để tăng tốc độ I/O. - Tối ưu shard và replica: Số lượng shard cho một chỉ mục cần được tính toán cẩn thận ngay từ đầu. Quá nhiều shard nhỏ có thể gây ra overhead, trong khi quá ít shard lớn sẽ làm giảm khả năng phân tán công việc. Điều chỉnh số lượng replica để cân bằng giữa khả năng chịu lỗi và hiệu suất ghi dữ liệu.
- Thêm node (Scaling): Nếu tài nguyên trên một node đã đạt tới giới hạn, hãy xem xét việc thêm node mới vào cluster để phân tán tải.
- Tối ưu truy vấn: Sử dụng API Profile để phân tích các truy vấn chậm và tìm cách tối ưu hóa chúng, ví dụ như tránh sử dụng các truy vấn wildcard ở đầu chuỗi.
- Tối ưu hóa tài nguyên: Đảm bảo rằng bạn đã cấp đủ bộ nhớ Heap cho Elasticsearch (thông qua file

Best Practices khi sử dụng Elasticsearch
Để vận hành một hệ thống Elasticsearch ổn định, hiệu quả và an toàn, việc tuân thủ các best practices là vô cùng quan trọng. Dưới đây là những khuyến nghị từ AZWEB mà bạn nên ghi nhớ.
- Lập kế hoạch phân mảnh (Sharding) hợp lý: Trước khi tạo một chỉ mục lớn, hãy ước tính lượng dữ liệu sẽ lưu trữ để quyết định số lượng shard phù hợp. Một shard nên có kích thước từ vài GB đến vài chục GB. Sau khi chỉ mục được tạo, bạn không thể thay đổi số lượng primary shard.
- Sử dụng alias cho chỉ mục: Thay vì để ứng dụng truy cập trực tiếp vào tên chỉ mục, hãy sử dụng alias (bí danh). Điều này giúp bạn dễ dàng thực hiện các tác vụ bảo trì như reindex dữ liệu sang một chỉ mục mới mà không làm gián đoạn dịch vụ.
- Backup thường xuyên: Dữ liệu là tài sản quý giá. Hãy sử dụng tính năng Snapshot and Restore của Elasticsearch để tạo các bản sao lưu định kỳ và lưu trữ chúng ở một nơi an toàn (như S3, Azure Blob Storage).
- Định kỳ cập nhật và theo dõi trạng thái cluster: Luôn cập nhật Elasticsearch lên các phiên bản mới nhất để nhận được các bản vá lỗi, cải tiến hiệu suất và tính năng bảo mật. Sử dụng các công cụ giám sát (như Kibana Monitoring hoặc Prometheus) để theo dõi sức khỏe của cluster (CPU, RAM, disk space, JVM heap).
- Không lạm dụng các truy vấn phức tạp: Các truy vấn như wildcard ở đầu (ví dụ:
*term), script query hoặc aggregation lồng nhau quá sâu có thể tiêu tốn rất nhiều tài nguyên. Hãy tìm cách tối ưu hoặc hạn chế chúng. - Đảm bảo bảo mật: Đừng bao giờ để một cluster Elasticsearch công khai trên internet mà không có bất kỳ lớp bảo vệ nào. Kích hoạt các tính năng bảo mật của Elastic (X-Pack), sử dụng mật khẩu mạnh, mã hóa giao tiếp (TLS/SSL) và cấu hình quyền truy cập (Role-Based Access Control) để giới hạn quyền của người dùng.
- Tách biệt các loại node: Trong các cluster lớn, hãy xem xét việc sử dụng các node chuyên dụng cho các vai trò khác nhau: master node, data node, ingest node, machine learning node để tối ưu hóa hiệu suất và sự ổn định.

Kết luận
Qua bài viết này, chúng ta đã cùng nhau thực hiện một hành trình khám phá toàn diện về Elasticsearch. Từ việc tìm hiểu Elasticsearch là gì, đi sâu vào cấu trúc phân tán với cluster, node và shard, cho đến việc nắm bắt nguyên lý hoạt động cốt lõi qua inverted index. Chúng ta cũng đã thấy được sức mạnh của nó qua các tính năng tìm kiếm full-text, phân tích dữ liệu thời gian thực và những ứng dụng thực tiễn trong việc nâng cao trải nghiệm người dùng trên website hay giám sát hệ thống.
Elasticsearch không chỉ là một công cụ, mà là một giải pháp mạnh mẽ và thiết yếu trong bối cảnh dữ liệu lớn ngày nay. Việc nắm vững nguyên lý, tính năng và cách triển khai sẽ giúp bạn và doanh nghiệp của mình khai thác tối đa giá trị từ dữ liệu, biến những thông tin thô thành lợi thế cạnh tranh. Mặc dù có những thách thức về tài nguyên và độ phức tạp, nhưng với một cộng đồng hỗ trợ mạnh mẽ và hệ sinh thái phong phú, việc làm chủ Elasticsearch là hoàn toàn trong tầm tay.
AZWEB khuyến khích bạn không chỉ dừng lại ở lý thuyết. Hãy bắt tay vào hành động! Mời bạn bắt đầu cài đặt, thử nghiệm với những bộ dữ liệu của riêng mình và khám phá những khả năng vô tận mà Elasticsearch mang lại. Chúc bạn thành công trên con đường chinh phục dữ liệu.