Bạn đang tìm cách xây dựng một hệ quản trị cơ sở dữ liệu có tính sẵn sàng cao và khả năng chịu lỗi tốt? MySQL Group Replication trên Ubuntu 20.04 chính là giải pháp bạn cần. Công nghệ này cho phép tạo ra một cụm cơ sở dữ liệu đồng bộ, nơi mỗi máy chủ (node) đều có một bản sao dữ liệu. Điều này không chỉ giúp loại bỏ điểm lỗi duy nhất (single point of failure) mà còn tăng cường khả năng mở rộng cho toàn bộ hệ thống. Với MySQL Group Replication, nếu một node gặp sự cố, các node khác vẫn tiếp tục hoạt động, đảm bảo ứng dụng của bạn luôn trực tuyến. Bài viết này của AZWEB sẽ hướng dẫn bạn chi tiết từng bước, từ chuẩn bị môi trường, cài đặt, cấu hình đến tối ưu và xử lý sự cố, giúp bạn triển khai thành công một cụm MySQL mạnh mẽ trên nền tảng Ubuntu 20.04.
Giới thiệu về MySQL Group Replication trên Ubuntu 20.04
MySQL Group Replication là một công nghệ sao chép mạnh mẽ, cho phép bạn tạo ra một hệ thống cơ sở dữ liệu có khả năng chịu lỗi và tính sẵn sàng cao. Thay vì mô hình chủ-tớ (master-slave) truyền thống, Group Replication sử dụng một nhóm các máy chủ hoạt động ngang hàng. Mọi thay đổi dữ liệu trên một thành viên sẽ được sao chép đến tất cả các thành viên khác trong nhóm, đảm bảo tính nhất quán và toàn vẹn.
Trong các hệ thống hiện đại, việc quản lý dữ liệu phân tán và đảm bảo ứng dụng hoạt động 24/7 là một thách thức lớn. Bất kỳ sự cố nào xảy ra với máy chủ cơ sở dữ liệu duy nhất đều có thể khiến toàn bộ dịch vụ ngừng hoạt động. Đây là lúc MySQL Group Replication trên nền tảng Ubuntu 20.04 phát huy tác dụng. Nó cung cấp một giải pháp tin cậy để xây dựng các cụm cơ sở dữ liệu tự động chuyển đổi dự phòng (failover), giúp hệ thống của bạn luôn sẵn sàng.
Bài viết này sẽ là kim chỉ nam của bạn trong quá trình triển khai. Chúng ta sẽ bắt đầu từ việc chuẩn bị môi trường, yêu cầu hệ thống, sau đó đi sâu vào các bước cài đặt và cấu hình chi tiết. Cuối cùng, AZWEB sẽ hướng dẫn bạn cách vận hành, giám sát, xử lý sự cố và tối ưu hóa hiệu suất cho cụm MySQL của mình.

Yêu cầu hệ thống và chuẩn bị môi trường trên Ubuntu 20.04
Để triển khai MySQL Group Replication thành công, việc chuẩn bị kỹ lưỡng môi trường ban đầu là cực kỳ quan trọng. Một nền tảng vững chắc sẽ giúp quá trình cài đặt và vận hành sau này diễn ra suôn sẻ hơn.
Yêu cầu phần cứng và phần mềm cơ bản
Một hệ thống ổn định đòi hỏi cấu hình phần cứng phù hợp. Dưới đây là các khuyến nghị tối thiểu cho mỗi node trong cụm của bạn:
- CPU: Tối thiểu 2 lõi (cores) để xử lý các tác vụ cơ sở dữ liệu và quá trình sao chép.
- RAM: Tối thiểu 4GB. Dung lượng RAM lớn hơn sẽ cải thiện hiệu suất đáng kể, đặc biệt với các bộ dữ liệu lớn.
- Ổ đĩa: Nên sử dụng ổ cứng SSD để tăng tốc độ đọc/ghi (I/O), một yếu tố then chốt trong hiệu suất sao chép. Dung lượng cần đủ để chứa hệ điều hành và toàn bộ cơ sở dữ liệu của bạn.
Về phần mềm, bạn cần sử dụng hệ điều hành Linux là gì trong đó có bản phân phối phổ biến Ubuntu 20.04 LTS (Focal Fossa). Phiên bản này cung cấp sự ổn định và hỗ trợ lâu dài, hoàn toàn tương thích với MySQL 8.0, phiên bản được khuyến nghị để tận dụng tối đa các tính năng của Group Replication.
Chuẩn bị mạng lưới và các bước tiền đề
Kết nối mạng ổn định giữa các node là xương sống của Group Replication. Mọi node phải có khả năng giao tiếp với nhau một cách thông suốt.
- Cấu hình mạng: Đảm bảo mỗi node có một địa chỉ IP tĩnh và có thể ping thấy nhau. Sử dụng kết nối mạng có độ trễ thấp (low latency) để tối ưu tốc độ đồng bộ.
- Cấu hình Firewall: Bạn cần mở các cổng cần thiết trên tường lửa (UFW trên Ubuntu). Cổng mặc định của MySQL là
3306và cổng giao tiếp nhóm thường là33061. Bạn có thể mở chúng bằng lệnh:sudo ufw allow 3306/tcpvàsudo ufw allow 33061/tcp.
Một yếu tố cực kỳ quan trọng khác là đồng bộ hóa thời gian giữa các node. Chênh lệch thời gian có thể gây ra xung đột và lỗi trong quá trình ghi nhận giao dịch. Do đó, bạn phải cài đặt và cấu hình dịch vụ NTP (Network Time Protocol) trên tất cả các node.
- Cài đặt NTP:
sudo apt update && sudo apt install ntp - Kiểm tra trạng thái đồng bộ:
ntpstat
Hoàn thành các bước chuẩn bị này sẽ tạo ra một môi trường lý tưởng để bạn bắt đầu quá trình cài đặt.

Hướng dẫn cài đặt MySQL và các thành phần cần thiết
Sau khi đã chuẩn bị xong môi trường, bước tiếp theo là cài đặt MySQL Server và các thành phần phụ trợ cần thiết cho Group Replication. Chúng ta sẽ sử dụng phiên bản MySQL 8.0 từ kho lưu trữ mặc định của Ubuntu 20.04.
Cài đặt MySQL phiên bản phù hợp trên Ubuntu 20.04
Quá trình cài đặt MySQL trên Ubuntu khá đơn giản. Bạn chỉ cần thực hiện các lệnh sau trong terminal:
Đầu tiên, hãy cập nhật danh sách gói của hệ thống:sudo apt update
Tiếp theo, tiến hành cài đặt gói mysql-server:sudo apt install mysql-server
Hệ thống sẽ tự động cài đặt phiên bản MySQL 8.0 và các gói phụ thuộc. Sau khi cài đặt hoàn tất, dịch vụ MySQL sẽ tự động khởi chạy. Bạn có thể kiểm tra phiên bản và trạng thái của dịch vụ để chắc chắn mọi thứ đã sẵn sàng.
- Kiểm tra phiên bản:
mysql --version - Kiểm tra trạng thái dịch vụ:
sudo systemctl status mysql
Nếu dịch vụ đang hoạt động (active/running), bạn đã cài đặt thành công. Bước đầu tiên sau khi cài đặt là chạy script bảo mật để thiết lập mật khẩu root và gỡ bỏ các cài đặt mặc định không an toàn:sudo mysql_secure_installation
Hãy làm theo các hướng dẫn trên màn hình để hoàn tất quá trình này.

Cài đặt các plugin và thành phần hỗ trợ Group Replication
Bản thân MySQL Group Replication là một plugin và cần được kích hoạt. May mắn là với MySQL 8.0, plugin này đã được tích hợp sẵn, bạn chỉ cần cài đặt nó bên trong môi trường MySQL.
Đầu tiên, đăng nhập vào MySQL shell với quyền root:sudo mysql -u root -p
Sau khi đăng nhập thành công, chạy lệnh sau để cài đặt plugin:INSTALL PLUGIN group_replication SONAME 'group_replication.so';
Nếu không có lỗi nào xảy ra, plugin đã được kích hoạt và sẵn sàng để cấu hình. Bạn có thể kiểm tra lại bằng cách truy vấn bảng plugin trong cơ sở dữ liệu information_schema.
Ngoài ra, đối với các môi trường yêu cầu quản lý dễ dàng hơn, bạn có thể xem xét sử dụng MySQL InnoDB Cluster. Đây là một giải pháp tích hợp toàn diện, sử dụng Group Replication làm nền tảng và cung cấp thêm MySQL Router để định tuyến kết nối, cùng với MySQL Shell để quản lý cụm một cách tự động và trực quan hơn. Tuy nhiên, trong khuôn khổ bài viết này, chúng ta sẽ tập trung vào việc cấu hình Group Replication một cách thủ công để hiểu rõ hơn về cách hoạt động của nó.
Cấu hình các tham số sao chép nhóm trong MySQL
Đây là bước quan trọng nhất, quyết định sự thành công của việc thiết lập cụm Group Replication. Bạn cần chỉnh sửa file cấu hình của MySQL để bật các tính năng cần thiết và định nghĩa các tham số cho nhóm sao chép.
Cấu hình file my.cnf cho MySQL Group Replication
File cấu hình chính của MySQL trên Ubuntu thường nằm tại /etc/mysql/mysql.conf.d/mysqld.cnf. Bạn cần mở file này bằng một trình soạn thảo văn bản (như nano hoặc vim) với quyền quản trị.
sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf
Bên dưới phần [mysqld], bạn cần thêm hoặc chỉnh sửa các tham số sau. Hãy thực hiện việc này trên TẤT CẢ các node trong cụm của bạn.
server_id: Mỗi node phải có một giá trịserver_idduy nhất. Ví dụ:server_id=1cho node 1,server_id=2cho node 2.gtid_mode = ONvàenforce_gtid_consistency = ON: Bật chế độ GTID (Global Transaction Identifier), một yêu cầu bắt buộc cho Group Replication.binlog_format = ROW: Định dạng binary log phải là ROW.transaction_write_set_extraction = XXHASH64: Chỉ định thuật toán để tạo “dấu vân tay” cho mỗi giao dịch, giúp phát hiện xung đột.
Tiếp theo là các tham số dành riêng cho Group Replication:
plugin_load_add = 'group_replication.so': Tải plugin khi MySQL khởi động.group_replication_group_name = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx": Đây là UUID định danh cho nhóm của bạn. Bạn có thể tạo một UUID mới bằng lệnhuuidgen. Tất cả các node trong nhóm phải có cùng giá trị này.group_replication_start_on_boot = off: Tạm thời tắt tự khởi động cùng hệ thống để chúng ta có thể khởi tạo thủ công.group_replication_local_address = "node_ip:33061": Địa chỉ IP và cổng mà node này sẽ lắng nghe giao tiếp từ các node khác. Thaynode_ipbằng IP của chính node đó.group_replication_group_seeds = "node1_ip:33061,node2_ip:33061,...": Danh sách các node “hạt giống” trong cụm để một node mới có thể tìm và tham gia vào nhóm.
Sau khi thêm tất cả các cấu hình, hãy lưu file và khởi động lại dịch vụ MySQL trên tất cả các node: sudo systemctl restart mysql.

Thiết lập user và quyền cho Group Replication
Group Replication cần một người dùng MySQL chuyên dụng để thực hiện các hoạt động sao chép và khôi phục dữ liệu giữa các node. Việc tạo một user riêng biệt giúp tăng cường bảo mật.
Trên một node bất kỳ, đăng nhập vào MySQL và thực hiện các lệnh SQL sau. Người dùng này sẽ tự động được sao chép đến các node khác sau khi nhóm được hình thành.
Tạo người dùng repl_user với mật khẩu an toàn:CREATE USER 'repl_user'@'%' IDENTIFIED BY 'YourStrongPassword';
Cấp các quyền cần thiết cho người dùng này:GRANT REPLICATION_SLAVE ON *.* TO 'repl_user'@'%';GRANT BACKUP_ADMIN ON *.* TO 'repl_user'@'%'; (Cần thiết cho quá trình khôi phục dữ liệu tự động)
Áp dụng các thay đổi về quyền:FLUSH PRIVILEGES;
Cuối cùng, bạn cần cấu hình để Group Replication sử dụng tài khoản này. Chạy các lệnh sau trong MySQL shell trên từng node:CHANGE REPLICATION SOURCE TO USER='repl_user', PASSWORD='YourStrongPassword' FOR CHANNEL 'group_replication_recovery';
Bây giờ, hệ thống của bạn đã được cấu hình đầy đủ và sẵn sàng cho bước khởi tạo cụm.
Khởi tạo và quản lý cụm sao chép nhóm MySQL
Sau khi hoàn tất việc cài đặt và cấu hình trên tất cả các node, giờ là lúc chúng ta “thổi hồn” cho cụm sao chép, biến các máy chủ độc lập thành một nhóm hoạt động thống nhất.
Khởi tạo nhóm replication trên node đầu tiên
Quá trình này được gọi là “bootstrapping” – khởi tạo thành viên đầu tiên để hình thành nên nhóm. Bạn chỉ thực hiện thao tác này trên MỘT node duy nhất, node này sẽ trở thành “hạt nhân” ban đầu của cụm.
Đăng nhập vào MySQL shell trên node bạn chọn làm node đầu tiên.
Chạy các lệnh sau theo thứ tự:
- Thiết lập node này làm node mồi (bootstrap):
SET GLOBAL group_replication_bootstrap_group=ON; - Khởi động Group Replication:
START GROUP_REPLICATION; - Tắt chế độ bootstrap ngay lập tức:
SET GLOBAL group_replication_bootstrap_group=OFF;
Việc tắt chế độ bootstrap là cực kỳ quan trọng. Nếu không, mỗi khi node này khởi động lại, nó sẽ cố gắng tạo một nhóm mới thay vì tham gia lại nhóm cũ, gây ra tình trạng “split-brain”.
Để kiểm tra xem nhóm đã được khởi tạo thành công hay chưa, hãy chạy lệnh sau:SELECT * FROM performance_schema.replication_group_members;
Bạn sẽ thấy một dòng kết quả, hiển thị thông tin của node đầu tiên với MEMBER_STATE là ONLINE. Xin chúc mừng, cụm của bạn đã chính thức ra đời!
Thêm node mới vào cụm và quản lý hoạt động nhóm
Bây giờ, chúng ta sẽ thêm các node còn lại vào cụm. Quá trình này đơn giản hơn rất nhiều. Trên mỗi node thứ cấp (node 2, node 3,…), bạn chỉ cần đăng nhập vào MySQL shell và chạy một lệnh duy nhất:START GROUP_REPLICATION;
Nhờ vào cấu hình group_replication_group_seeds trong file my.cnf, node này sẽ tự động tìm đến các thành viên hiện có, thực hiện quá trình đồng bộ dữ liệu (nếu cần) và gia nhập vào nhóm. Quá trình đồng bộ dữ liệu ban đầu này được gọi là Distributed Recovery, nó sẽ tự động sao chép dữ liệu từ một node đang online sang node mới.
Sau khi thêm tất cả các node, bạn có thể chạy lại lệnh kiểm tra trạng thái trên bất kỳ node nào:SELECT * FROM performance_schema.replication_group_members;
Lần này, bạn sẽ thấy danh sách tất cả các node trong cụm, đều có trạng thái ONLINE.
Để quản lý cụm hiệu quả hơn, MySQL Shell là một công cụ không thể thiếu. Nó cung cấp các giao diện lệnh (dba.getCluster(), cluster.status()) giúp bạn xem trạng thái, kiểm tra cấu hình và quản lý cụm một cách trực quan và tự động hóa.

Kiểm tra và xử lý sự cố khi thiết lập sao chép nhóm
Trong quá trình thiết lập, bạn có thể gặp phải một số vấn đề. Việc hiểu rõ nguyên nhân và cách khắc phục sẽ giúp bạn tiết kiệm rất nhiều thời gian và công sức. Dưới đây là hai nhóm sự cố phổ biến nhất.
Lỗi kết nối giữa các node
Đây là lỗi thường gặp nhất khi một node không thể tham gia vào nhóm. Các thành viên trong cụm không thể “nhìn thấy” nhau.
Nguyên nhân phổ biến:
- Firewall: Tường lửa trên máy chủ hoặc trên hệ thống mạng đang chặn các cổng giao tiếp (
3306hoặc33061). - Cấu hình mạng sai: Địa chỉ IP trong các tham số
group_replication_local_addresshoặcgroup_replication_group_seedskhông chính xác. - Sự cố mạng vật lý: Vấn đề về cáp mạng, switch, hoặc router.
Cách kiểm tra và khắc phục:
- Kiểm tra Firewall: Trên Ubuntu, sử dụng lệnh
sudo ufw statusđể xem các quy tắc tường lửa. Đảm bảo các cổng cần thiết đã được cho phép (ALLOW). - Kiểm tra kết nối mạng: Từ node này, hãy thử
pingđến địa chỉ IP của các node khác. Nếu ping thành công, hãy sử dụngtelnethoặcncđể kiểm tra kết nối tới cổng cụ thể:telnet <địa_chỉ_ip_node_khác> 33061. Nếu kết nối bị từ chối (Connection refused) hoặc hết thời gian (Timeout), vấn đề nằm ở mạng hoặc firewall. - Kiểm tra log lỗi của MySQL: File log lỗi (thường ở
/var/log/mysql/error.log) chứa rất nhiều thông tin giá trị. Hãy kiểm tra file này để tìm các thông báo liên quan đến Group Replication, ví dụ như “[GCS] The member was unable to contact anyone in the group.”

Đồng bộ dữ liệu và trạng thái replication gặp vấn đề
Đôi khi các node đã kết nối được với nhau nhưng lại không thể đồng bộ dữ liệu, hoặc một node bị rơi vào trạng thái RECOVERING quá lâu.
Nguyên nhân phổ biến:
- GTID không nhất quán: Dữ liệu trên node mới tham gia có các giao dịch (GTID) không tồn tại trên các node cũ, hoặc ngược lại. Điều này thường xảy ra nếu node đó trước đây đã từng hoạt động độc lập.
- Không đủ dung lượng đĩa: Quá trình khôi phục dữ liệu (cloning) đòi hỏi không gian đĩa trống để sao chép dữ liệu.
- Lỗi deadlock: Trong chế độ đa chủ (multi-primary), hai node có thể cùng lúc cố gắng ghi vào cùng một hàng dữ liệu, gây ra xung đột và một giao dịch sẽ bị hủy.
Cách khắc phục:
- Reset và Resync node: Đây là cách giải quyết triệt để nhất cho vấn đề dữ liệu không nhất quán. Bạn cần dừng Group Replication trên node bị lỗi (
STOP GROUP_REPLICATION;), xóa toàn bộ dữ liệu trong thư mục/var/lib/mysql(hãy chắc chắn bạn không có dữ liệu quan trọng trên node này), khởi tạo lại thư mục dữ liệu MySQL, và sau đó khởi động lại Group Replication. Quá trình Distributed Recovery sẽ tự động sao chép lại toàn bộ dữ liệu sạch từ một node khỏe mạnh. - Kiểm tra trạng thái chi tiết: Sử dụng các bảng trong
performance_schemanhưreplication_group_member_statsđể xem thông tin chi tiết về hàng đợi giao dịch và các lỗi có thể xảy ra. - Xem lại cấu hình: Đảm bảo rằng tất cả các node đều có cấu hình
my.cnfđồng nhất, đặc biệt làgroup_replication_group_name.
Tối ưu hiệu suất và đảm bảo tính sẵn sàng cao của hệ thống
Việc thiết lập thành công một cụm Group Replication chỉ là bước khởi đầu. Để hệ thống hoạt động hiệu quả và ổn định trong môi trường thực tế, bạn cần quan tâm đến việc tối ưu hiệu suất và xây dựng các cơ chế đảm bảo tính sẵn sàng cao.
Điều chỉnh tham số hiệu suất:
- Mạng (Network): Hiệu suất của Group Replication phụ thuộc rất nhiều vào độ trễ mạng. Hãy đảm bảo các node được kết nối qua một mạng tốc độ cao và có độ trễ thấp (ví dụ: mạng 10Gbps trong cùng một trung tâm dữ liệu là gì).
- Lưu trữ (I/O): Vì mọi thao tác ghi đều được áp dụng trên tất cả các node, hệ thống lưu trữ nhanh (SSD, NVMe) là yếu tố cực kỳ quan trọng, giống như cấu hình RAID để đảm bảo hiệu năng và dự phòng.
- Flow Control: Đây là cơ chế giúp điều tiết tốc độ sao chép, ngăn chặn một node ghi quá nhanh khiến các node khác không theo kịp. Bạn có thể điều chỉnh các tham số như
group_replication_flow_control_modeđể cân bằng giữa hiệu suất và sự ổn định.
Thiết lập chính sách Failover và Backup:
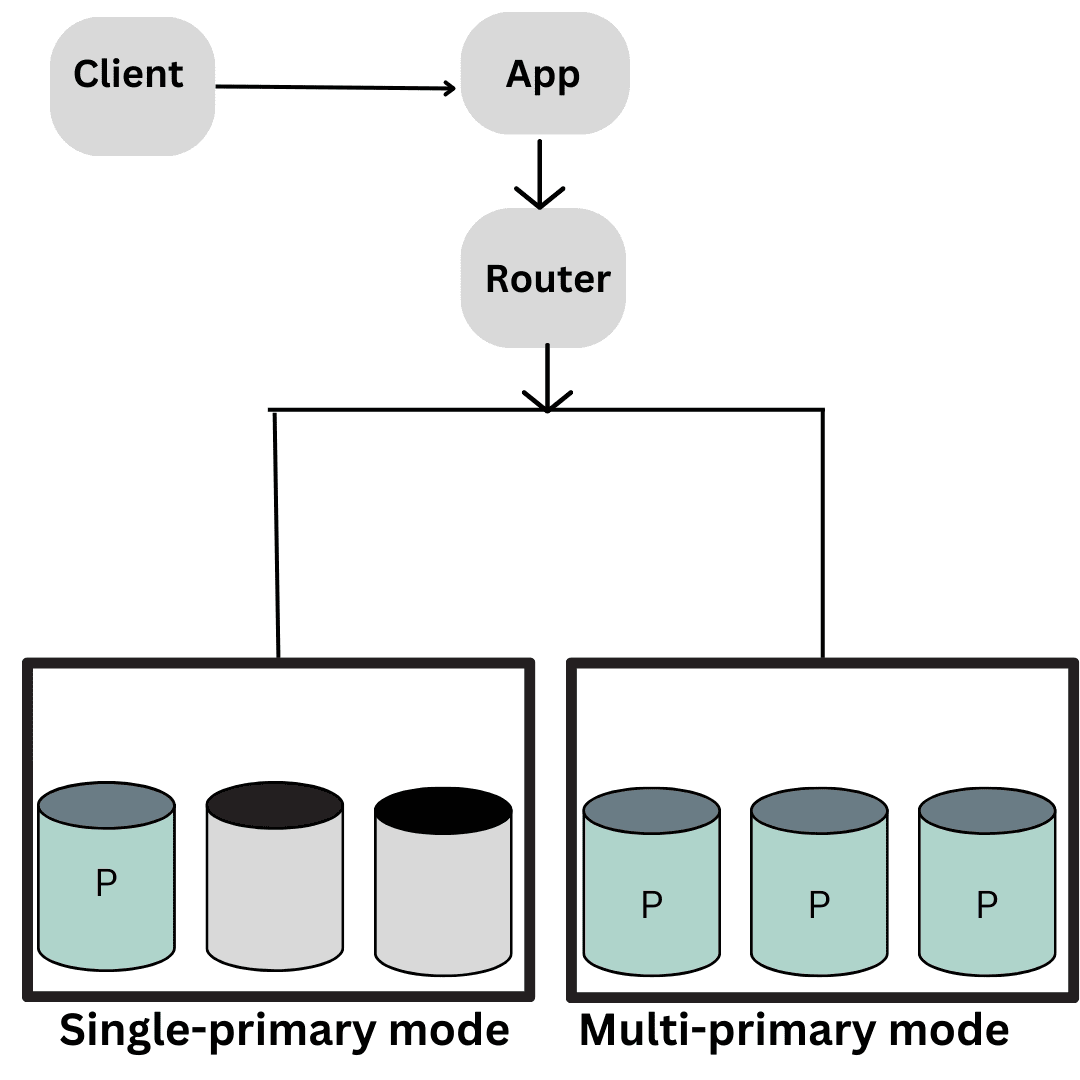
- Failover tự động: Group Replication vốn đã có cơ chế tự động chuyển đổi dự phòng. Trong chế độ đơn chủ (single-primary), nếu node chính (primary) gặp sự cố, nhóm sẽ tự động bầu chọn một node phụ (secondary) lên làm primary mới. Quá trình này diễn ra trong vài giây, giảm thiểu thời gian gián đoạn.
- Sử dụng Proxy/Router: Để ứng dụng không cần biết node nào đang là primary, bạn nên sử dụng một lớp trung gian như MySQL Router hoặc ProxySQL. Các công cụ này sẽ tự động phát hiện node primary mới và định tuyến tất cả các kết nối ghi về đó.
- Backup thường xuyên: Hãy nhớ rằng, sao chép (replication) không phải là sao lưu (Backup là gì). Bạn vẫn phải thiết lập một chiến lược backup định kỳ cho cơ sở dữ liệu của mình. Bạn có thể sử dụng các công cụ như
mysqldumphoặc Percona XtraBackup để tạo các bản sao lưu đầy đủ và gia tăng.
Giám sát và bảo trì:
Thường xuyên giám sát là chìa khóa để phát hiện sớm các vấn đề. Hãy theo dõi các chỉ số quan trọng như độ trễ sao chép, số lượng giao dịch trong hàng đợi, trạng thái của các thành viên trong nhóm thông qua các bảng performance_schema hoặc các công cụ giám sát chuyên dụng như Prometheus, Grafana. Việc kiểm tra log lỗi của MySQL định kỳ cũng là một thói quen tốt để kịp thời phát hiện và xử lý sự cố.

Kết luận
Qua bài viết này, AZWEB đã cùng bạn đi qua một hành trình chi tiết để cấu hình MySQL Group Replication trên Ubuntu 20.04. Chúng ta đã thấy rõ những lợi ích vượt trội mà công nghệ này mang lại: từ việc loại bỏ điểm lỗi duy nhất, đảm bảo tính sẵn sàng cao cho đến khả năng mở rộng hệ thống một cách linh hoạt. Việc xây dựng một cụm cơ sở dữ liệu có khả năng chịu lỗi không còn là một công việc phức tạp mà đã trở nên dễ tiếp cận hơn bao giờ hết.
Bằng cách tuân thủ các bước chuẩn bị môi trường, cài đặt, cấu hình và khởi tạo một cách cẩn thận, bạn có thể xây dựng một nền tảng dữ liệu vững chắc, ổn định và hiệu quả. Một hệ thống cơ sở dữ liệu mạnh mẽ chính là trái tim của mọi ứng dụng web chuyên nghiệp, là nền tảng cho các dịch vụ Hosting chất lượng cao mà AZWEB luôn hướng tới.
Chúng tôi khuyến khích bạn bắt đầu triển khai thử nghiệm trong môi trường phát triển để làm quen với cơ chế hoạt động của nó. Từ đó, bạn có thể tự tin áp dụng vào môi trường sản xuất. Các bước tiếp theo có thể là tìm hiểu sâu hơn về SQL Server Management Studio để quản lý cụm nâng cao, tích hợp với MySQL Router để tự động hóa việc định tuyến, hoặc xây dựng các kịch bản sao lưu và phục hồi toàn diện. Chúc bạn thành công