Bạn có biết lệnh cut là một trong những công cụ dòng lệnh mạnh mẽ và hữu ích nhất trong Linux, giúp bạn trích xuất dữ liệu nhanh chóng từ các tệp văn bản không? Trong công việc hàng ngày của một quản trị viên hệ thống hay nhà phát triển, việc xử lý và lọc thông tin từ các file log, file CSV, hoặc các tệp cấu hình là một nhiệm vụ quen thuộc. Tuy nhiên, việc xử lý và lọc dữ liệu này đôi khi gặp không ít khó khăn nếu bạn không biết cách sử dụng các công cụ dòng lệnh phù hợp, dẫn đến tốn thời gian và công sức. Đây chính là lúc lệnh cut phát huy sức mạnh. Lệnh cut cho phép bạn trích xuất các cột, trường, hoặc ký tự cụ thể từ mỗi dòng của một tệp một cách chính xác, giúp tiết kiệm thời gian và tự động hóa các tác vụ xử lý dữ liệu. Bài viết này sẽ hướng dẫn bạn từ những kiến thức cơ bản, các tùy chọn phổ biến, đi sâu vào 9 ví dụ thực tế, so sánh với các công cụ khác và đưa ra những lời khuyên hữu ích để bạn làm chủ lệnh cut.
Cách sử dụng cơ bản và các tùy chọn phổ biến của lệnh cut
Để bắt đầu hành trình làm chủ lệnh cut, chúng ta cần nắm vững cú pháp cơ bản và hiểu rõ chức năng của các tùy chọn phổ biến. Việc này sẽ tạo nền tảng vững chắc giúp bạn áp dụng linh hoạt vào các tác vụ phức tạp hơn sau này. Lệnh cut không khó, nhưng hiểu đúng và dùng đúng tùy chọn sẽ quyết định hiệu quả công việc của bạn.

Cách dùng cơ bản của lệnh cut trong Linux
Về cơ bản, lệnh cut hoạt động bằng cách “cắt” các phần dữ liệu từ mỗi dòng đầu vào và chỉ hiển thị những phần bạn đã chọn. Cú pháp của nó rất đơn giản và dễ nhớ, giúp bạn nhanh chóng làm quen và sử dụng.
Cú pháp chung của lệnh cut như sau:
cut [tùy chọn] [file]
Trong đó:
– [tùy chọn] là các cờ (flag) để chỉ định cách cắt dữ liệu (ví dụ: theo ký tự, theo trường).
– [file] là tên của tệp tin bạn muốn xử lý. Nếu không có tệp nào được chỉ định, lệnh cut sẽ đọc từ đầu vào chuẩn (standard input), thường là kết quả của một lệnh khác được truyền qua pipe (|).
Ví dụ, để cắt ký tự thứ hai và thứ ba từ mỗi dòng của tệp data.txt, bạn có thể sử dụng lệnh: cut -c 2,3 data.txt. Tương tự, nếu muốn cắt cột đầu tiên từ một tệp có các cột được phân tách bằng dấu phẩy, bạn sẽ dùng: cut -d',' -f1 data.txt.
Các tùy chọn phổ biến: -b, -c, -f
Sức mạnh thực sự của lệnh cut nằm ở các tùy chọn của nó. Ba tùy chọn quan trọng nhất mà bạn sẽ sử dụng thường xuyên là -b, -c, và -f. Mỗi tùy chọn phục vụ một mục đích cắt dữ liệu khác nhau, tùy thuộc vào cấu trúc của dữ liệu đầu vào.
- -b (byte): Tùy chọn này dùng để cắt dữ liệu dựa trên vị trí byte. Nó rất hữu ích khi bạn làm việc với dữ liệu có kích thước cố định hoặc các tệp nhị phân, nơi mỗi ký tự có thể chiếm nhiều hơn một byte (ví dụ như trong mã hóa UTF-8).
– Ví dụ:cut -b 1-4 file.txtsẽ trích xuất 4 byte đầu tiên từ mỗi dòng.

- -c (character): Đây là tùy chọn phổ biến nhất khi làm việc với các tệp văn bản thông thường. Nó cho phép bạn cắt dữ liệu dựa trên vị trí của ký tự. Điều này rất trực quan và dễ sử dụng khi bạn cần lấy một chuỗi con từ một chuỗi lớn hơn.
– Ví dụ:echo "AZWEB HOSTING" | cut -c 1-5sẽ trả về kết quả là “AZWEB”. Lệnh này cắt từ ký tự đầu tiên đến ký tự thứ năm. - -f (field): Tùy chọn này được sử dụng để cắt dữ liệu dựa trên các trường (cột), được phân tách bởi một ký tự đặc biệt gọi là dấu phân cách (delimiter). Mặc định, dấu phân cách là ký tự tab (
\t), nhưng bạn có thể chỉ định bất kỳ ký tự nào khác bằng tùy chọn-d. Đây là tùy chọn cực kỳ mạnh mẽ khi xử lý các tệp có cấu trúc như CSV.
– Ví dụ: Giả sử bạn có tệpusers.csvvới nội dungten,email,tuoi. Để lấy cột email, bạn dùng lệnh:cut -d',' -f2 users.csv. Tùy chọn-d','chỉ định rằng dấu phẩy là ký tự phân cách, và-f2yêu cầucuttrích xuất trường thứ hai.
9 ví dụ thực tế áp dụng lệnh cut để xử lý dữ liệu
Lý thuyết là nền tảng, nhưng thực hành mới giúp bạn thực sự thành thạo. Dưới đây là 9 ví dụ thực tế, từ đơn giản đến phức tạp, minh họa cách lệnh cut có thể được áp dụng để giải quyết các vấn đề hàng ngày trong môi trường Linux.
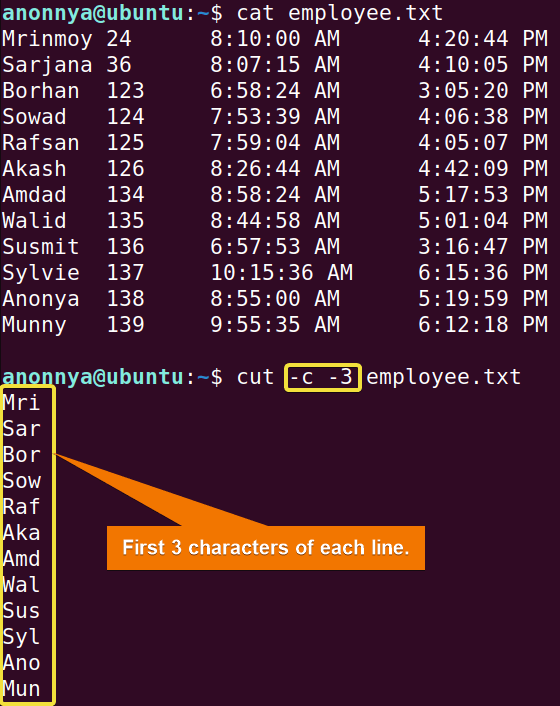
Ví dụ 1 – Lấy cột đầu tiên trong file văn bản đơn giản
Đây là trường hợp sử dụng cơ bản nhất. Giả sử bạn có một tệp sanpham.txt chứa danh sách các sản phẩm và giá, các trường được phân tách bằng một ký tự tab (delimiter mặc định của cut).
Nội dung tệp sanpham.txt:Hosting 100000
VPS 500000
Domain 250000
Để chỉ lấy tên sản phẩm (cột đầu tiên), bạn chỉ cần chạy lệnh:cut -f1 sanpham.txt
Kết quả sẽ là:Hosting
VPS
Domain
Lệnh này tự động nhận diện ký tự tab làm dấu phân cách và trích xuất trường đầu tiên (-f1).
Ví dụ 2 – Trích xuất trường cụ thể với dấu phân cách tab
Tương tự ví dụ 1, tab là dấu phân cách mặc định, vì vậy bạn không cần chỉ định nó với tùy chọn -d. Giả sử bạn muốn lấy cả tên sản phẩm và giá (cột 1 và 2) từ tệp sanpham.txt.
Bạn có thể chỉ định nhiều trường bằng cách sử dụng dấu phẩy:cut -f1,2 sanpham.txt
Kết quả sẽ giữ lại cả hai cột, vẫn được phân tách bằng tab:Hosting 100000
VPS 500000
Domain 250000
Ví dụ 3 – Cắt ký tự từ vị trí 3 đến 7 trong dòng văn bản
Khi bạn không làm việc với dữ liệu có cấu trúc cột mà chỉ muốn lấy một phần của chuỗi, tùy chọn -c là lựa chọn hoàn hảo. Giả sử bạn có một chuỗi và muốn trích xuất một phần cụ thể.
Ví dụ, để lấy chữ “WEB” từ chuỗi “AZWEB VIETNAM”, bạn có thể cắt từ ký tự thứ 3 đến thứ 5:echo "AZWEB VIETNAM" | cut -c 3-5
Kết quả sẽ là:WEB
Bạn cũng có thể cắt các ký tự không liền kề. Ví dụ, để lấy ký tự 1, 3, và 5:echo "AZWEB" | cut -c 1,3,5 sẽ cho ra “AEB”.
Ví dụ 4 – Kết hợp cut với các lệnh khác như grep, sort để xử lý chuỗi dữ liệu
Sức mạnh của Linux nằm ở khả năng kết hợp các lệnh nhỏ lại với nhau (pipelining). cut thường được dùng như một mắt xích trong một chuỗi lệnh để tinh chỉnh đầu ra.
Giả sử bạn có tệp access.log và muốn tìm tất cả các truy cập bị lỗi “404 Not Found”, sau đó chỉ lấy địa chỉ IP của người truy cập (giả sử IP nằm ở cột đầu tiên và các cột được ngăn cách bởi dấu cách).
grep "404" access.log | cut -d' ' -f1 | sort | uniq -c
Lệnh này hoạt động như sau:
1. grep "404" access.log: Lọc ra tất cả các dòng chứa chuỗi “404”.
2. cut -d' ' -f1: Cắt các dòng kết quả, sử dụng dấu cách làm delimiter và chỉ lấy cột đầu tiên (địa chỉ IP).
3. sort | uniq -c: Sắp xếp các IP và đếm số lần xuất hiện của mỗi IP.
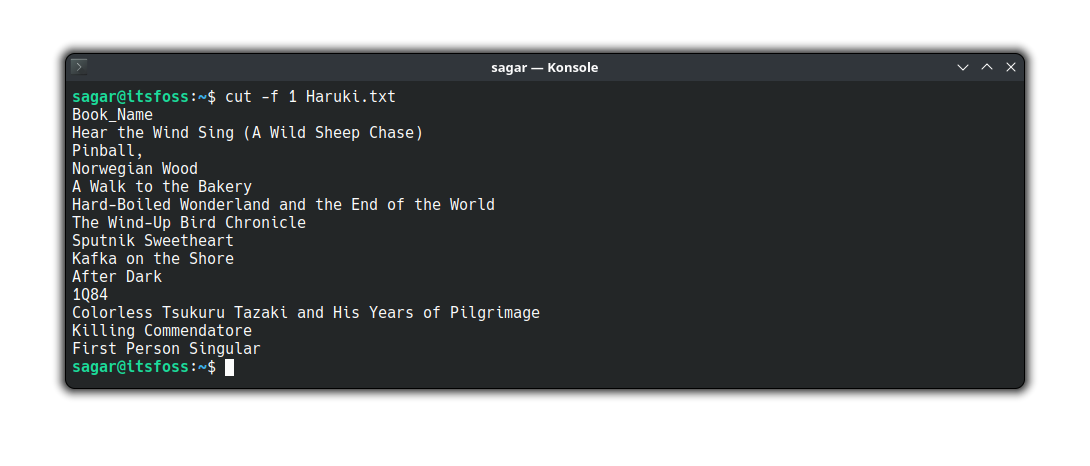
Ví dụ 5 – Lọc địa chỉ email từ danh sách người dùng
Trong nhiều hệ thống, thông tin người dùng được lưu trong các tệp có cấu trúc, ví dụ như tệp /etc/passwd nhưng có thêm trường email ở cuối. Giả sử ta có tệp users_extended.txt với định dạng username:x:uid:gid:comment:home_dir:shell:email.
Để trích xuất danh sách email, bạn có thể dùng cut với dấu hai chấm (:) làm delimiter.cut -d':' -f8 users_extended.txt
Lệnh này sẽ tách mỗi dòng bằng dấu :, sau đó lấy ra trường thứ 8, chính là địa chỉ email.
Ví dụ 6 – Trích xuất mã vùng điện thoại từ file danh bạ
Giả sử bạn có một tệp danhba.txt với các số điện thoại theo định dạng (028)-1234567. Bạn muốn lấy mã vùng (ví dụ: 028). Đây là một bài toán cần kết hợp cut nhiều lần.
cut -d')' -f1 danhba.txt | cut -d'(' -f2
Lệnh này hoạt động qua hai bước:
1. cut -d')' -f1 danhba.txt: Cắt chuỗi bằng dấu ), lấy phần đầu tiên. Kết quả sẽ là (028.
2. cut -d'(' -f2: Lấy kết quả trên, cắt tiếp bằng dấu (, và lấy phần thứ hai. Kết quả cuối cùng là 028.
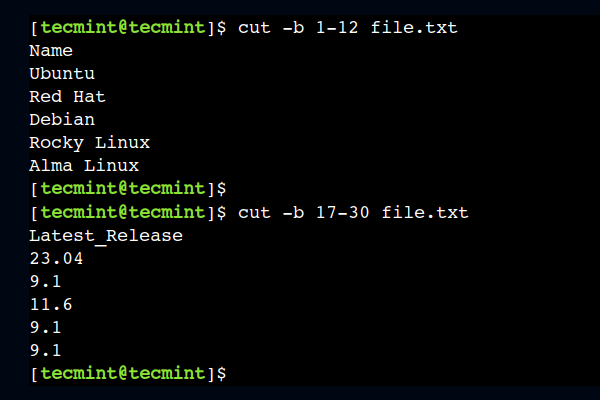
Ví dụ 7 – Cắt các trường nhất định từ file CSV bằng dấu phân cách phẩy
File CSV (Comma-Separated Values) là một định dạng rất phổ biến. cut là công cụ lý tưởng để xử lý nhanh loại tệp này. Giả sử bạn có tệp orders.csv chứa thông tin đơn hàng: order_id,product_name,quantity,price.
Để lấy ID đơn hàng và giá tiền (cột 1 và 4), bạn sử dụng lệnh:cut -d',' -f1,4 orders.csv
Tùy chọn -d',' nói cho cut biết rằng các trường được phân tách bằng dấu phẩy. -f1,4 yêu cầu trích xuất trường đầu tiên và trường thứ tư.
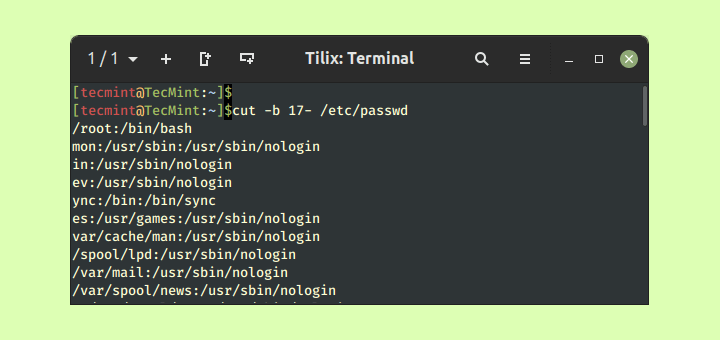
Ví dụ 8 – Xử lý log hệ thống để lấy thông tin thời gian và mức độ cảnh báo
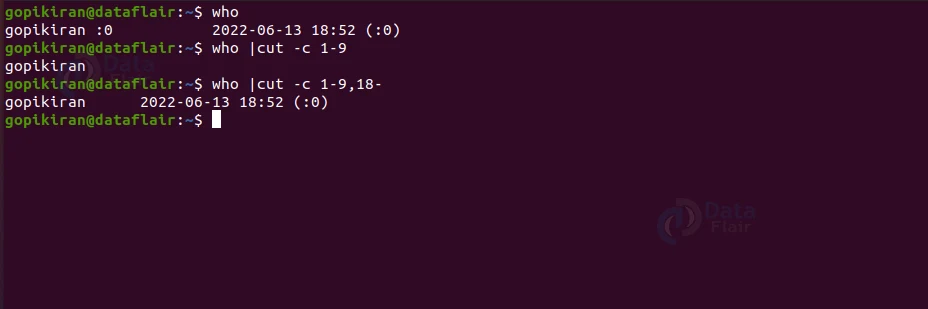
Các tệp log hệ thống thường có định dạng cố định, khiến chúng trở thành ứng cử viên sáng giá cho việc xử lý bằng cut với tùy chọn -c hoặc -f. Giả sử tệp syslog có định dạng: YYYY-MM-DD HH:MM:SS [LEVEL] Message.
Để lấy dấu thời gian (19 ký tự đầu tiên) và thông điệp (từ ký tự 28 trở đi), bạn có thể dùng:cut -c 1-19,28- syslog
Dấu phẩy cho phép bạn chọn nhiều khoảng ký tự. 28- có nghĩa là từ ký tự thứ 28 cho đến hết dòng.
Ví dụ 9 – So sánh content text giữa hai file bằng cut kết hợp diff
Đây là một kỹ thuật nâng cao hơn, sử dụng process substitution (<(command)) để so sánh đầu ra của hai lệnh cut khác nhau. Giả sử bạn có hai tệp, file1.txt và file2.txt, và bạn muốn so sánh cột đầu tiên của file1 với cột thứ hai của file2.
diff <(cut -f1 file1.txt) <(cut -f2 file2.txt)
Lệnh này thực hiện:
1. cut -f1 file1.txt: Trích xuất cột đầu tiên của file1.
2. cut -f2 file2.txt: Trích xuất cột thứ hai của file2.
3. diff <(...) <(...): So sánh kết quả của hai lệnh cut trên như thể chúng là hai tệp tin.
So sánh lệnh cut với các công cụ xử lý văn bản dòng lệnh khác
Trong hệ sinh thái Linux, cut không phải là công cụ duy nhất để xử lý văn bản. awk và sed là hai “gã khổng lồ” khác, mỗi công cụ đều có điểm mạnh riêng. Hiểu được khi nào nên dùng cut và khi nào nên chuyển sang các công cụ mạnh mẽ hơn sẽ giúp bạn làm việc hiệu quả hơn rất nhiều.
So sánh cut và awk
cut và awk đều có thể trích xuất các cột từ dữ liệu, nhưng cách tiếp cận và khả năng của chúng rất khác nhau.
- Điểm mạnh của
cut:
– Tốc độ:cutlà một tiện ích rất nhẹ và nhanh. Đối với các tác vụ cắt cột đơn giản trên các tệp lớn, nó thường nhanh hơnawk.
– Đơn giản: Cú pháp củacutcực kỳ dễ học và dễ nhớ. Nó hoàn hảo cho các kịch bản xử lý nhanh và đơn giản. - Hạn chế của
cutvà điểm mạnh củaawk:
– Dấu phân cách không đồng nhất:cutgặp khó khăn khi dữ liệu được phân tách bằng nhiều ký tự khác nhau hoặc nhiều dấu cách liền nhau.awkmặc định xử lý chuỗi các khoảng trắng (spaces, tabs) như một dấu phân cách duy nhất, làm cho nó linh hoạt hơn nhiều.
– Xử lý logic phức tạp:awkthực chất là một ngôn ngữ lập trình kịch bản. Bạn có thể thực hiện các phép tính, câu lệnh điều kiện (if/else), vòng lặp, và định dạng lại đầu ra một cách phức tạp.cutchỉ đơn thuần là trích xuất dữ liệu.
– Sắp xếp lại cột: Vớicut, bạn không thể sắp xếp lại thứ tự các cột (ví dụ: in cột 3 rồi đến cột 1). Vớiawk, bạn có thể làm điều này dễ dàng:awk -F',' '{print $3, $1}' file.csv.
Khi nào dùng cut: Khi bạn cần trích xuất nhanh các cột hoặc ký tự từ dữ liệu có cấu trúc rõ ràng, đồng nhất.
Khi nào dùng awk: Khi bạn cần xử lý dữ liệu với dấu phân cách phức tạp, thực hiện tính toán, hoặc áp dụng logic có điều kiện.

So sánh cut và sed
sed (Stream Editor) là một công cụ mạnh mẽ khác, nhưng mục đích chính của nó khác với cut.
- Mục đích chính:
–cut: Trích xuất (extract) một phần của dòng dữ liệu.
–sed: Chỉnh sửa (edit) hoặc biến đổi (transform) dòng dữ liệu, thường là dựa trên các biểu thức chính quy (regular expressions). - Sự khác biệt chính:
– Hành động:cutchọn và hiển thị.sedtìm kiếm và thay thế, xóa, hoặc chèn văn bản.
– Phương thức chọn dữ liệu:cutchọn dữ liệu dựa trên vị trí (ký tự, byte, hoặc trường).sedchọn dữ liệu dựa trên mẫu (pattern matching), số dòng, hoặc địa chỉ.
Khi nào nên dùng cut: Khi bạn cần lấy một cột dữ liệu nguyên vẹn. Ví dụ: lấy danh sách tên người dùng từ tệp /etc/passwd.
Khi nào nên chọn sed: Khi bạn cần thay đổi một phần của dữ liệu. Ví dụ: tìm tất cả các dòng chứa “error” và thay thế nó bằng “WARNING”.
Khi nào kết hợp cả hai: Bạn có thể kết hợp chúng để thực hiện các tác vụ phức tạp. Ví dụ, dùng cut để trích xuất một cột cụ thể, sau đó dùng pipe (|) để truyền kết quả cho sed nhằm chỉnh sửa nội dung của cột đó.cut -d',' -f2 data.csv | sed 's/old_value/new_value/g'
Những vấn đề thường gặp khi sử dụng lệnh cut
Mặc dù lệnh cut rất đơn giản, người dùng mới đôi khi vẫn gặp phải một số lỗi phổ biến. Hiểu rõ những vấn đề này sẽ giúp bạn gỡ lỗi nhanh hơn và sử dụng lệnh một cách chính xác.
Vấn đề 1 – Lỗi do dữ liệu chứa dấu phân cách không đồng nhất
Đây là vấn đề phổ biến nhất. cut yêu cầu một dấu phân cách duy nhất và nhất quán. Nếu dữ liệu của bạn sử dụng cả tab và dấu cách, hoặc nhiều dấu cách liền nhau để ngăn cách các cột, cut sẽ không hoạt động như mong đợi.
Ví dụ, với dòng dữ liệu: field1 field2 field3 (sử dụng nhiều dấu cách).
Lệnh cut -d' ' -f2 có thể sẽ không trả về “field2” mà là một khoảng trắng, vì nó coi mỗi dấu cách là một delimiter riêng biệt. Trong trường hợp này, awk là giải pháp tốt hơn: echo "field1 field2 field3" | awk '{print $2}'. awk sẽ tự động xử lý chuỗi các khoảng trắng này.
Vấn đề 2 – Kết quả không như mong muốn vì sai cú pháp hoặc vị trí cắt
Một lỗi nhỏ trong cú pháp cũng có thể dẫn đến kết quả sai lệch hoặc không có kết quả nào cả.
- Quên tùy chọn
-dkhi dùng-f: Nếu bạn muốn cắt theo trường với dấu phân cách không phải là tab, bạn bắt buộc phải dùng-d. Nếu bạn chạycut -f2 file.csvtrên một tệp CSV,cutsẽ tìm kiếm ký tự tab và có thể sẽ trả về toàn bộ dòng vì không tìm thấy tab. Lệnh đúng phải làcut -d',' -f2 file.csv. - Nhầm lẫn giữa
-cvà-f: Sử dụng-c(character) khi bạn thực sự muốn cắt theo-f(field) sẽ dẫn đến kết quả không chính xác.-c 5sẽ lấy ký tự thứ 5, trong khi-f 5sẽ lấy trường thứ 5. - Sai vị trí cắt: Luôn đếm cẩn thận vị trí ký tự hoặc số thứ tự của trường. Một mẹo nhỏ là sử dụng lệnh
head -n 1 file.txtđể xem dòng đầu tiên và xác định cấu trúc trước khi áp dụng lệnhcutcho toàn bộ tệp.
Lời khuyên và lưu ý khi sử dụng lệnh cut trong thực tế
Để tối ưu hóa việc sử dụng lệnh cut và tránh các lỗi không đáng có, hãy ghi nhớ những lời khuyên sau. Đây là những kinh nghiệm được đúc kết từ quá trình làm việc thực tế với dòng lệnh Linux.
- Luôn kiểm tra kỹ dữ liệu đầu vào và định dạng phân cách: Trước khi viết lệnh, hãy xem qua một vài dòng của tệp dữ liệu bằng các lệnh như
head,cat, hoặcless. Việc này giúp bạn xác định chính xác ký tự phân cách là gì (tab, dấu phẩy, dấu cách, hay ký tự khác) và cấu trúc cột của dữ liệu. Đừng đoán, hãy kiểm tra! - Chọn đúng tùy chọn (-b, -c, -f) phù hợp với loại dữ liệu: Hãy tự hỏi: “Mình đang muốn cắt theo vị trí cố định hay theo cột được phân tách?”. Nếu dữ liệu có các cột rõ ràng, hãy dùng
-fvà-d. Nếu bạn đang làm việc với các chuỗi có độ dài cố định hoặc cần trích xuất một phần nhỏ của chuỗi,-csẽ là lựa chọn phù hợp. Tùy chọn-bít phổ biến hơn nhưng rất quan trọng khi xử lý dữ liệu nhị phân. - Kết hợp cut với các lệnh khác để tăng hiệu quả xử lý: Đừng xem
cutlà một công cụ độc lập. Sức mạnh thực sự của nó được bộc lộ khi kết hợp trong một chuỗi lệnh (pipeline). Sử dụnggrepđể lọc dòng,cutđể trích xuất cột,sortđể sắp xếp, vàuniqđể đếm. Sự kết hợp này có thể giải quyết các bài toán phức tạp chỉ bằng một dòng lệnh. - Tránh lạm dụng cut trong trường hợp dữ liệu quá phức tạp, nên dùng awk hoặc sed thay thế:
cutlà con dao mổ sắc bén cho những nhiệm vụ đơn giản. Tuy nhiên, nếu bạn thấy mình phải kết hợp quá nhiều lệnhcutvới nhau hoặc dữ liệu có cấu trúc không đồng nhất, đó là dấu hiệu cho thấy bạn nên chuyển sang một công cụ mạnh mẽ hơn nhưawkhoặcsed. Biết được giới hạn của công cụ và khi nào cần “nâng cấp” là một kỹ năng quan trọng của người dùng Linux hiệu quả.

Kết luận
Qua bài viết này, chúng ta đã cùng nhau khám phá lệnh cut trong Linux, từ cú pháp cơ bản, các tùy chọn quan trọng cho đến 9 ví dụ ứng dụng thực tiễn. Rõ ràng, cut không chỉ là một lệnh đơn giản mà còn là một công cụ cực kỳ giá trị và hiệu quả để trích xuất và xử lý dữ liệu văn bản trực tiếp trên dòng lệnh. Khả năng hoạt động nhanh, cú pháp dễ nhớ và sự linh hoạt khi kết hợp với các lệnh khác giúp cut trở thành một phần không thể thiếu trong bộ công cụ của bất kỳ ai làm việc thường xuyên với Linux.
Chúng tôi khuyến khích bạn hãy tự mình thực hành lại 9 ví dụ đã nêu để thực sự nắm vững cách hoạt động và các trường hợp sử dụng của lệnh này. Việc thành thạo cut sẽ giúp bạn tối ưu hóa công việc, tiết kiệm thời gian và xử lý dữ liệu một cách chuyên nghiệp hơn. Đừng dừng lại ở đó, hãy tiếp tục tìm hiểu sâu hơn về các công cụ xử lý văn bản dòng lệnh khác như Bash là gì và awk để nâng cao kỹ năng Linux của mình. Nếu bạn thấy bài viết này hữu ích, đừng ngần ngại chia sẻ nó cho bạn bè và đồng nghiệp. Hãy theo dõi AZWEB để cập nhật thêm nhiều kiến thức kỹ thuật chuyên sâu và hữu ích khác về Linux và quản trị hệ thống nhé.