Trong kỷ nguyên dữ liệu lớn ngày nay, Linux đã trở thành một công cụ không thể thiếu, giúp các tổ chức xử lý và phân tích khối lượng dữ liệu khổng lồ một cách hiệu quả. Hadoop, với kiến trúc mạnh mẽ và khả năng mở rộng, cho phép bạn lưu trữ và xử lý dữ liệu trên các cụm máy tính phân tán. Tuy nhiên, nhiều người mới bắt đầu thường cảm thấy choáng ngợp trước sự phức tạp của việc cấu hình và triển khai Hadoop với nhiều chế độ khác nhau.
Bài viết này của AZWEB sẽ gỡ rối vấn đề đó. Chúng tôi sẽ hướng dẫn bạn cài đặt Hadoop ở chế độ Stand-alone trên Ubuntu 20.04, một cách tiếp cận đơn giản và hiệu quả để làm quen với hệ sinh thái Hadoop mà không cần lo lắng về các cụm phức tạp. Chế độ Stand-alone rất lý tưởng cho việc học hỏi, thử nghiệm và phát triển ứng dụng cục bộ. Bạn sẽ được hướng dẫn chi tiết từ việc chuẩn bị hệ thống, cài đặt các thành phần cần thiết, cấu hình Hadoop, đến chạy thử một ví dụ đơn giản và những mẹo hữu ích để bắt đầu hành trình của mình với dữ liệu lớn. Hãy cùng AZWEB khám phá sức mạnh của Hadoop ngay hôm nay!

Yêu cầu hệ thống và chuẩn bị môi trường trên Ubuntu 20.04
Để bắt đầu hành trình cài đặt Hadoop, việc đầu tiên là đảm bảo hệ thống của bạn đáp ứng các yêu cầu cơ bản. Đây là bước nền tảng để mọi thứ diễn ra suôn sẻ, giúp bạn tránh các lỗi không đáng có trong quá trình cấu hình.
Yêu cầu phần cứng và phần mềm
Trước tiên, bạn cần chuẩn bị một môi trường Ubuntu 20.04 LTS (Long Term Support). Đây là phiên bản ổn định và được hỗ trợ lâu dài, rất phù hợp cho việc học và triển khai các hệ thống. Tiếp theo, Hadoop yêu cầu Java Development Kit (JDK) để hoạt động. Chúng tôi khuyến nghị sử dụng OpenJDK 8 hoặc OpenJDK 11, vì đây là những phiên bản được Hadoop hỗ trợ tốt nhất và hoạt động ổn định trên Ubuntu 20.04. Về phần cứng, dù chế độ Stand-alone không quá khắt khe, bạn nên có ít nhất 4GB RAM và 20GB dung lượng ổ cứng trống. Điều này đảm bảo hệ thống có đủ tài nguyên để chạy Hadoop và các tác vụ thử nghiệm mà không bị chậm trễ.
Chuẩn bị môi trường
Bây giờ, hãy cùng AZWEB thiết lập môi trường cho Ubuntu 20.04. Đầu tiên, chúng ta cần cài đặt Java. Bạn có thể mở Terminal và chạy các lệnh sau để cài đặt OpenJDK 11:
sudo apt update
sudo apt install openjdk-11-jdk -y
Sau khi cài đặt, hãy kiểm tra phiên bản Java và thiết lập biến môi trường JAVA_HOME. Biến này rất quan trọng để Hadoop biết vị trí của Java trên hệ thống của bạn.
java -version
echo $JAVA_HOME
Nếu JAVA_HOME chưa được thiết lập, bạn có thể thêm nó vào file ~/.bashrc hoặc ~/.profile như sau (thay thế đường dẫn nếu phiên bản Java của bạn khác):
echo 'export JAVA_HOME="/usr/lib/jvm/java-11-openjdk-amd64"' >> ~/.bashrc
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> ~/.bashrc
source ~/.bashrc
Việc tạo tài khoản người dùng Hadoop riêng biệt là một thói quen tốt, giúp quản lý quyền và bảo mật hệ thống. Tuy nhiên, với chế độ Stand-alone để thử nghiệm, bạn có thể sử dụng tài khoản hiện tại. Cuối cùng, hãy cài đặt các gói hỗ trợ cần thiết như wget (để tải file), ssh (cho các tác vụ quản lý cục bộ) và rsync (cho các tác vụ đồng bộ):
sudo apt install wget ssh rsync -y
Sau khi hoàn tất các bước này, môi trường của bạn đã sẵn sàng cho việc cài đặt Hadoop.

Các bước tải và cài đặt Hadoop chi tiết
Với môi trường đã được chuẩn bị sẵn sàng, bây giờ chúng ta sẽ tiến hành tải và cài đặt Hadoop. AZWEB sẽ hướng dẫn bạn từng bước một để đảm bảo quá trình diễn ra một cách chính xác.
Tải Hadoop về máy
Để tải Hadoop, bạn cần truy cập trang web chính thức của Apache Hadoop để tìm phiên bản ổn định mới nhất. Thông thường, bạn sẽ tìm thấy một liên kết đến phiên bản được phát hành gần đây trong phần “Releases”. Hãy chọn một phiên bản stable và tìm liên kết tải về từ một trong các gương (mirror) được cung cấp. Ví dụ, bạn có thể tìm một liên kết trực tiếp như https://downloads.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz (phiên bản có thể khác tại thời điểm bạn đọc). Sau khi có liên kết, hãy mở Terminal và sử dụng lệnh wget để tải file về thư mục ~/Downloads hoặc thư mục bạn muốn:
cd ~/Downloads
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
Tiếp theo, chúng ta sẽ giải nén file đã tải về vào một vị trí phù hợp, thường là /usr/local. Hãy đảm bảo bạn có quyền sudo để thực hiện thao tác này.
sudo tar -xzvf hadoop-3.3.6.tar.gz -C /usr/local/
Sau khi giải nén, đổi tên thư mục để dễ quản lý hơn:
sudo mv /usr/local/hadoop-3.3.6 /usr/local/hadoop
Bằng cách này, bạn đã tải và giải nén thành công Hadoop vào hệ thống của mình.
Thiết lập quyền và thư mục làm việc
Sau khi giải nén, việc quan trọng tiếp theo là thiết lập quyền sở hữu cho thư mục Hadoop. Điều này đảm bảo người dùng hiện tại của bạn có thể truy cập và sửa đổi các file cấu hình mà không gặp vấn đề về quyền. Chạy lệnh sau để thay đổi quyền sở hữu (thay your_username bằng tên người dùng hiện tại của bạn):
sudo chown -R your_username:your_username /usr/local/hadoop
Tiếp theo, chúng ta cần thiết lập các biến môi trường quan trọng để hệ thống có thể tìm thấy các lệnh và thư viện của Hadoop. Hãy mở file cấu hình shell của bạn (thường là ~/.bashrc hoặc ~/.profile) bằng trình soạn thảo văn bản như nano hoặc gedit:
nano ~/.bashrc
Thêm các dòng sau vào cuối file:
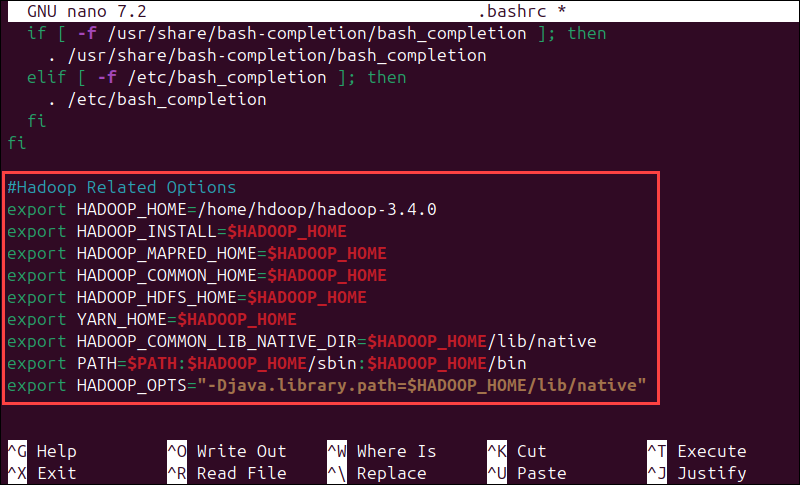
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Lưu file và thoát. Sau đó, áp dụng các thay đổi bằng lệnh:
source ~/.bashrc
Bây giờ, bạn có thể kiểm tra xem Hadoop đã được nhận diện chưa bằng cách gõ lệnh hadoop version. Nếu bạn thấy thông tin phiên bản Hadoop hiển thị, xin chúc mừng, bạn đã cài đặt Hadoop thành công!

Cấu hình Hadoop cho chế độ Stand-alone
Đến đây, bạn đã cài đặt Hadoop. Bước tiếp theo là cấu hình nó để chạy ở chế độ Stand-alone. Đây là chế độ đơn giản nhất, nơi tất cả các dịch vụ Hadoop chạy trên một JVM duy nhất, lý tưởng cho việc thử nghiệm và phát triển cục bộ.
Giới thiệu về chế độ Stand-alone trong Hadoop
Chế độ Stand-alone, hay còn gọi là chế độ Local, là môi trường mặc định khi bạn cài đặt Hadoop. Trong chế độ này, tất cả các thành phần của Hadoop (NameNode, DataNode, ResourceManager, NodeManager) đều chạy trên một máy duy nhất như các tiến trình Java thông thường. Nó không yêu cầu bất kỳ cấu hình SSH hoặc hệ thống file phân tán nào. Điểm khác biệt lớn nhất giữa Stand-alone và các chế độ khác như Pseudo-distributed (giả phân tán) hay Fully-distributed (phân tán hoàn toàn) là khả năng mở rộng và chịu lỗi. Stand-alone không có khả năng chịu lỗi và không thể mở rộng quy mô xử lý. Tuy nhiên, ưu điểm lớn của nó là dễ cài đặt, cấu hình và gỡ lỗi, giúp người mới bắt đầu dễ dàng làm quen với các khái niệm cơ bản của Hadoop như Bash là gì và MapReduce mà không cần một cụm máy phức tạp. Nhược điểm chính là hiệu suất hạn chế và không phù hợp cho việc xử lý dữ liệu lớn thực tế.
Chỉnh sửa file cấu hình chính
Để cấu hình Hadoop, bạn cần chỉnh sửa một số file XML trong thư mục cấu hình của Hadoop, thường là /usr/local/hadoop/etc/hadoop. Hãy mở thư mục này và bắt đầu với core-site.xml. Sử dụng nano để chỉnh sửa file:
nano /usr/local/hadoop/etc/hadoop/core-site.xml
Thêm đoạn cấu hình sau vào giữa thẻ <configuration>:
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<description>The name of the default file system.</description>
</property>
Lưu ý: đường dẫn /app/hadoop/tmp cần được tạo thủ công sau này. Thuộc tính fs.defaultFS chỉ ra HDFS đang chạy cục bộ trên cổng 9000. Tiếp theo, chúng ta sẽ cấu hình mapred-site.xml. Mặc định, file này có thể có tên mapred-site.xml.template. Bạn cần đổi tên nó và chỉnh sửa:
cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
nano /usr/local/hadoop/etc/hadoop/mapred-site.xml
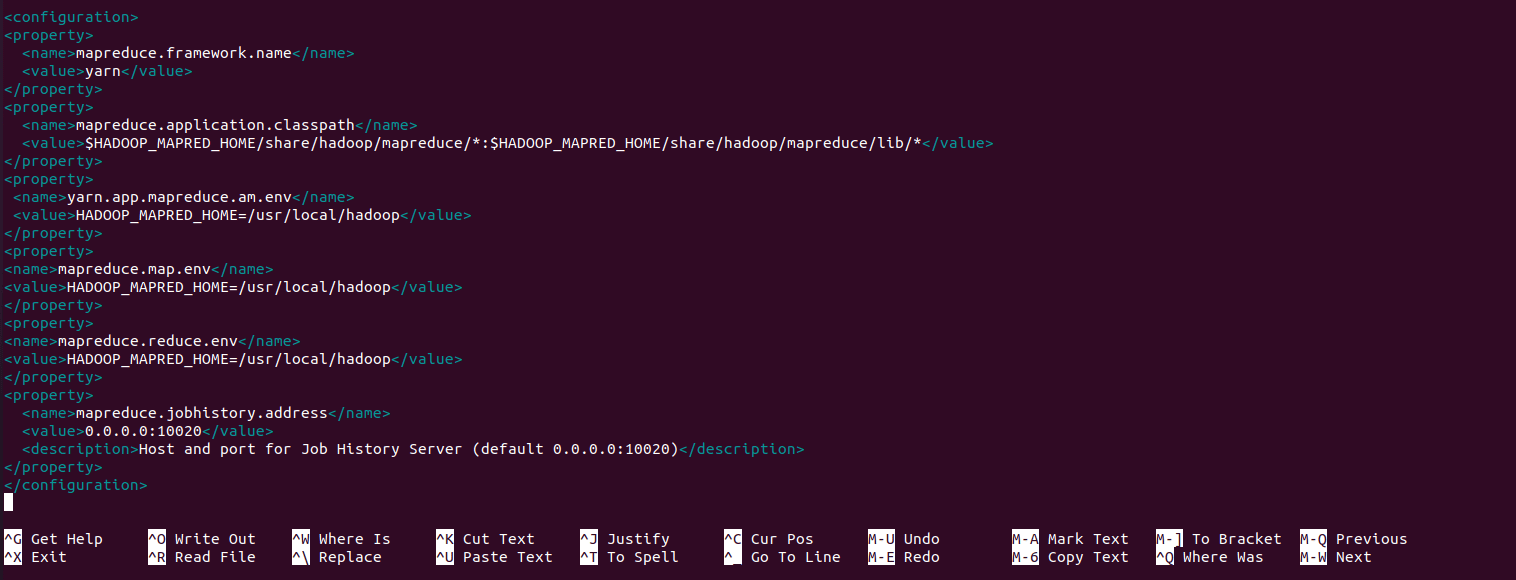
Thêm đoạn cấu hình sau vào giữa thẻ <configuration>:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>The framework for running MapReduce jobs.</description>
</property>
Cuối cùng, chỉnh sửa file hadoop-env.sh để trỏ đến JAVA_HOME chính xác. Mở file bằng nano:
nano /usr/local/hadoop/etc/hadoop/hadoop-env.sh
Tìm dòng export JAVA_HOME= và bỏ dấu # (nếu có), sau đó thiết lập đường dẫn chính xác đến JDK của bạn. Ví dụ:
export JAVA_HOME="/usr/lib/jvm/java-11-openjdk-amd64"
Lưu file và thoát. Bây giờ, Hadoop của bạn đã được cấu hình cơ bản cho chế độ Stand-alone.

Kiểm tra và chạy Hadoop trong môi trường thử nghiệm
Sau khi đã cấu hình xong, bước tiếp theo là kiểm tra xem Hadoop có hoạt động đúng cách không. Chúng ta sẽ chạy một ví dụ MapReduce đơn giản để xác minh mọi thứ.
Chạy ví dụ Hadoop MapReduce đơn giản
Để kiểm tra, Hadoop đi kèm với một số ví dụ MapReduce dựng sẵn rất tiện lợi. Chúng ta sẽ sử dụng một ví dụ phổ biến là grep để tìm kiếm các từ trong các file văn bản. Đầu tiên, hãy tạo một số file đầu vào và một thư mục tạm thời cho Hadoop:
mkdir -p /app/hadoop/tmp
echo "Hello Hadoop" > input.txt
echo "Hadoop is awesome" >> input.txt
echo "Welcome to Hadoop world" >> input.txt
Tiếp theo, hãy tạo một thư mục đầu vào trên HDFS và đưa file input.txt vào đó. Mặc dù ở chế độ Stand-alone HDFS không phải là hệ thống file phân tán thực sự, các lệnh vẫn cần được thực thi như thể bạn đang tương tác với HDFS.
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/your_username
hdfs dfs -mkdir input
hdfs dfs -put input.txt input
Bây giờ, chúng ta sẽ chạy ví dụ MapReduce grep. Ví dụ này sẽ tìm kiếm từ “Hadoop” trong các file đầu vào và đếm số lần xuất hiện của nó.
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar grep input output 'Hadoop'
Lệnh này sẽ chạy job MapReduce. Bạn sẽ thấy nhiều thông báo trên terminal về tiến trình của job. Sau khi job hoàn tất, kết quả sẽ được lưu vào thư mục output trên HDFS. Bạn có thể xem kết quả bằng cách:
hdfs dfs -cat output/*
Nếu bạn thấy kết quả hiển thị số lần từ “Hadoop” xuất hiện, nghĩa là Hadoop đã hoạt động thành công!
Kiểm tra các log quan trọng
Trong quá trình chạy Hadoop, việc kiểm tra các file log là rất quan trọng để gỡ lỗi và hiểu rõ hơn về hoạt động của hệ thống. Các file log chứa thông tin chi tiết về các sự kiện, lỗi và cảnh báo. Các file log của Hadoop thường được lưu trữ trong thư mục $HADOOP_HOME/logs. Bạn có thể truy cập thư mục này bằng lệnh:
cd $HADOOP_HOME/logs
ls -l
Trong thư mục này, bạn sẽ tìm thấy nhiều file log khác nhau, ví dụ như hadoop-your_username-namenode-your_hostname.log, hadoop-your_username-datanode-your_hostname.log hoặc các log của các tiến trình MapReduce. Để xem nội dung của một file log, bạn có thể sử dụng lệnh cat, less hoặc tail -f (để theo dõi log theo thời gian thực):
tail -f hadoop-your_username-namenode-your_hostname.log
Khi phân tích log, hãy chú ý đến các dòng có chứa từ khóa như “ERROR”, “WARN” hoặc “FATAL” để xác định các vấn đề tiềm ẩn. Đọc kỹ các thông báo lỗi sẽ giúp bạn hiểu nguyên nhân và cách khắc phục. Log là người bạn tốt nhất của bạn khi mọi thứ không diễn ra như mong đợi.

Mẹo và lưu ý khi sử dụng Hadoop Stand-alone trên Ubuntu
Chế độ Stand-alone là một điểm khởi đầu tuyệt vời, nhưng để có trải nghiệm tốt nhất, bạn cần lưu ý một số mẹo và hạn chế nhất định. AZWEB sẽ chia sẻ những kinh nghiệm này để bạn sử dụng Hadoop hiệu quả hơn.
Tối ưu hiệu năng
Khi làm việc với Hadoop ở chế độ Stand-alone, bạn cần nhớ rằng nó không được thiết kế cho hiệu năng cao hay xử lý dữ liệu quy mô lớn. Mục tiêu chính là học tập và thử nghiệm. Do đó, hãy tối giản cấu hình hết mức có thể. Tránh cố gắng tinh chỉnh quá nhiều thông số mà bạn chưa thực sự hiểu, vì điều đó có thể dẫn đến lỗi và khó gỡ lỗi hơn. Hạn chế tải quá nhiều job nặng hoặc tập dữ liệu quá lớn trên chế độ này. Stand-alone sẽ sử dụng tài nguyên của một máy duy nhất, và việc chạy các tác vụ cường độ cao có thể làm chậm hệ thống, thậm chí gây treo máy. Hãy giữ cho các tập dữ liệu thử nghiệm nhỏ và các job MapReduce đơn giản để đảm bảo trải nghiệm học tập mượt mà và hiệu quả.
Một số lưu ý về bảo mật và vận hành
Mặc dù bạn đang chạy Hadoop cục bộ, việc áp dụng các nguyên tắc bảo mật cơ bản vẫn rất quan trọng. Luôn sử dụng tài khoản người dùng riêng biệt cho các tác vụ Hadoop thay vì tài khoản root. Điều này giới hạn quyền truy cập và giảm thiểu rủi ro nếu có bất kỳ sự cố nào xảy ra. Thường xuyên kiểm tra môi trường Java của bạn. Đảm bảo bạn đang sử dụng phiên bản Java được hỗ trợ và không có xung đột phiên bản trên hệ thống. Apache Hadoop cũng thường xuyên phát hành các bản cập nhật và vá lỗi. Hãy theo dõi các bản cập nhật này và xem xét nâng cấp phiên bản Hadoop của bạn định kỳ để hưởng lợi từ các cải tiến về hiệu suất, tính năng mới và các bản vá bảo mật quan trọng. Mặc dù là chế độ Stand-alone, việc giữ cho hệ thống được cập nhật vẫn là một thực hành tốt.

Các vấn đề thường gặp và cách khắc phục
Khi làm việc với Hadoop, đặc biệt là khi mới bắt đầu, việc gặp phải lỗi là điều khó tránh khỏi. Đừng lo lắng, AZWEB sẽ giúp bạn nhận diện và khắc phục một số vấn đề phổ biến nhất.
Lỗi không nhận lệnh ‘hadoop’
Một trong những lỗi thường gặp nhất đối với người mới là khi gõ lệnh hadoop trong terminal và hệ thống báo command not found. Điều này thường xảy ra do biến môi trường PATH và HADOOP_HOME chưa được thiết lập chính xác hoặc chưa được áp dụng.
Cách khắc phục:
- Kiểm tra
HADOOP_HOME: Mở file cấu hình shell của bạn (ví dụ:~/.bashrchoặc~/.profile) và đảm bảo dòngexport HADOOP_HOME=/usr/local/hadoopđã được thêm vào và đường dẫn/usr/local/hadooplà chính xác. - Kiểm tra
PATH: Đảm bảo bạn đã thêm$HADOOP_HOME/binvà$HADOOP_HOME/sbinvào biếnPATHcủa mình. Dòng này sẽ trông giống nhưexport PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin. - Áp dụng thay đổi: Sau khi chỉnh sửa file cấu hình, hãy chạy lệnh
source ~/.bashrc(hoặc tên file cấu hình của bạn) để áp dụng các thay đổi ngay lập tức mà không cần khởi động lại terminal. - Kiểm tra lại: Gõ lệnh
echo $HADOOP_HOMEvàecho $PATH. Nếu các biến này hiển thị đúng đường dẫn, bạn có thể thử lại lệnhhadoop version.
Lỗi Java version không tương thích
Hadoop có yêu cầu cụ thể về phiên bản Java. Nếu bạn cài đặt nhiều phiên bản Java hoặc sử dụng một phiên bản không được hỗ trợ, bạn có thể gặp lỗi tương thích.
Cách khắc phục:
- Kiểm tra phiên bản Java hiện tại: Gõ
java -versionvàjavac -versionđể xem phiên bản Java đang hoạt động. - Kiểm tra
JAVA_HOMEtrong Hadoop: Mở file/usr/local/hadoop/etc/hadoop/hadoop-env.shvà đảm bảo dòngexport JAVA_HOME="/usr/lib/jvm/java-11-openjdk-amd64"(hoặc đường dẫn tới OpenJDK 8 của bạn) đã được thiết lập chính xác và bỏ dấu#nếu có. - Thay đổi phiên bản Java mặc định (nếu cần): Nếu bạn có nhiều phiên bản Java, bạn có thể sử dụng lệnh
sudo update-alternatives --config javavàsudo update-alternatives --config javacđể chọn phiên bản Java mặc định cho hệ thống. - Khởi động lại Terminal: Sau khi thực hiện các thay đổi, hãy đóng và mở lại Terminal để đảm bảo các biến môi trường được tải lại hoàn toàn.
Việc kiên nhẫn kiểm tra từng bước này sẽ giúp bạn giải quyết hầu hết các vấn đề liên quan đến cài đặt và cấu hình cơ bản của Hadoop.

Best Practices khi làm việc với Hadoop Stand-alone
Để tối ưu hóa trải nghiệm học tập và thử nghiệm với Hadoop ở chế độ Stand-alone, việc tuân thủ một số nguyên tắc thực hành tốt là rất quan trọng. Những lời khuyên từ AZWEB sẽ giúp bạn tránh các vấn đề phổ biến và xây dựng nền tảng vững chắc.
Luôn kiểm tra kỹ các bước cấu hình sau khi cài đặt. Mỗi thay đổi trong các file .xml hay .sh đều có thể ảnh hưởng đến cách Hadoop hoạt động. Sau mỗi lần chỉnh sửa, hãy kiểm tra lại biến môi trường và thử chạy một lệnh Hadoop đơn giản như hadoop version hoặc hdfs dfs -ls / để xác nhận rằng mọi thứ vẫn hoạt động. Đừng ngần ngại tham khảo tài liệu chính thức của Hadoop nếu có bất kỳ nghi ngờ nào.
Không nên sử dụng chế độ Stand-alone cho dữ liệu và job lớn. Như AZWEB đã đề cập, chế độ này chỉ dành cho mục đích học tập và phát triển cục bộ. Cố gắng xử lý hàng terabyte dữ liệu hoặc chạy các job MapReduce phức tạp trên một máy tính duy nhất sẽ dẫn đến hiệu suất kém, treo máy và trải nghiệm không tốt. Khi bạn sẵn sàng làm việc với dữ liệu lớn thực sự, hãy chuyển sang chế độ pseudo-distributed hoặc fully-distributed.
Định kỳ làm sạch file log để tiết kiệm dung lượng ổ cứng. Hadoop tạo ra rất nhiều file log, đặc biệt là khi bạn chạy nhiều job hoặc gặp lỗi. Những file này có thể nhanh chóng chiếm dụng không gian ổ cứng quý giá. Hãy tạo thói quen kiểm tra thư mục $HADOOP_HOME/logs và xóa các file log cũ, không cần thiết để duy trì hệ thống gọn gàng.
Cuối cùng, hãy kiểm tra cập nhật phiên bản Hadoop và Java để tránh lỗi bảo mật và tương thích. Cộng đồng Hadoop và Oracle (hoặc OpenJDK) thường xuyên phát hành các bản vá lỗi và cải tiến. Việc giữ cho phần mềm của bạn được cập nhật không chỉ cải thiện bảo mật mà còn đảm bảo bạn có được các tính năng mới nhất và hiệu suất tối ưu. Đây là một phần quan trọng của việc duy trì một môi trường phát triển lành mạnh.
Kết luận
Qua bài viết này, AZWEB đã cùng bạn khám phá từng bước chi tiết để cài đặt Hadoop trên Ubuntu 20.04 ở chế độ Stand-alone. Đây là một khởi đầu tuyệt vời cho bất kỳ ai muốn làm quen với thế giới của dữ liệu lớn. Bạn đã học được cách chuẩn bị môi trường, tải và cài đặt Hadoop, cấu hình các file quan trọng, chạy một ví dụ MapReduce cơ bản, và thậm chí là xử lý các vấn đề thường gặp.
Lợi ích lớn nhất khi bắt đầu với chế độ Stand-alone là sự đơn giản và dễ dàng trong việc thử nghiệm. Nó giúp bạn tập trung vào các khái niệm cốt lõi của Hadoop như HDFS và MapReduce mà không bị phân tâm bởi sự phức tạp của việc quản lý một cụm phân tán. Việc tự tay thực hiện các bước này không chỉ củng cố kiến thức lý thuyết mà còn giúp bạn xây dựng sự tự tin trong việc triển khai các hệ thống phức tạp hơn.
Chúng tôi khuyến khích bạn tiếp tục thực hành với các ví dụ khác, tìm hiểu sâu hơn về các lệnh HDFS và cách viết các job MapReduce của riêng mình. Khi bạn đã hoàn toàn tự tin với chế độ Stand-alone, bước tiếp theo tự nhiên sẽ là chuyển sang chế độ pseudo-distributed. Chế độ này mô phỏng một cụm phân tán trên một máy duy nhất, mở ra cánh cửa cho việc khám phá các tính năng nâng cao của Hadoop và chuẩn bị cho các ứng dụng dữ liệu lớn thực tế. Chúc bạn thành công trên hành trình trở thành một kiến trúc sư dữ liệu với AZWEB!
