Trong thế giới số hiện đại, dữ liệu được ví như “dầu mỏ” mới, là tài sản vô giá của mọi tổ chức. Mỗi ngày, chúng ta tạo ra hàng tỷ gigabyte dữ liệu từ mạng xã hội, thiết bị IoT, giao dịch trực tuyến và vô số nguồn khác. Sự bùng nổ dữ liệu này đặt ra một thách thức khổng lồ: làm thế nào để lưu trữ, quản lý và truy xuất tất cả thông tin này một cách hiệu quả? Các hệ thống lưu trữ truyền thống, vốn được thiết kế cho quy mô nhỏ hơn, nhanh chóng trở nên quá tải, tốn kém và thiếu linh hoạt. Đây chính là lúc Hyperscale Storage, hay lưu trữ quy mô lớn, xuất hiện như một giải pháp tất yếu. Bài viết này sẽ cùng bạn khám phá từ A-Z về công nghệ đột phá này, từ đặc điểm, lợi ích, ứng dụng cho đến cách triển khai tối ưu nhất.
Giới thiệu về lưu trữ quy mô lớn (Hyperscale Storage)
Bạn có bao giờ tự hỏi làm thế nào các gã khổng lồ công nghệ như Google, Amazon hay Facebook có thể lưu trữ và xử lý lượng dữ liệu khổng lồ của hàng tỷ người dùng mỗi ngày không? Câu trả lời nằm ở Hyperscale Storage. Đây không chỉ đơn thuần là việc có nhiều ổ cứng hơn, mà là một phương pháp kiến trúc hệ thống hoàn toàn khác biệt.

Sự bùng nổ dữ liệu trong thập kỷ qua đã tạo ra một áp lực chưa từng có lên hạ tầng công nghệ thông tin. Các doanh nghiệp từ lớn đến nhỏ đều phải đối mặt với việc khối lượng thông tin tăng theo cấp số nhân. Điều này đòi hỏi một giải pháp lưu trữ có khả năng mở rộng gần như vô hạn mà không làm gián đoạn hoạt động.
Các hệ thống lưu trữ truyền thống như SAN (Storage Area Network) hay NAS (Network Attached Storage) thường có kiến trúc tập trung. Khi cần mở rộng, bạn phải nâng cấp phần cứng trung tâm, một quá trình tốn kém, phức tạp và có giới hạn. Chúng giống như việc xây một tòa nhà cao hơn, đến một lúc nào đó bạn sẽ không thể xây thêm được nữa. Ngược lại, lưu trữ quy mô lớn ra đời để giải quyết triệt để vấn đề này. Nó được thiết kế để mở rộng theo chiều ngang, giống như việc xây thêm nhiều tòa nhà mới trong một khu đô thị, cho phép tăng trưởng không giới hạn.
Trong bài viết này, chúng ta sẽ đi sâu vào các đặc điểm cốt lõi của Hyperscale Storage, khám phá những lợi ích vượt trội mà nó mang lại, xem xét các ứng dụng thực tiễn trong điện toán đám mây, và tìm hiểu cách tối ưu chi phí khi triển khai. Hãy cùng AZWEB khám phá xu hướng công nghệ định hình tương lai của dữ liệu.
Đặc điểm và lợi ích của lưu trữ quy mô lớn
Vậy điều gì làm cho Hyperscale Storage trở nên khác biệt và mạnh mẽ đến vậy? Câu trả lời nằm ở những đặc điểm kiến trúc độc đáo và lợi ích trực tiếp mà nó mang lại cho các tổ chức.
Đặc điểm nổi bật của hyperscale storage
Điểm cốt lõi của lưu trữ quy mô lớn là kiến trúc phân tán. Thay vì dựa vào một vài thiết bị lưu trữ cao cấp, đắt tiền, hệ thống này sử dụng hàng ngàn, thậm chí hàng triệu máy chủ phổ thông (commodity hardware) kết nối với nhau qua mạng. Dữ liệu được chia nhỏ và phân tán trên toàn bộ các máy chủ này, loại bỏ hoàn toàn điểm nghẽn và rủi ro từ một điểm lỗi duy nhất.
Khả năng mở rộng theo cấp số nhân là đặc tính định danh của công nghệ này. Bạn có thể bắt đầu với một vài nút (node) lưu trữ và dễ dàng bổ sung thêm hàng trăm, hàng ngàn nút mới khi nhu cầu tăng lên. Quá trình này diễn ra mượt mà, không yêu cầu dừng hệ thống. Toàn bộ việc quản lý, từ phân bổ dữ liệu, sao lưu, đến xử lý lỗi, đều được tự động hóa cao độ nhờ các phần mềm thông minh. Điều này giúp giảm thiểu sự can thiệp của con người và tăng hiệu quả vận hành.
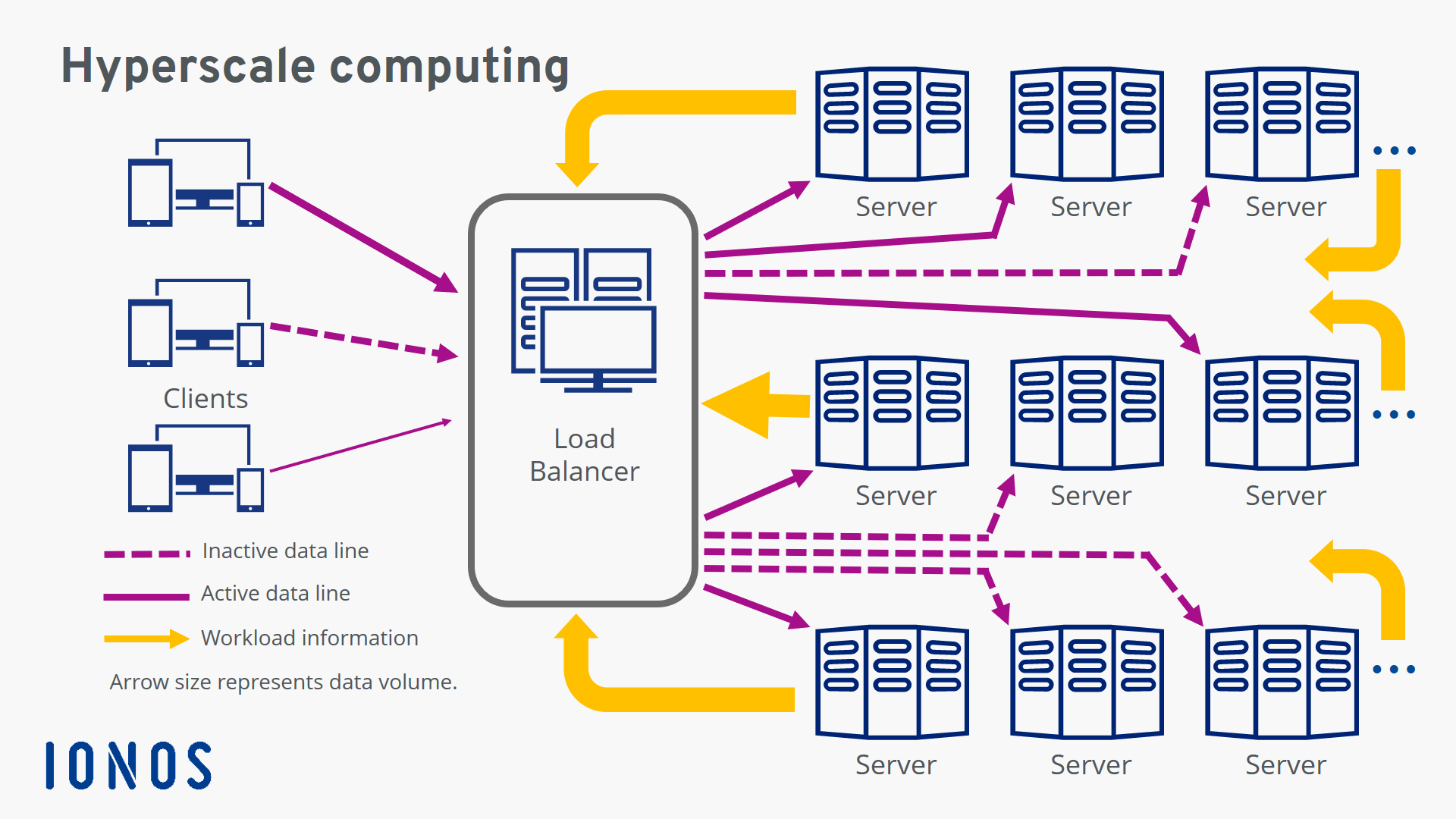
Cuối cùng, khả năng chịu lỗi và độ tin cậy là yếu tố không thể thiếu. Dữ liệu không chỉ được lưu ở một nơi mà được tự động sao chép ra nhiều bản và lưu trữ trên các máy chủ vật lý khác nhau, thậm chí ở các trung tâm dữ liệu khác nhau. Nếu một ổ cứng hay cả một máy chủ gặp sự cố, hệ thống sẽ tự động chuyển hướng truy cập đến các bản sao khác, đảm bảo dịch vụ luôn hoạt động liên tục.
Những lợi ích mang lại cho doanh nghiệp và tổ chức
Lợi ích rõ ràng nhất khi áp dụng Hyperscale Storage là tối ưu chi phí. Việc sử dụng phần cứng phổ thông thay vì các thiết bị chuyên dụng đắt đỏ giúp giảm đáng kể chi phí đầu tư ban đầu. Hơn nữa, mô hình “trả tiền theo mức sử dụng” (pay-as-you-go) cho phép doanh nghiệp chỉ chi trả cho dung lượng họ thực sự cần, tránh lãng phí tài nguyên.
Về mặt hiệu năng, kiến trúc phân tán cho phép xử lý song song các yêu cầu truy xuất dữ liệu. Điều này giúp tăng tốc độ đọc/ghi một cách đáng kinh ngạc, đặc biệt với các ứng dụng yêu cầu xử lý dữ liệu lớn như phân tích Big Data, trí tuệ nhân tạo (AI) hay streaming video. Dữ liệu có thể được truy cập nhanh chóng từ bất kỳ đâu.
Quan trọng hơn cả, Hyperscale Storage mang lại sự linh hoạt tuyệt vời. Doanh nghiệp không còn phải lo lắng về việc dự đoán nhu cầu lưu trữ trong tương lai. Hệ thống có thể tự động co giãn theo sự tăng trưởng dữ liệu đột biến, đảm bảo hoạt động kinh doanh không bị gián đoạn và luôn sẵn sàng cho những cơ hội mới.
Ứng dụng hyperscale storage trong điện toán đám mây
Điện toán đám mây và Hyperscale Storage có mối quan hệ cộng sinh. Bạn không thể có cái này mà không có cái kia. Chính lưu trữ quy mô lớn là nền tảng vững chắc cho phép các dịch vụ đám mây phát triển mạnh mẽ như ngày nay.
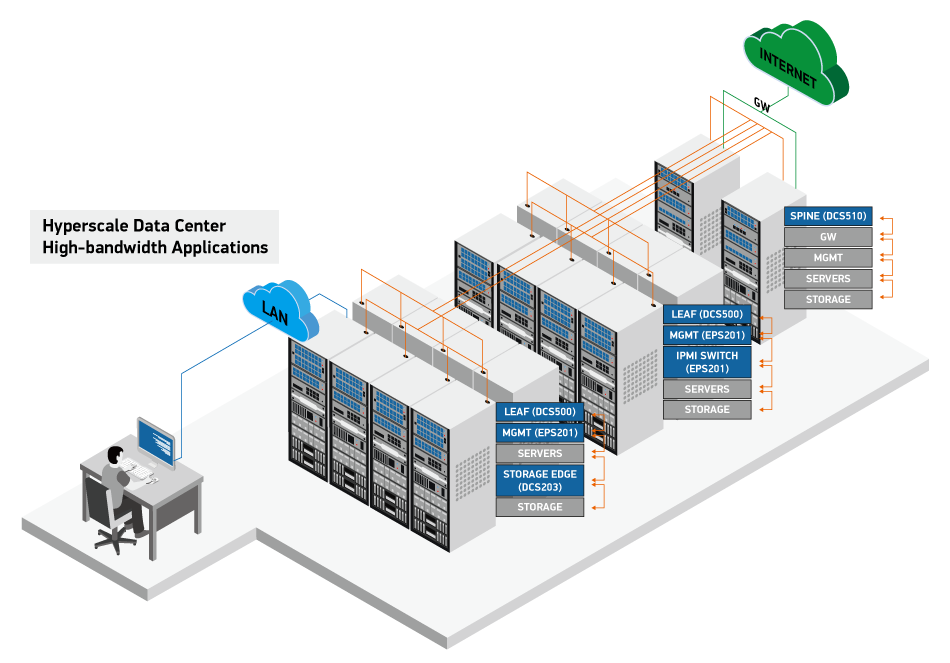
Vai trò của lưu trữ quy mô lớn trong Cloud Computing
Khi bạn tải một tệp lên Google Drive, xem một bộ phim trên Netflix, hay lưu trữ ảnh trên iCloud, bạn đang trực tiếp sử dụng Hyperscale Storage. Các nhà cung cấp đám mây sử dụng kiến trúc này để cung cấp các dịch vụ lưu trữ đa dạng, đáp ứng mọi nhu cầu của khách hàng. Nó là xương sống cho các dịch vụ lưu trữ đối tượng (Object Storage) như Amazon S3, nơi lưu trữ hàng nghìn tỷ đối tượng dữ liệu phi cấu trúc.
Bên cạnh đó, nó cũng hỗ trợ các dịch vụ lưu trữ khối (Block Storage) như Amazon EBS, cung cấp các ổ đĩa ảo cho máy chủ đám mây, và dịch vụ lưu trữ tệp (File Storage) như Amazon EFS. Vai trò cốt lõi của Hyperscale Storage là đảm bảo khả năng mở rộng gần như vô hạn cho khách hàng. Khi một ứng dụng của bạn trở nên phổ biến và lượng người dùng tăng vọt, hạ tầng lưu trữ đám mây sẽ tự động mở rộng theo để đáp ứng, mà bạn không cần phải can thiệp.
Ví dụ thực tiễn từ các nhà cung cấp dịch vụ đám mây lớn
Amazon Web Services (AWS), Microsoft Azure, và Google Cloud Platform (GCP) là những ví dụ điển hình nhất về việc ứng dụng thành công Hyperscale Storage. AWS S3, một trong những dịch vụ lưu trữ lớn nhất thế giới, được xây dựng hoàn toàn trên kiến trúc này. Nó cung cấp độ bền dữ liệu lên tới 99.999999999% (11 số 9), một con số không tưởng với các hệ thống truyền thống.
Microsoft Azure sử dụng Azure Blob Storage để phục vụ cho các ứng dụng từ lưu trữ dữ liệu lớn, sao lưu, đến phân phối nội dung đa phương tiện. Tương tự, Google Cloud Storage là nền tảng cho các dịch vụ của Google như YouTube và Google Photos. Các ngành công nghiệp cũng nhanh chóng nắm bắt công nghệ này. Trong tài chính, các ngân hàng sử dụng lưu trữ đám mây quy mô lớn để lưu trữ hàng tỷ giao dịch và phân tích gian lận. Ngành y tế dùng nó để lưu trữ hồ sơ bệnh án điện tử (EMR) và hình ảnh y tế. Ngành giải trí thì dựa vào đó để lưu trữ và phát trực tuyến các nội dung video chất lượng cao cho hàng triệu người xem toàn cầu.
Cách mở rộng quy mô linh hoạt và tối ưu chi phí với hyperscale storage
Một trong những sức hấp dẫn lớn nhất của Hyperscale Storage là khả năng mở rộng quy mô một cách linh hoạt mà vẫn kiểm soát được chi phí. Điều này không xảy ra một cách ngẫu nhiên mà dựa trên những chiến lược và công nghệ thông minh.
Chiến lược mở rộng quy mô theo nhuều thực tế
Khác với cách tiếp cận truyền thống “mua trước, dùng sau”, Hyperscale Storage cho phép mở rộng theo nhu cầu thực tế. Khả năng co giãn linh hoạt (elasticity) là chìa khóa. Hệ thống có thể tự động bổ sung tài nguyên lưu trữ khi phát hiện nhu cầu tăng cao, ví dụ như trong một chiến dịch marketing lớn hoặc một sự kiện trực tuyến. Ngược lại, nó cũng có thể giải phóng tài nguyên khi nhu cầu giảm xuống để tiết kiệm chi phí.
Quá trình này hoàn toàn không làm gián đoạn dịch vụ. Người dùng cuối sẽ không hề nhận thấy sự thay đổi nào về hạ tầng phía sau. Để làm được điều này, các hệ thống Hyperscale sử dụng phần mềm quản lý thông minh, thường được gọi là IaaS là gì. Phần mềm này đóng vai trò như bộ não, liên tục theo dõi hiệu suất và dung lượng, sau đó tự động phân bổ tài nguyên đến nơi cần thiết nhất, đảm bảo hệ thống luôn hoạt động ở trạng thái tối ưu.
Giải pháp tối ưu chi phí khi triển khai lưu trữ quy mô lớn
Chi phí luôn là bài toán quan trọng đối với mọi doanh nghiệp. Hyperscale Storage giải quyết vấn đề này bằng cách tận dụng phần cứng phổ thông (commodity hardware). Thay vì đầu tư vào các hệ thống độc quyền đắt đỏ, kiến trúc này cho phép sử dụng các máy chủ x86 tiêu chuẩn từ nhiều nhà cung cấp khác nhau. Điều này không chỉ giảm chi phí mua sắm mà còn tránh được sự phụ thuộc vào một nhà cung cấp duy nhất.

Bên cạnh đó, việc sử dụng các công nghệ phần mềm nguồn mở như Ceph, GlusterFS hay MinIO cũng là một yếu tố giúp giảm chi phí bản quyền phần mềm. Các giải pháp này cung cấp những tính năng mạnh mẽ tương đương các sản phẩm thương mại nhưng với chi phí thấp hơn nhiều. Cuối cùng, việc tối ưu hiệu suất lưu trữ, chẳng hạn như tự động phân tầng dữ liệu (di chuyển dữ liệu ít truy cập đến các ổ đĩa chậm hơn, rẻ hơn) và nén dữ liệu, giúp giảm chi phí vận hành liên quan đến điện năng và làm mát trong trung tâm dữ liệu.
So sánh lưu trữ quy mô lớn với các giải pháp lưu trữ truyền thống
Để thực sự hiểu giá trị của Hyperscale Storage, chúng ta cần đặt nó bên cạnh các giải pháp lưu trữ truyền thống và xem xét những khác biệt cơ bản về kiến trúc, hiệu suất và chi phí.
Điểm khác biệt về kiến trúc và khả năng mở rộng
Sự khác biệt lớn nhất nằm ở cách chúng mở rộng. Lưu trữ truyền thống (SAN/NAS) tuân theo mô hình “scale-up” (mở rộng theo chiều dọc). Khi cần thêm dung lượng hoặc hiệu năng, bạn phải nâng cấp bộ điều khiển trung tâm hoặc thêm các khay đĩa vào hệ thống hiện có. Quá trình này có giới hạn vật lý và chi phí tăng theo cấp số nhân khi hệ thống đạt đến ngưỡng.
Ngược lại, Hyperscale Storage sử dụng mô hình “scale-out” (mở rộng theo chiều ngang). Thay vì làm cho một hệ thống duy nhất mạnh hơn, bạn chỉ cần thêm các máy chủ (nút) mới vào cụm (cluster). Kiến trúc phân tán này cho phép hệ thống mở rộng gần như vô hạn. Mỗi nút mới không chỉ bổ sung dung lượng mà còn cả sức mạnh xử lý và băng thông mạng, giúp hiệu năng tổng thể tăng tuyến tính theo quy mô. Tính linh hoạt và khả năng tự động hóa của mô hình scale-out vượt trội hoàn toàn so với sự cứng nhắc của scale-up.

So sánh hiệu suất, chi phí và quản lý
Về hiệu suất, hệ thống truyền thống có thể rất nhanh cho các tác vụ tập trung, nhưng dễ trở thành điểm nghẽn cổ chai khi khối lượng công việc tăng lên. Hyperscale Storage, với khả năng xử lý song song trên nhiều nút, lại tỏa sáng với các ứng dụng phân tán và dữ liệu lớn. Nó có thể xử lý hàng triệu yêu cầu đồng thời mà không bị suy giảm hiệu năng.
Về chi phí, mô hình truyền thống đòi hỏi vốn đầu tư ban đầu (CAPEX) rất lớn. Ngược lại, Hyperscale Storage chuyển gánh nặng sang chi phí vận hành (OPEX), cho phép doanh nghiệp bắt đầu nhỏ và tăng dần chi phí khi quy mô phát triển. Điều này giúp tối ưu hóa dòng tiền và giảm rủi ro đầu tư.
Cuối cùng, về quản lý, hệ thống truyền thống cần các quản trị viên có kỹ năng chuyên sâu về phần cứng cụ thể. Trong khi đó, Hyperscale Storage được quản lý chủ yếu bằng phần mềm và tự động hóa. Mặc dù đòi hỏi kỹ năng về phần mềm và DevOps, nhưng nó giúp giảm đáng kể công sức quản lý thủ công khi hệ thống phát triển đến quy mô hàng nghìn nút.
Các thách thức và giải pháp trong triển khai lưu trữ quy mô lớn
Mặc dù mang lại nhiều lợi ích vượt trội, việc triển khai và vận hành một hệ thống Hyperscale Storage không phải là không có thách thức. Hiểu rõ những khó khăn này và có giải pháp phù hợp là yếu tố quyết định thành công.
Thách thức về an ninh và bảo mật dữ liệu
Khi dữ liệu được phân tán trên hàng ngàn máy chủ và có thể nằm ở nhiều vị trí địa lý khác nhau, bề mặt tấn công tiềm ẩn cũng tăng lên. Rủi ro về truy cập trái phép, vi phạm dữ liệu và mất mát thông tin là những lo ngại hàng đầu. Việc đảm bảo tính nhất quán của các chính sách bảo mật trên toàn bộ hệ thống là một nhiệm vụ phức tạp.
Để đối phó với thách thức này, các giải pháp bảo mật nhiều lớp là bắt buộc. Mã hóa dữ liệu là tuyến phòng thủ đầu tiên, bao gồm cả mã hóa khi dữ liệu đang được lưu trữ (encryption at rest) và khi đang được truyền đi (encryption in transit). Hệ thống quản lý danh tính và quyền truy cập (IAM) chặt chẽ giúp đảm bảo chỉ những người dùng và ứng dụng được ủy quyền mới có thể truy cập dữ liệu. Ngoài ra, việc sao lưu dữ liệu ra nhiều vùng địa lý (multi-region replication) không chỉ tăng cường khả năng phục hồi sau thảm họa mà còn là một biện pháp bảo vệ quan trọng trước các cuộc tấn công có chủ đích.
Khó khăn trong quản lý và vận hành hệ thống phức tạp
Dù được tự động hóa cao, việc quản lý một hệ thống bao gồm hàng nghìn thành phần phần cứng và phần mềm vẫn vô cùng phức tạp. Việc giám sát tình trạng, chẩn đoán sự cố và lên kế hoạch nâng cấp đòi hỏi một đội ngũ kỹ thuật có chuyên môn cao về cả hệ thống phân tán, mạng và phần mềm.
Giải pháp cho vấn đề này nằm ở việc tăng cường tự động hóa hơn nữa. Việc áp dụng các công nghệ Trí tuệ nhân tạo (AI) và Học máy (Machine Learning) đang trở thành xu hướng. Các thuật toán AI/ML có thể phân tích các mẫu hoạt động của hệ thống để dự đoán lỗi phần cứng trước khi chúng xảy ra, tự động tối ưu hóa vị trí lưu trữ dữ liệu để cải thiện hiệu năng, và phát hiện các hoạt động bất thường có thể là dấu hiệu của một cuộc tấn công an ninh. Đầu tư vào các công cụ giám sát tập trung và tự động hóa quy trình vận hành (DevOps) là chìa khóa để quản lý hiệu quả hệ thống ở quy mô lớn.
Tương lai và xu hướng phát triển của công nghệ lưu trữ dữ liệu quy mô lớn
Công nghệ Hyperscale Storage không ngừng phát triển để đáp ứng những yêu cầu ngày càng khắt khe của thế giới số. Các xu hướng mới đang định hình tương lai của lĩnh vực này, hứa hẹn mang lại hiệu suất, trí thông minh và bảo mật cao hơn nữa.
Xu hướng nổi bật nhất là sự tích hợp ngày càng sâu rộng của Trí tuệ nhân tạo (AI) và Học máy (ML) vào việc quản lý lưu trữ. Các hệ thống trong tương lai sẽ không chỉ tự động hóa các tác vụ thông thường mà còn có khả năng tự tối ưu hóa (self-optimizing). Chúng có thể tự động dự đoán nhu cầu, di chuyển dữ liệu giữa các tầng lưu trữ (nóng, lạnh, băng) một cách thông minh để cân bằng giữa hiệu suất và chi phí, và thậm chí tự vá lỗi bảo mật mà không cần sự can thiệp của con người.
Sự bùng nổ của Điện toán biên (Edge Computing) cũng đang tạo ra một tác động lớn. Với hàng tỷ thiết bị IoT tạo ra dữ liệu tại rìa mạng, nhu cầu xử lý và lưu trữ dữ liệu gần nguồn phát sinh ngày càng tăng. Kiến trúc Hyperscale sẽ mở rộng ra khỏi các trung tâm dữ liệu tập trung để bao gồm cả các “micro data center” tại biên. Điều này đòi hỏi các giải pháp lưu trữ có khả năng đồng bộ hóa dữ liệu một cách hiệu quả giữa biên và đám mây trung tâm.
Cuối cùng, bảo mật vẫn là ưu tiên hàng đầu. Các công nghệ lưu trữ phi tập trung, lấy cảm hứng từ blockchain, đang được nghiên cứu để tạo ra các hệ thống có khả năng chống giả mạo và kiểm duyệt cao hơn. Các phương pháp mã hóa tiên tiến như mã hóa đồng cấu (homomorphic encryption), cho phép xử lý dữ liệu mà không cần giải mã, cũng hứa hẹn sẽ cách mạng hóa cách chúng ta bảo vệ dữ liệu nhạy cảm trong các môi trường lưu trữ quy mô lớn.
Các vấn đề thường gặp và cách xử lý
Khi vận hành một hệ thống Hyperscale Storage, các kỹ sư có thể đối mặt với một số vấn đề phức tạp. Hiểu rõ nguyên nhân và có phương án xử lý là rất quan trọng để duy trì sự ổn định và hiệu quả.
Vấn đề hiệu năng giảm khi mở rộng quy mô
Một trong những thách thức phổ biến là hiệu năng không tăng tuyến tính như kỳ vọng, thậm chí giảm khi hệ thống mở rộng đến một quy mô nhất định. Nguyên nhân có thể đến từ nhiều yếu tố, chẳng hạn như tắc nghẽn mạng, sự mất cân bằng trong việc phân bổ dữ liệu (một số nút bị quá tải trong khi các nút khác lại nhàn rỗi), hoặc “hiệu ứng hàng xóm ồn ào” (noisy neighbor effect) khi một ứng dụng sử dụng quá nhiều tài nguyên, ảnh hưởng đến các ứng dụng khác.
Để giải quyết vấn đề này, việc tối ưu hóa cân bằng tải là rất quan trọng. Các thuật toán phân phối dữ liệu thông minh cần được áp dụng để đảm bảo dữ liệu được rải đều trên toàn bộ cụm. Việc triển khai các chính sách Chất lượng dịch vụ (QoS) giúp giới hạn tài nguyên mà mỗi ứng dụng có thể sử dụng, ngăn chặn tình trạng “hàng xóm ồn ào”. Ngoài ra, việc thiết kế và nâng cấp hạ tầng mạng để có băng thông cao và độ trễ thấp cũng là yếu tố then chốt.
Khó khăn trong đồng bộ và sao lưu dữ liệu đa trung tâm
Để đảm bảo khả năng phục hồi sau thảm họa và tính sẵn sàng cao, dữ liệu thường được sao chép (replicate) đến nhiều trung tâm dữ liệu ở các vị trí địa lý khác nhau. Tuy nhiên, việc giữ cho dữ liệu ở mọi nơi luôn nhất quán và cập nhật là một thách thức lớn, đặc biệt khi có độ trễ mạng giữa các trung tâm.
Các kỹ thuật sao chép dữ liệu hiệu quả là giải pháp cho vấn đề này. Sao chép đồng bộ (synchronous replication) đảm bảo dữ liệu được ghi đồng thời ở tất cả các nơi, mang lại tính nhất quán cao nhất nhưng có thể làm tăng độ trễ cho ứng dụng. Ngược lại, sao chép không đồng bộ (asynchronous replication) cho phép ứng dụng tiếp tục hoạt động mà không cần chờ dữ liệu được ghi ở các địa điểm từ xa, giúp cải thiện hiệu năng nhưng có thể có một khoảng trễ nhỏ về dữ liệu. Việc lựa chọn kỹ thuật phù hợp phụ thuộc vào yêu cầu cụ thể của từng ứng dụng về tính nhất quán và hiệu năng.
Best practices triển khai lưu trữ quy mô lớn
Triển khai thành công một hệ thống Hyperscale Storage đòi hỏi nhiều hơn là chỉ mua sắm phần cứng và cài đặt phần mềm. Dưới đây là những thực tiễn tốt nhất mà các tổ chức nên tuân theo để đảm bảo dự án đi đúng hướng và mang lại giá trị tối đa.
Lên kế hoạch rõ ràng, đánh giá nhu cầu lưu trữ thực tế: Trước khi bắt đầu, hãy dành thời gian phân tích kỹ lưỡng các loại dữ liệu bạn cần lưu trữ, tốc độ tăng trưởng dự kiến, và yêu cầu về hiệu suất, độ bền. Đừng xây dựng một hệ thống quá lớn so với nhu cầu, nhưng cũng cần có kế hoạch mở rộng rõ ràng cho tương lai.
Ưu tiên tự động hóa và giám sát liên tục: Tự động hóa là linh hồn của Hyperscale. Hãy tự động hóa mọi thứ có thể, từ việc triển khai các nút mới, cấu hình, đến sao lưu và phục hồi. Thiết lập một hệ thống giám sát toàn diện để theo dõi sức khỏe của từng thành phần, từ đó phát hiện sớm các vấn đề và phản ứng kịp thời.
Không nên chọn giải pháp chỉ dựa trên chi phí ngắn hạn: Mặc dù việc sử dụng phần cứng phổ thông giúp giảm chi phí, nhưng đừng chọn những thiết bị rẻ nhất mà không xem xét đến độ tin cậy, hiệu suất và mức tiêu thụ điện năng. Tổng chi phí sở hữu (TCO) trong dài hạn, bao gồm cả chi phí vận hành và bảo trì, mới là thước đo quan trọng nhất.
Đầu tư đào tạo đội ngũ vận hành chuyên sâu: Con người vẫn là yếu tố quyết định. Hãy đầu tư vào việc đào tạo và phát triển đội ngũ kỹ sư có kỹ năng về hệ thống phân tán, mạng, DevOps và các công nghệ phần mềm nguồn mở. Một đội ngũ giỏi sẽ có thể khai thác tối đa sức mạnh của hệ thống và xử lý các sự cố phức tạp.
Kết luận
Chúng ta đang sống trong kỷ nguyên mà dữ liệu là động lực cho sự đổi mới và tăng trưởng. Trong bối cảnh đó, Hyperscale Storage đã chứng tỏ vai trò không thể thiếu của mình. Nó không còn là công nghệ dành riêng cho các gã khổng lồ công nghệ mà đã trở thành một giải pháp chiến lược cho bất kỳ doanh nghiệp nào muốn khai thác sức mạnh của dữ liệu lớn. Với khả năng mở rộng gần như vô hạn, chi phí tối ưu và độ tin cậy vượt trội, nó phá vỡ những giới hạn của các hệ thống lưu trữ truyền thống, mở ra những cơ hội mới cho phân tích dữ liệu, AI và các ứng dụng đòi hỏi cao.
Việc chuyển đổi sang Hyperscale Storage là một hành trình, đòi hỏi sự đầu tư về kế hoạch, công nghệ và con người. Tuy nhiên, những lợi ích mà nó mang lại về sự linh hoạt, hiệu quả và khả năng cạnh tranh là vô cùng to lớn. Đã đến lúc các doanh nghiệp cần nghiêm túc nghiên cứu và bắt đầu ứng dụng công nghệ này để không bị tụt hậu trong cuộc cách mạng dữ liệu. Hãy bắt đầu bằng việc đánh giá nhu cầu của bạn và tìm kiếm một đối tác tin cậy như AZWEB để đồng hành trên con đường chinh phục thế giới dữ liệu quy mô lớn.