Bạn đã bao giờ thấy máy chủ Linux của mình chậm đi một cách bất thường? Khi kiểm tra, có thể bạn sẽ nghe ai đó hỏi: “Load Average là bao nhiêu?”. Đây là một chỉ số quan trọng nhưng lại thường gây bối rối cho nhiều người dùng mới, thậm chí cả những quản trị viên hệ thống đã có kinh nghiệm. Họ thường nhầm lẫn nó với mức sử dụng CPU (%CPU) và không biết cách diễn giải ba con số bí ẩn mà hệ thống hiển thị. Việc hiểu sai có thể dẫn đến chẩn đoán và xử lý sự cố không chính xác, gây lãng phí thời gian và ảnh hưởng đến hiệu suất hệ thống.
Bài viết này sẽ là kim chỉ nam giúp bạn làm sáng tỏ mọi thắc mắc về Load Average. Chúng ta sẽ cùng nhau đi từ khái niệm cơ bản, cách đọc và hiểu ý nghĩa các chỉ số, phân biệt rõ ràng với %CPU, cho đến việc sử dụng các công cụ mạnh mẽ để giám sát và đưa ra giải pháp xử lý hiệu quả khi Load Average tăng cao. Hãy cùng AZWEB khám phá cách làm chủ chỉ số quan trọng này để tối ưu hóa hiệu suất máy chủ Linux của bạn.

Khái niệm Load Average là gì trong Linux
Để quản lý hiệu quả một hệ thống Linux, việc hiểu rõ các chỉ số hiệu suất là điều kiện tiên quyết. Trong số đó, Load Average là một trong những thông số cốt lõi, cung cấp cái nhìn tổng quan về mức độ “bận rộn” của hệ thống.
Định nghĩa Load Average
Load Average (Tải trung bình) là một chỉ số đo lường số lượng tiến trình (process) đang chờ được xử lý bởi CPU, cộng với số lượng tiến trình đang được CPU thực thi tại một thời điểm. Nói một cách đơn giản, nó thể hiện “độ dài hàng đợi” công việc mà CPU phải giải quyết. Hãy tưởng tượng CPU của bạn là một nhân viên thu ngân tại siêu thị. Load Average chính là số người đang được thanh toán cộng với số người đang xếp hàng chờ đến lượt.
Chỉ số này không chỉ phản ánh các tiến trình đang thực sự sử dụng CPU (running state) mà còn cả những tiến trình đang ở trong trạng thái chờ không thể bị gián đoạn (uninterruptible sleep state), thường là chờ các hoạt động I/O (Input/Output) như đọc/ghi đĩa hoàn tất. Đây là điểm khác biệt quan trọng khiến Load Average trở thành một thước đo toàn diện hơn về tải hệ thống so với chỉ riêng mức sử dụng CPU. Nó cho bạn biết hệ thống đang chịu áp lực công việc lớn đến mức nào.
Ý nghĩa và cách đọc chỉ số Load Average
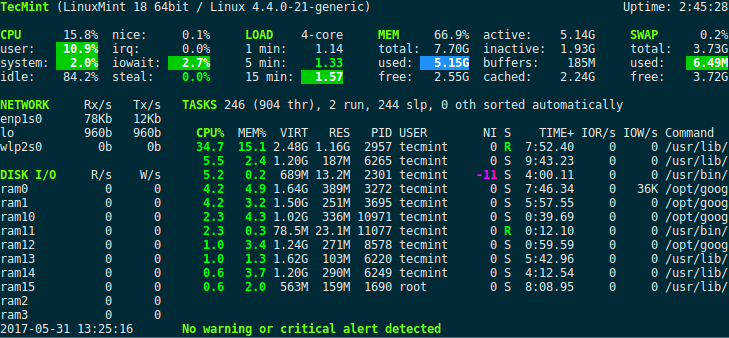
Khi bạn kiểm tra Load Average bằng các lệnh như uptime hay top, hệ thống sẽ trả về ba con số. Ví dụ: load average: 0.15, 0.20, 0.25. Ba con số này lần lượt đại diện cho tải trung bình trong 1 phút, 5 phút và 15 phút vừa qua.
- Số đầu tiên (1 phút): Phản ánh tải hệ thống trong khoảng thời gian gần nhất. Nó rất nhạy với các biến động đột ngột. Nếu con số này cao, có thể hệ thống vừa trải qua một đợt tăng tải đột xuất.
- Số thứ hai (5 phút): Cung cấp cái nhìn trung bình, ổn định hơn về tải trong 5 phút qua.
- Số thứ ba (15 phút): Cho thấy xu hướng tải dài hạn của hệ thống. Đây là chỉ số quan trọng nhất để đánh giá xem hệ thống có đang bị quá tải liên tục hay không.
Để diễn giải các con số này một cách chính xác, bạn cần biết hệ thống của mình có bao nhiêu lõi CPU. Một quy tắc chung là:
- Load Average < Số lõi CPU: Hệ thống đang hoạt động thoải mái, còn dư tài nguyên.
- Load Average ≈ Số lõi CPU: Hệ thống đang hoạt động ở mức tối ưu, tất cả các lõi đều được tận dụng.
- Load Average > Số lõi CPU: Hệ thống đang bị quá tải. Có nhiều tiến trình phải xếp hàng chờ CPU xử lý hơn số lượng CPU có thể giải quyết, dẫn đến tình trạng chậm chạp.
Ví dụ, trên một hệ thống có 4 lõi CPU, nếu Load Average 15 phút là 3.50, điều này có nghĩa là hệ thống đang hoạt động tốt. Nhưng nếu con số này là 8.00, tức là tải hệ thống đang cao gấp đôi công suất xử lý, và bạn cần phải tìm hiểu nguyên nhân ngay lập tức.
So sánh Load Average với %CPU
Một trong những nhầm lẫn phổ biến nhất khi giám sát hiệu suất Linux là đánh đồng Load Average với %CPU (CPU Usage). Mặc dù chúng có liên quan mật thiết, nhưng về bản chất, chúng đo lường hai khía cạnh hoàn toàn khác nhau của hiệu suất hệ thống.
Khác biệt về bản chất và cách đo lường
Hãy quay lại với ví dụ nhân viên thu ngân (CPU).
- %CPU (CPU Usage): Chỉ số này đo lường tỷ lệ phần trăm thời gian mà CPU đang bận rộn xử lý công việc trong một khoảng thời gian nhất định. Nó giống như việc bạn hỏi: “Trong một giờ qua, nhân viên thu ngân đã làm việc bao nhiêu phần trăm thời gian?”. Nếu %CPU là 100%, có nghĩa là nhân viên thu ngân đã làm việc không nghỉ một giây nào.
- Load Average: Chỉ số này đo lường số lượng công việc (tiến trình) đang xếp hàng chờ được xử lý. Nó giống như việc bạn nhìn vào hàng đợi và nói: “Trung bình có bao nhiêu khách hàng đang xếp hàng chờ thanh toán?”.
Sự khác biệt cốt lõi nằm ở chỗ: %CPU là thước đo mức độ sử dụng tại một thời điểm, còn Load Average là thước đo nhu cầu hay áp lực công việc theo thời gian. Một hệ thống có thể có %CPU cao nhưng Load Average thấp, và ngược lại. Load Average còn tính cả các tiến trình đang chờ I/O, trong khi %CPU chỉ tập trung vào các tiến trình đang thực sự chiếm dụng chu kỳ xử lý của CPU.
Ảnh hưởng của Load Average và %CPU đến hiệu suất hệ thống
Hiểu rõ sự khác biệt này giúp chúng ta chẩn đoán vấn đề hiệu suất một cách chính xác hơn. Có hai kịch bản thường gặp:
- Load Average cao nhưng %CPU thấp:
- Hiện tượng: Hệ thống rất chậm, các ứng dụng phản hồi ì ạch, nhưng khi kiểm tra thì thấy %CPU ở mức thấp.
- Nguyên nhân: Đây là dấu hiệu điển hình của tình trạng “thắt cổ chai” I/O (I/O bottleneck). Nhiều tiến trình đang bị kẹt trong hàng đợi không phải vì CPU bận, mà vì chúng đang phải chờ một tài nguyên khác, chẳng hạn như ổ đĩa cứng quá chậm, kết nối mạng chập chờn, hoặc một dịch vụ bên ngoài phản hồi chậm. Các tiến trình này làm tăng Load Average nhưng không tiêu tốn tài nguyên CPU.
- Ảnh hưởng: Trải nghiệm người dùng sẽ rất tệ vì mọi tác vụ liên quan đến đọc/ghi dữ liệu đều bị trì trệ.
- Load Average cao và %CPU cũng cao:
- Hiện tượng: Hệ thống chậm và quạt tản nhiệt của CPU có thể quay rất mạnh.
- Nguyên nhân: Đây là trường hợp quá tải CPU kinh điển (CPU-bound). Có quá nhiều tiến trình đang tranh giành thời gian xử lý của CPU. Điều này thường xảy ra khi chạy các tác vụ tính toán nặng như biên dịch mã nguồn, xử lý video, hoặc các thuật toán phức tạp.
- Ảnh hưởng: Toàn bộ hệ thống sẽ bị chậm lại vì CPU không còn đủ sức để xử lý kịp thời các yêu cầu.
Việc phân biệt được hai kịch bản này là chìa khóa để bạn có thể đưa ra giải pháp phù hợp: nâng cấp ổ đĩa SSD để giải quyết I/O bottleneck, hay tối ưu hóa mã nguồn và nâng cấp CPU để xử lý vấn đề CPU-bound. Tham khảo thêm bài viết Ram là gì để hiểu về vai trò bộ nhớ trong hiệu suất hệ thống.

Cách kiểm tra Load Average bằng các lệnh trong Linux
Linux cung cấp nhiều công cụ dòng lệnh mạnh mẽ để bạn có thể nhanh chóng kiểm tra Load Average và các thông số hiệu suất khác. Nắm vững các lệnh này là kỹ năng cơ bản đối với bất kỳ quản trị viên hệ thống nào.
Sử dụng lệnh uptime và top để xem Load Average
Đây là hai lệnh phổ biến và đơn giản nhất để bắt đầu.
1. Lệnh uptime:
Đây là cách nhanh nhất để xem Load Average. Chỉ cần mở terminal và gõ lệnh:
uptime
Kết quả trả về sẽ trông giống như sau:
10:30:15 up 2 days, 15:45, 1 user, load average: 0.05, 0.10, 0.12
Phần cuối cùng load average: 0.05, 0.10, 0.12 chính là ba chỉ số tải trung bình trong 1 phút, 5 phút và 15 phút mà chúng ta đã tìm hiểu.
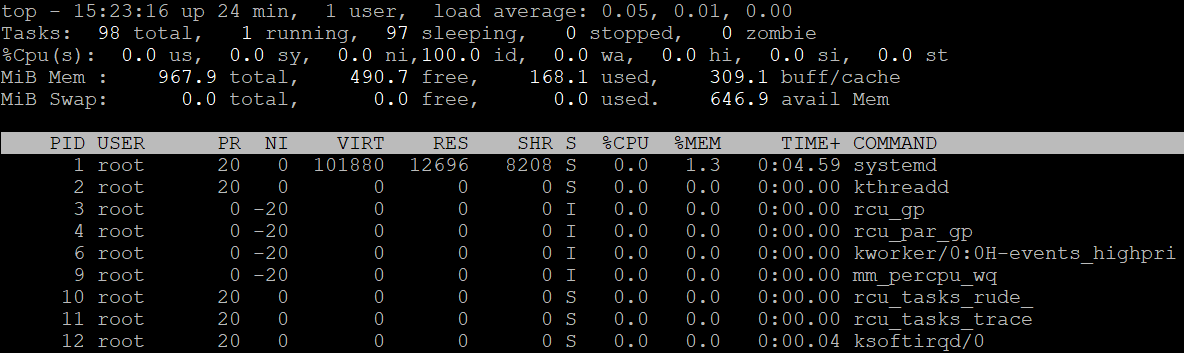
2. Lệnh top:top là một công cụ giám sát hệ thống theo thời gian thực, cung cấp một bức tranh toàn cảnh hơn. Gõ lệnh top trong terminal:
top
Giao diện của top sẽ hiện ra và tự động cập nhật. Dòng đầu tiên của top chính là thông tin tương tự như lệnh uptime, bao gồm cả Load Average.
top - 10:35:20 up 2 days, 15:50, 1 user, load average: 0.08, 0.09, 0.11
Ưu điểm của top là ngoài Load Average, nó còn liệt kê danh sách các tiến trình đang chạy, mức sử dụng CPU, bộ nhớ RAM của từng tiến trình. Điều này cực kỳ hữu ích khi bạn cần xác định tiến trình nào đang gây ra tải cao.
Giải thích tiến trình và hàng đợi CPU liên quan đến Load Average
Để hiểu sâu hơn về Load Average, chúng ta cần nắm rõ khái niệm về tiến trình và hàng đợi CPU (CPU queue hay run-queue).
- Tiến trình (Process): Là một chương trình đang được thực thi. Mỗi khi bạn chạy một ứng dụng hay một lệnh, hệ điều hành sẽ tạo ra một hoặc nhiều tiến trình.
- Hàng đợi CPU (Run-queue): Đây là danh sách các tiến trình đang ở trạng thái sẵn sàng (ready state) và đang chờ được CPU cấp phát thời gian để thực thi.
Load Average được tính toán dựa trên tổng số tiến trình đang thực sự chạy trên CPU cộng với số tiến trình đang chờ trong run-queue. Khi một tiến trình cần CPU, nó sẽ được đưa vào hàng đợi này. Hệ điều hành Linux sẽ sử dụng một bộ lập lịch (Kernel Linux) để quyết định tiến trình nào trong hàng đợi sẽ được chạy tiếp theo và chạy trong bao lâu.
Nếu số lượng tiến trình trong hàng đợi liên tục lớn hơn số lõi CPU, Load Average sẽ tăng cao. Điều này có nghĩa là “cung” (khả năng xử lý của CPU) không đủ đáp ứng “cầu” (nhu cầu xử lý từ các tiến trình). Hiểu được cơ chế này giúp bạn nhận ra rằng Load Average cao là một triệu chứng của việc hệ thống đang phải vật lộn để theo kịp khối lượng công việc được giao.

Các công cụ hỗ trợ giám sát Load Average
Ngoài uptime và top, có rất nhiều công cụ khác giúp bạn giám sát Load Average và hiệu suất hệ thống một cách trực quan và chi tiết hơn. Việc lựa chọn công cụ phù hợp sẽ giúp quá trình chẩn đoán sự cố trở nên nhanh chóng và hiệu quả.
Giới thiệu Glances và ưu điểm sử dụng
Glances là một công cụ giám sát hệ thống đa nền tảng được viết bằng Python. Nó được ví như một phiên bản nâng cấp mạnh mẽ của top và htop, cung cấp một lượng lớn thông tin chỉ trong một màn hình duy nhất.
Các tính năng chính của Glances:
- Hiển thị toàn diện: Glances hiển thị thông tin về CPU, Load Average, bộ nhớ, swap, mạng, I/O đĩa, cảm biến nhiệt độ và danh sách tiến trình.
- Mã màu thông minh: Tự động sử dụng màu sắc (xanh, lam, tím, đỏ) để cảnh báo về tình trạng hệ thống. Ví dụ, khi Load Average cao, nó sẽ chuyển sang màu đỏ để thu hút sự chú ý của bạn.
- Giao diện Web và API: Glances có thể chạy ở chế độ máy chủ web, cho phép bạn giám sát hệ thống từ xa thông qua trình duyệt.
- Xuất dữ liệu: Hỗ trợ xuất dữ liệu ra các định dạng như CSV, JSON để phân tích sau này.
So với các công cụ khác, htop mạnh về tương tác với tiến trình (kill, renice), trong khi vmstat và iostat cung cấp thông tin chi tiết về bộ nhớ ảo và I/O. Glances nổi bật nhờ khả năng tổng hợp tất cả thông tin đó vào một giao diện duy nhất, giúp bạn có cái nhìn tổng quan nhanh chóng mà không cần chuyển đổi giữa nhiều công cụ.
Cách sử dụng công cụ để theo dõi hiệu suất hệ thống tổng thể
Để bắt đầu với Glances, bạn cần cài đặt nó. Trên các hệ thống Debian/Ubuntu, bạn có thể dùng lệnh:
sudo apt-get update
sudo apt-get install glances
Sau khi cài đặt xong, chỉ cần chạy lệnh glances trong terminal:
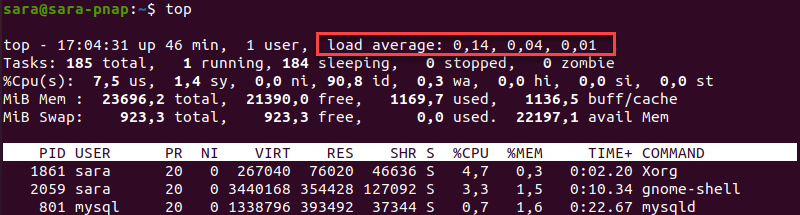
glances
Ngay lập tức, bạn sẽ thấy một bảng điều khiển chi tiết về hệ thống của mình. Hãy chú ý đến phần Load Average ở góc trên bên trái. Màu sắc của nó sẽ cho bạn biết ngay tình trạng tải hiện tại.
Một thực hành tốt là cấu hình cảnh báo. Glances cho phép bạn thiết lập các ngưỡng trong file cấu hình. Ví dụ, bạn có thể cấu hình để Glances gửi cảnh báo qua email hoặc Slack khi Load Average 15 phút vượt quá số lõi CPU của bạn. Việc này giúp bạn chủ động phát hiện sự cố ngay khi nó bắt đầu xảy ra, thay vì phải đợi đến khi người dùng phàn nàn về hiệu suất chậm. Bằng cách kết hợp các công cụ giám sát mạnh mẽ như Glances và thiết lập cảnh báo tự động, bạn có thể duy trì sự ổn định và hiệu suất cao cho hệ thống của mình.
Cách xử lý khi Load Average cao
Khi bạn phát hiện Load Average tăng cao bất thường, điều quan trọng là phải hành động một cách bình tĩnh và có phương pháp. Việc xác định đúng nguyên nhân sẽ giúp bạn đưa ra giải pháp khắc phục hiệu quả thay vì chỉ xử lý triệu chứng tạm thời.
Nguyên nhân phổ biến dẫn đến Load Average cao
Load Average cao có thể xuất phát từ nhiều nguyên nhân khác nhau. Dưới đây là những thủ phạm phổ biến nhất:
- Quá tải tiến trình (CPU-bound): Đây là nguyên nhân rõ ràng nhất. Một hoặc nhiều tiến trình đang tiêu thụ quá nhiều tài nguyên CPU, khiến các tiến trình khác phải xếp hàng chờ đợi. Các tác vụ như biên dịch phần mềm, xử lý video, truy vấn cơ sở dữ liệu phức tạp, hoặc các vòng lặp vô hạn trong mã nguồn thường gây ra tình trạng này.
- Thắt cổ chai I/O (I/O bottleneck): Như đã đề cập, hệ thống có thể bị quá tải do chờ đợi các hoạt động I/O. Nguyên nhân có thể là do ổ cứng (HDD) quá chậm, lỗi phần cứng ổ đĩa, truy vấn cơ sở dữ liệu không được tối ưu gây ra nhiều lần đọc/ghi, hoặc tốc độ mạng không đủ đáp ứng.
- Thiếu bộ nhớ (RAM): Khi hệ thống hết RAM vật lý, nó sẽ bắt đầu sử dụng một phần của ổ cứng làm bộ nhớ ảo (swap). Quá trình đọc/ghi từ swap chậm hơn rất nhiều so với RAM, gây ra tình trạng “trashing” (liên tục hoán đổi dữ liệu giữa RAM và swap), làm tăng đáng kể I/O và đẩy Load Average lên cao. Tham khảo bài DDR4 là gì để hiểu thêm về bộ nhớ RAM và các chuẩn mới giúp cải thiện hiệu suất.
- Lỗi ứng dụng hoặc cấu hình sai: Một ứng dụng bị lỗi, rò rỉ bộ nhớ, hoặc một dịch vụ được cấu hình sai (ví dụ: web server Apache/Nginx với quá nhiều worker process) cũng có thể là nguyên nhân gây ra tải cao.

Giải pháp và biện pháp khắc phục
- Xác định và xử lý tiến trình “nặng”:
- Sử dụng các lệnh như
top,htop, hoặcps aux --sort=-%cpu | headđể tìm ra các tiến trình đang chiếm nhiều CPU nhất. - Nếu đó là một tiến trình không quan trọng hoặc bị treo, bạn có thể “kill” nó bằng lệnh
kill <PID>. Hãy cẩn thận sử dụngkill -9(SIGKILL) vì nó sẽ buộc tiến trình dừng ngay lập tức mà không có cơ hội dọn dẹp. - Nếu tiến trình quan trọng nhưng đang chiếm quá nhiều tài nguyên, bạn có thể giảm độ ưu tiên của nó bằng lệnh
renice.
- Sử dụng các lệnh như
- Tối ưu hóa ứng dụng và hệ thống:
- Đối với CPU-bound: Tối ưu hóa mã nguồn, đặc biệt là các thuật toán và vòng lặp. Nếu không thể tối ưu hơn, hãy cân nhắc nâng cấp CPU hoặc mở rộng hệ thống theo chiều ngang (thêm máy chủ).
- Đối với I/O bottleneck: Tối ưu hóa các truy vấn cơ sở dữ liệu, sử dụng caching để giảm số lần đọc/ghi. Nâng cấp từ HDD lên SSD là một giải pháp cực kỳ hiệu quả. Bạn có thể tham khảo thêm bài viết Cài đặt Ubuntu để biết cách sử dụng hệ điều hành Linux tối ưu cấu hình phần cứng.
- Đối với thiếu RAM: Tối ưu hóa ứng dụng để sử dụng ít bộ nhớ hơn, hoặc đơn giản là nâng cấp thêm RAM.
- Sử dụng script tự động kiểm soát:
- Bạn có thể viết các kịch bản (script) và sử dụng
cronđể chạy chúng định kỳ. Các script này có thể kiểm tra Load Average, và nếu nó vượt ngưỡng cho phép, script có thể tự động gửi cảnh báo cho bạn hoặc thực hiện một số hành động khắc phục cơ bản như khởi động lại một dịch vụ bị lỗi.
- Bạn có thể viết các kịch bản (script) và sử dụng
Việc xử lý Load Average cao đòi hỏi sự kết hợp giữa kỹ năng chẩn đoán và kiến thức về hệ thống. Bắt đầu bằng việc xác định nguyên nhân gốc rễ là bước quan trọng nhất để đảm bảo hệ thống hoạt động ổn định lâu dài.
Thường gặp và cách khắc phục sự cố liên quan đến Load Average
Trong quá trình quản trị hệ thống, bạn sẽ gặp phải một số kịch bản phổ biến liên quan đến Load Average. Việc nhận biết và có sẵn phương án xử lý nhanh sẽ giúp bạn giảm thiểu thời gian hệ thống ngừng hoạt động.
Load Average cao nhưng CPU không đầy
Đây là một trong những tình huống gây bối rối nhất. Bạn thấy hệ thống chậm chạp, Load Average 15 phút có thể lên đến 10, 20 hoặc cao hơn, nhưng khi kiểm tra bằng top, tổng %CPU Usage lại rất thấp, chỉ khoảng 5-10%.
- Nguyên nhân: Như đã phân tích, đây là dấu hiệu rõ ràng của I/O bottleneck. Các tiến trình đang bị kẹt trong trạng thái “uninterruptible sleep” (thường được ký hiệu là ‘D’ trong
tophoặcps). Chúng không dùng CPU, nhưng chúng đang chờ một thứ gì đó – thường là phản hồi từ ổ đĩa, hệ thống mạng, hoặc các thiết bị phần cứng khác. - Cách khắc phục:
- Kiểm tra I/O đĩa: Sử dụng các công cụ như
iotophoặciostatđể xem tiến trình nào đang thực hiện nhiều hoạt động đọc/ghi đĩa nhất.sudo apt-get install iotop sudo iotop - Kiểm tra bộ nhớ: Dùng lệnh
free -hđể xem hệ thống có đang sử dụng nhiều swap không. Nếu swap đang được sử dụng nhiều, đó là dấu hiệu của việc thiếu RAM. - Phân tích ứng dụng: Nếu nghi ngờ cơ sở dữ liệu là nguyên nhân, hãy kiểm tra các truy vấn chậm (slow queries). Đối với máy chủ web, hãy kiểm tra log để tìm các yêu cầu mất nhiều thời gian xử lý.
- Kiểm tra phần cứng: Trong trường hợp xấu nhất, ổ đĩa có thể đang gặp sự cố. Sử dụng các công cụ như
smartctlđể kiểm tra sức khỏe của ổ đĩa.
- Kiểm tra I/O đĩa: Sử dụng các công cụ như
Load Average tăng đột ngột và cách xử lý nhanh
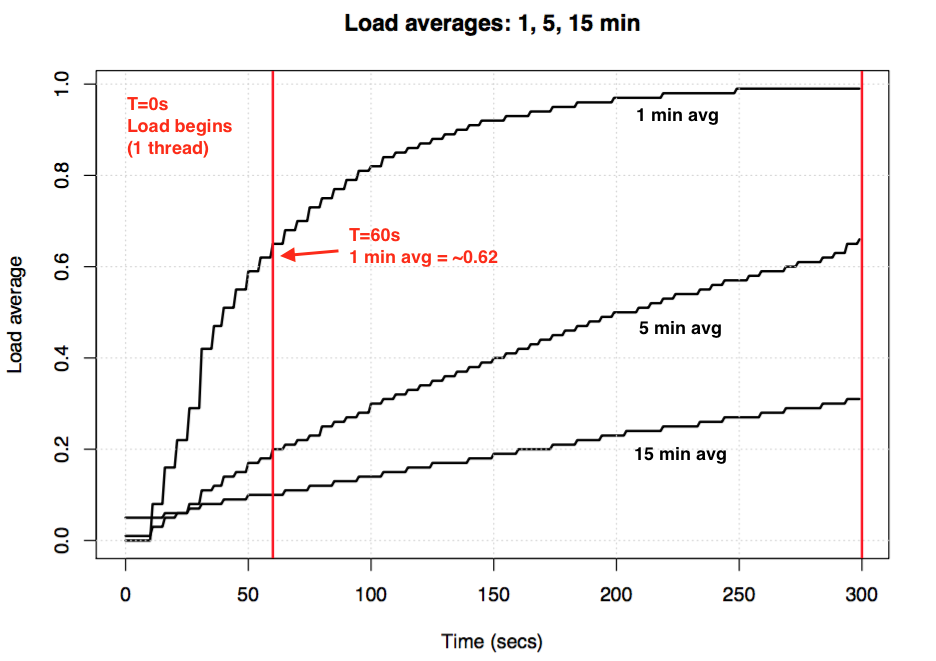
Đôi khi, hệ thống đang hoạt động ổn định với Load Average thấp bỗng nhiên tăng vọt trong một khoảng thời gian ngắn (chỉ số 1 phút rất cao, nhưng 5 và 15 phút vẫn thấp).
- Nguyên nhân: Thường là do một tác vụ nặng đột xuất được thực thi, chẳng hạn như một cron job chạy vào giờ cao điểm, một cuộc tấn công từ chối dịch vụ (DDoS) nhỏ, hoặc một người dùng thực thi một script tính toán phức tạp.
- Cách xử lý nhanh:
- Hành động ngay lập tức: Dùng
htophoặctopvà sắp xếp theo %CPU (nhấn phímPtrongtop). Tiến trình gây ra sự đột biến thường sẽ nằm ở trên cùng. - Phân tích nhanh: Xem tên tiến trình và người dùng sở hữu nó. Nó có phải là một tiến trình hệ thống quen thuộc không? Nó đã chạy bao lâu rồi?
- Quyết định xử lý:
- Nếu đó là một script của người dùng chạy sai, hãy liên hệ với họ hoặc
killtiến trình nếu cần thiết. - Nếu đó là một cron job, hãy xem xét lại lịch trình của nó để chuyển sang giờ thấp điểm.
- Nếu không xác định được, hãy ghi lại thông tin về tiến trình (PID, command) để phân tích sau.
- Nếu đó là một script của người dùng chạy sai, hãy liên hệ với họ hoặc
- Theo dõi: Sau khi xử lý, tiếp tục theo dõi Load Average (đặc biệt là chỉ số 1 phút và 5 phút) để đảm bảo nó giảm xuống và hệ thống trở lại trạng thái ổn định.
- Hành động ngay lập tức: Dùng
Các best practices trong giám sát và quản lý Load Average
Quản lý Load Average không chỉ là việc phản ứng khi có sự cố, mà còn là một quá trình chủ động và liên tục để đảm bảo hiệu suất hệ thống. Áp dụng các phương pháp tốt nhất sau đây sẽ giúp bạn duy trì một hệ thống khỏe mạnh và ổn định.
- Theo dõi liên tục bằng các công cụ phù hợp: Đừng đợi đến khi có vấn đề mới kiểm tra. Hãy thiết lập một hệ thống giám sát tự động. Các công cụ như Zabbix, Nagios, Prometheus kết hợp với Grafana có thể thu thập dữ liệu Load Average theo thời gian, vẽ biểu đồ và gửi cảnh báo khi các chỉ số vượt ngưỡng bạn đã định. Điều này giúp bạn phát hiện các xu hướng bất thường trước khi chúng trở thành sự cố nghiêm trọng.
- Không dựa hoàn toàn vào Load Average: Load Average là một chỉ số tuyệt vời nhưng nó không kể toàn bộ câu chuyện. Một quản trị viên hệ thống giỏi sẽ xem xét nó trong mối tương quan với các chỉ số khác. Hãy luôn kết hợp kiểm tra %CPU, mức sử dụng RAM và Swap, hoạt động I/O đĩa, và lưu lượng mạng. Một cái nhìn toàn diện sẽ giúp bạn chẩn đoán chính xác nguyên nhân gốc rễ của vấn đề. Tham khảo thêm khái niệm Kernel là gì để hiểu nền tảng xử lý yêu cầu trong hệ điều hành Linux.
- Lên kế hoạch bảo trì và nâng cấp hệ thống định kỳ: Hệ thống của bạn cần được chăm sóc. Hãy lên lịch bảo trì định kỳ để cập nhật phần mềm, kiểm tra log, và dọn dẹp các file không cần thiết. Đồng thời, dựa trên dữ liệu giám sát, hãy lên kế hoạch nâng cấp phần cứng (CPU, RAM, SSD) trước khi hệ thống đạt đến giới hạn của nó. Việc chủ động nâng cấp sẽ tốt hơn nhiều so với việc phải xử lý sự cố trong tình trạng khẩn cấp.
- Tránh quá tải bằng cách phân phối tiến trình đều: Nếu bạn có các tác vụ nặng cần thực thi định kỳ (cron jobs), hãy sắp xếp chúng vào những thời điểm ít tải nhất, chẳng hạn như vào ban đêm. Đối với các ứng dụng web có lưu lượng truy cập cao, hãy xem xét sử dụng bộ cân bằng tải (Load Balancer) để phân phối yêu cầu trên nhiều máy chủ, tránh tình trạng một máy chủ duy nhất bị quá tải.
Bằng cách áp dụng những phương pháp này, bạn sẽ chuyển từ vai trò “chữa cháy” sang một kiến trúc sư hệ thống chủ động, xây dựng và duy trì một nền tảng vững chắc cho các ứng dụng của mình.

Kết luận
Qua bài viết này, chúng ta đã cùng nhau giải mã chỉ số Load Average trong Linux – một khái niệm tưởng chừng phức tạp nhưng lại vô cùng quan trọng. Giờ đây, bạn không chỉ hiểu Load Average là gì, mà còn biết cách đọc ba con số biểu thị tải trung bình trong 1, 5 và 15 phút. Quan trọng hơn, bạn đã có thể phân biệt rõ ràng sự khác biệt cốt lõi giữa Load Average (đo lường nhu cầu) và %CPU (đo lường mức độ sử dụng), giúp việc chẩn đoán sự cố trở nên chính xác hơn bao giờ hết.
Việc giám sát và xử lý kịp thời khi Load Average tăng cao là chìa khóa để duy trì một hệ thống ổn định và hiệu suất. Bỏ qua chỉ số này có thể dẫn đến tình trạng máy chủ chậm chạp, ảnh hưởng trực tiếp đến trải nghiệm người dùng và hoạt động kinh doanh. Hãy nhớ rằng, một hệ thống khỏe mạnh là nền tảng cho mọi dịch vụ số, từ website giới thiệu công ty đến các ứng dụng web phức tạp.
AZWEB khuyến khích bạn hãy bắt đầu áp dụng ngay những kiến thức và công cụ đã học, như uptime, top, glances, để theo dõi máy chủ của mình. Đừng ngần ngại tìm hiểu sâu hơn về cách tối ưu hóa Linux là gì server. Việc làm chủ các kỹ năng quản trị hệ thống sẽ giúp bạn tự tin vận hành và phát triển các dự án trên nền tảng Linux một cách hiệu quả và bền vững.