Bạn đã từng muốn khám phá nội dung văn bản ẩn trong các file nhị phân trên Linux chưa? Đôi khi, những thông tin quan trọng như thông báo lỗi, chuỗi cấu hình hay thậm chí là các đoạn mã độc hại lại được cất giấu bên trong các tệp thực thi mà không thể đọc bằng các trình soạn thảo văn bản thông thường. Việc trích xuất chuỗi ký tự trong file nhị phân thường gặp khó khăn do định dạng phức tạp và không rõ ràng. Đây chính là lúc lệnh strings trên Linux phát huy sức mạnh. Nó là một công cụ đơn giản nhưng cực kỳ hữu ích, giúp bạn tìm và hiển thị các chuỗi văn bản ASCII hoặc Unicode trong file nhị phân một cách nhanh chóng. Bài viết này sẽ hướng dẫn bạn từ A đến Z về lệnh strings, từ cách cài đặt, sử dụng các tùy chọn nâng cao, cho đến những ứng dụng thực tế trong quản trị hệ thống và phát triển phần mềm.
Giới thiệu và mục đích sử dụng lệnh strings
Lệnh strings là gì?
Lệnh strings là một tiện ích dòng lệnh trong các hệ điều hành Unix-like, bao gồm cả Linux là gì. Chức năng cơ bản và cốt lõi của nó là quét qua một tệp tin, đặc biệt là tệp nhị phân, và trích xuất ra các chuỗi ký tự có thể đọc được (printable characters). Theo mặc định, nó sẽ tìm kiếm các chuỗi có ít nhất 4 ký tự liên tiếp và hiển thị chúng trên đầu ra chuẩn.

Điểm khác biệt chính của strings so với các công cụ khác là mục tiêu của nó. Trong khi grep được thiết kế để tìm kiếm các mẫu (pattern) cụ thể trong các tệp văn bản, strings lại được tạo ra để “nhìn trộm” vào bên trong các tệp không phải văn bản. Mặt khác, hexdump hoặc xxd hiển thị toàn bộ nội dung của tệp dưới dạng mã thập lục phân (hex), hữu ích cho việc phân tích sâu ở cấp độ byte, nhưng lại khó đọc hơn nếu bạn chỉ muốn tìm các đoạn văn bản. strings lấp đầy khoảng trống đó bằng cách chỉ lọc ra những gì con người có thể đọc được.
Mục đích sử dụng phổ biến
Lệnh strings có rất nhiều ứng dụng thực tế, đặc biệt hữu ích cho các nhà phát triển phần mềm, quản trị viên hệ thống và các nhà phân tích bảo mật. Một trong những mục đích phổ biến nhất là kiểm tra nhanh nội dung của một file nhị phân không rõ nguồn gốc. Ví dụ, khi bạn tải về một tệp thực thi, bạn có thể dùng strings để xem qua các chuỗi văn bản bên trong nó, giúp phán đoán chức năng hoặc nguồn gốc của tệp.
Trong lĩnh vực an ninh mạng, strings là một công cụ không thể thiếu trong giai đoạn phân tích malware ban đầu. Các nhà phân tích thường sử dụng nó để tìm kiếm các chuỗi đáng ngờ như địa chỉ IP, tên miền, các lệnh hệ thống, hoặc các thông báo lạ được nhúng trong mã độc. Những thông tin này cung cấp manh mối quan trọng về hành vi và cơ chế hoạt động của phần mềm độc hại. Ngoài ra, các nhà phát triển phần mềm cũng thường dùng strings để debug. Khi một chương trình gặp sự cố mà không có mã nguồn, việc tìm kiếm các chuỗi thông báo lỗi được nhúng sẵn có thể giúp xác định nguyên nhân gây ra vấn đề.
Cách cài đặt và chạy lệnh strings trên Linux
Cách kiểm tra và cài đặt strings
Trên hầu hết các bản phân phối Linux hiện đại, lệnh strings đã được cài đặt sẵn như một phần của gói công cụ binutils. Gói này chứa một bộ sưu tập các công cụ lập trình nhị phân cần thiết cho hệ thống. Để kiểm tra xem strings đã có trên hệ thống của bạn hay chưa, bạn có thể mở terminal và chạy một trong hai lệnh sau. Lệnh which strings sẽ cho bạn biết đường dẫn đến tệp thực thi của lệnh.
which strings
Nếu lệnh tồn tại, bạn sẽ thấy kết quả như /usr/bin/strings. Một cách khác là kiểm tra phiên bản bằng lệnh strings --version. Nếu lệnh không được tìm thấy, bạn cần phải cài đặt gói binutils. Quá trình cài đặt rất đơn giản. Trên các hệ thống dựa trên Debian hoặc Ubuntu, bạn sử dụng lệnh:
sudo apt update && sudo apt install binutils
Đối với các hệ thống dựa trên CentOS, Fedora hoặc RHEL, bạn dùng lệnh sau:
sudo yum install binutils
Sau khi cài đặt thành công, bạn có thể kiểm tra lại bằng lệnh which strings để chắc chắn mọi thứ đã sẵn sàng.
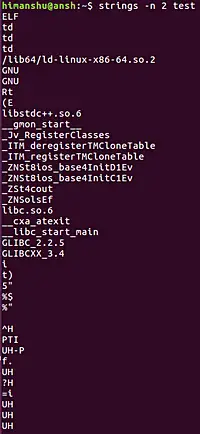
Cách chạy lệnh strings cơ bản
Cú pháp cơ bản để sử dụng lệnh strings rất đơn giản và dễ nhớ, giúp bạn nhanh chóng áp dụng vào công việc. Bạn chỉ cần gõ tên lệnh, theo sau là các tùy chọn (nếu có) và cuối cùng là tên của tệp tin bạn muốn phân tích.
Cú pháp chung: strings [tùy chọn] ten_file
Để bắt đầu, hãy thử chạy lệnh ở dạng đơn giản nhất mà không cần bất kỳ tùy chọn nào. Ví dụ, nếu bạn muốn xem các chuỗi ký tự có trong tệp thực thi của lệnh bash, bạn có thể chạy:
strings /bin/bash
Lệnh này sẽ quét toàn bộ tệp /bin/bash và in ra màn hình tất cả các chuỗi ký tự có thể đọc được với độ dài tối thiểu là 4. Kết quả đầu ra sẽ là một danh sách dài các chuỗi, mỗi chuỗi trên một dòng. Bạn có thể sẽ thấy các thông báo lỗi, tên biến, tên hàm, và nhiều văn bản khác được các nhà phát triển nhúng vào chương trình. Để dễ dàng xem các kết quả dài, bạn có thể kết hợp với lệnh less: strings /bin/bash | less. Điều này cho phép bạn cuộn lên xuống để xem toàn bộ kết quả một cách thuận tiện.
Hướng dẫn trích xuất chuỗi ký tự ASCII và Unicode
Trích xuất chuỗi ASCII
Chuỗi ASCII (American Standard Code for Information Interchange) là một bộ mã ký tự dựa trên bảng chữ cái tiếng Anh, bao gồm các chữ cái, chữ số, và các ký tự điều khiển phổ biến. Đây là định dạng mã hóa văn bản cơ bản và phổ biến nhất. Khi bạn chạy lệnh strings mà không có tùy chọn đặc biệt nào, nó sẽ mặc định tìm kiếm và trích xuất các chuỗi ký tự được mã hóa theo chuẩn ASCII.
Theo mặc định, strings sẽ xác định một chuỗi là một chuỗi liên tiếp gồm ít nhất 4 ký tự có thể in được (printable characters) và kết thúc bằng một ký tự không in được (non-printable character) hoặc ký tự null. Đây là một thiết lập hợp lý để lọc bỏ các “chuỗi” ngẫu nhiên xuất hiện trong dữ liệu nhị phân. Ví dụ, khi bạn chạy lệnh trên một tệp thư viện chia sẻ như libc.so.6:
strings /lib/x86_64-linux-gnu/libc.so.6 | less
Bạn sẽ thấy một loạt các chuỗi văn bản, bao gồm thông báo lỗi (“invalid pointer”), tên hàm, và các chuỗi định dạng cho hàm printf. Đây là những thông tin vô cùng hữu ích khi bạn đang cố gắng tìm hiểu cách một chương trình hoạt động hoặc tại sao nó lại gặp sự cố.

Trích xuất chuỗi Unicode
Trong khi ASCII là đủ cho văn bản tiếng Anh cơ bản, thế giới kỹ thuật số hiện đại cần một tiêu chuẩn mạnh mẽ hơn để hỗ trợ nhiều ngôn ngữ và biểu tượng khác nhau. Đó là lý do Unicode ra đời. Unicode sử dụng nhiều hơn một byte để biểu diễn một ký tự, cho phép nó mã hóa hầu hết các hệ thống chữ viết trên thế giới. Do đó, rất nhiều chương trình hiện đại lưu trữ chuỗi văn bản dưới dạng Unicode thay vì ASCII.
Lệnh strings cũng có khả năng xử lý các chuỗi Unicode này, nhưng bạn cần chỉ định rõ loại mã hóa. Unicode có hai dạng chính là Little Endian và Big Endian, liên quan đến thứ tự các byte được lưu trữ. Bạn có thể sử dụng tùy chọn -e (encoding) để chỉ định định dạng:
-e l: Trích xuất chuỗi Unicode 16-bit Little Endian.-e b: Trích xuất chuỗi Unicode 16-bit Big Endian.
Ví dụ, để tìm các chuỗi Unicode Little Endian trong một tệp, bạn có thể sử dụng lệnh sau:
strings -e l ten_file.bin
Việc biết khi nào nên sử dụng tùy chọn này là rất quan trọng. Nếu bạn chạy strings mặc định trên một tệp chứa nhiều văn bản Unicode và không thấy kết quả mong muốn, hãy thử lại với tùy chọn -e l hoặc -e b. Điều này đặc biệt hữu ích khi phân tích các tệp thực thi của Windows hoặc các ứng dụng đa ngôn ngữ.
Các tùy chọn phổ biến và cách áp dụng
Tùy chọn thường dùng
Lệnh strings trở nên mạnh mẽ hơn rất nhiều khi bạn kết hợp với các tùy chọn của nó. Việc hiểu và sử dụng thành thạo các tùy chọn này sẽ giúp bạn lọc kết quả chính xác hơn và thu được thông tin hữu ích một cách hiệu quả. Dưới đây là ba trong số các tùy chọn được sử dụng thường xuyên nhất.
Tùy chọn -n <số> hoặc --bytes=<số>: Tùy chọn này cho phép bạn thay đổi độ dài tối thiểu của chuỗi ký tự mà strings sẽ tìm kiếm. Mặc định là 4, nhưng đôi khi giá trị này tạo ra quá nhiều kết quả nhiễu. Bằng cách tăng giá trị này, ví dụ -n 8, bạn có thể lọc bỏ các chuỗi ngắn, không liên quan và chỉ tập trung vào các chuỗi dài hơn, có ý nghĩa hơn.
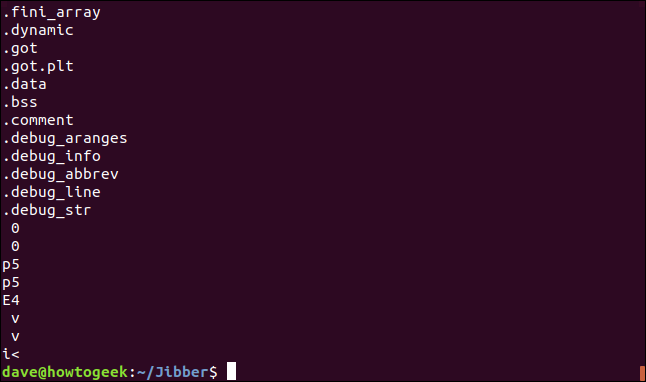
Tùy chọn -t <định_dạng> hoặc --radix=<định_dạng>: Tùy chọn này rất hữu ích cho việc phân tích sâu. Nó sẽ hiển thị vị trí (offset) của mỗi chuỗi được tìm thấy ở đầu dòng. Bạn có thể chọn định dạng cho offset:
d: Thập phân (decimal)o: Bát phân (octal)x: Thập lục phân (hexadecimal)
Định dạng x (hex) là phổ biến nhất, vì nó cho phép bạn dễ dàng tìm đến vị trí chính xác của chuỗi trong tệp bằng một trình soạn thảo hex.
Tùy chọn -e <mã_hóa> hoặc --encoding=<mã_hóa>: Như đã đề cập ở phần trước, tùy chọn này dùng để chỉ định bảng mã ký tự cần tìm kiếm. Ngoài l (16-bit little-endian) và b (16-bit big-endian), nó còn hỗ trợ các định dạng khác như S (ASCII 7-bit) hay L (32-bit little-endian).
Áp dụng tùy chọn trong tình huống thực tế
Hãy xem cách chúng ta có thể kết hợp các tùy chọn này để giải quyết các vấn đề thực tế. Giả sử bạn đang phân tích một tệp nhị phân lớn và đầu ra của lệnh strings cơ bản quá dài và lộn xộn. Để giảm nhiễu, bạn quyết định chỉ muốn xem các chuỗi có độ dài ít nhất 10 ký tự. Bạn có thể sử dụng lệnh:
strings -n 10 file_lon.bin | less
Kết quả bây giờ sẽ gọn gàng hơn nhiều, giúp bạn tập trung vào những thông tin quan trọng.
Bây giờ, hãy tưởng tượng bạn tìm thấy một chuỗi đáng ngờ, ví dụ như một mật khẩu hoặc một khóa API, và bạn muốn biết nó nằm ở đâu trong tệp để có thể phân tích sâu hơn. Đây là lúc tùy chọn -t phát huy tác dụng. Bằng cách chạy lệnh sau:
strings -n 10 -t x file_lon.bin | grep "API_KEY"
Đầu ra sẽ không chỉ hiển thị chuỗi chứa “API_KEY” mà còn cả địa chỉ offset dưới dạng hex ở đầu dòng, ví dụ: 1a2b3c API_KEY=.... Với thông tin offset này, bạn có thể sử dụng các công cụ như hexdump, xxd, hoặc một trình soạn thảo hex chuyên dụng để kiểm tra các byte xung quanh chuỗi đó, giúp bạn hiểu rõ hơn về ngữ cảnh và cách nó được sử dụng trong chương trình.
Ví dụ minh họa trong phân tích và kiểm tra dữ liệu tập tin
Ví dụ 1: Phân tích file thực thi để tìm chuỗi lỗi hoặc thông báo
Một trong những ứng dụng trực tiếp và hữu ích nhất của lệnh strings là phân tích các tệp thực thi. Các nhà phát triển thường nhúng các chuỗi thông báo lỗi, thông điệp hướng dẫn sử dụng, hoặc các chuỗi debug trực tiếp vào mã nguồn. Khi chương trình được biên dịch, các chuỗi này vẫn còn tồn tại trong tệp nhị phân cuối cùng.
Giả sử bạn có một chương trình tên là app và nó thường xuyên bị lỗi mà không hiển thị thông báo rõ ràng. Bạn có thể dùng strings để tìm kiếm tất cả các thông điệp có thể có bên trong nó. Một cách tiếp cận hiệu quả là kết hợp strings với grep để lọc các từ khóa liên quan đến lỗi như “error”, “failed”, “warning”, hoặc “invalid”.
strings ./app | grep -i "error"
Lệnh -i trong grep giúp tìm kiếm không phân biệt chữ hoa, chữ thường, tăng khả năng tìm thấy kết quả. Kết quả có thể cho bạn thấy các chuỗi như “Error: Failed to open configuration file” hay “Invalid input detected”. Những thông báo này, dù không xuất hiện khi chương trình chạy, vẫn cung cấp manh mối quý giá để bạn chẩn đoán và khắc phục sự cố. Đây là một kỹ thuật debug cơ bản nhưng cực kỳ hiệu quả, đặc biệt khi bạn không có quyền truy cập vào mã nguồn của chương trình.
Ví dụ 2: Kiểm tra file cấu hình nhúng hoặc file log nhị phân
Không phải tất cả các tệp cấu hình hay tệp log đều ở định dạng văn bản thuần túy. Một số ứng dụng sử dụng định dạng nhị phân để lưu trữ cấu hình nhằm tăng tốc độ đọc ghi hoặc để che giấu thông tin. Tương tự, các tệp log hiệu suất cao đôi khi cũng được ghi dưới dạng nhị phân. Lệnh strings là công cụ lý tưởng để kiểm tra nhanh nội dung của các tệp này.
Ví dụ, bạn đang quản trị một hệ thống và nghi ngờ một tệp config.dat chứa các thông tin quan trọng. Thay vì phải tìm một công cụ chuyên dụng để đọc nó, bạn có thể bắt đầu bằng lệnh strings:
strings config.dat
Bạn có thể sẽ khám phá ra các cặp khóa-giá trị như DB_HOST=192.168.1.100 hay LICENSE_KEY=.... Tương tự, khi phân tích một tệp log nhị phân, strings có thể giúp bạn trích xuất các thông điệp nhật ký có thể đọc được, giúp bạn hiểu được các sự kiện đã xảy ra mà không cần phải phân tích toàn bộ cấu trúc tệp phức tạp. Việc này giúp tiết kiệm thời gian và cung cấp một cái nhìn tổng quan nhanh chóng về nội dung của các tệp không phải văn bản.
Ứng dụng thực tế của lệnh strings trong quản trị hệ thống và phát triển phần mềm
Lệnh strings không chỉ là một công cụ lý thuyết mà còn có nhiều ứng dụng thực tiễn giá trị trong công việc hàng ngày của các chuyên gia công nghệ. Trong lĩnh vực quản trị hệ thống, nó là một trợ thủ đắc lực trong việc duy trì an ninh và sự ổn định của hệ thống. Khi phát hiện một tệp tin lạ hoặc đáng ngờ trên máy chủ, quản trị viên có thể nhanh chóng dùng strings để kiểm tra. Việc tìm thấy các chuỗi ký tự lạ, các địa chỉ IP từ nước ngoài, hoặc các lệnh hệ thống đáng ngờ có thể là dấu hiệu đầu tiên của một cuộc tấn công hoặc sự hiện diện của malware.
Đối với các nhà phát triển phần mềm, strings là một công cụ gỡ lỗi (debug) linh hoạt. Khi một ứng dụng gặp sự cố trên môi trường sản phẩm (production) và không thể tái tạo lỗi trong môi trường phát triển, việc phân tích tệp nhị phân hoặc tệp core dump bằng strings có thể hé lộ thông báo lỗi cuối cùng trước khi chương trình sập. Điều này giúp khoanh vùng nguyên nhân sự cố nhanh hơn. Hơn nữa, trước khi phát hành một phần mềm, các nhà phát triển có thể sử dụng strings để kiểm tra lại tệp nhị phân, đảm bảo rằng không có thông tin nhạy cảm nào như mật khẩu, khóa API, hoặc các đường dẫn tệp cục bộ bị vô tình nhúng vào sản phẩm cuối cùng. Đây là một bước kiểm tra bảo mật quan trọng trong quy trình phát triển phần mềm an toàn.
Các vấn đề thường gặp và cách khắc phục
Lỗi không tìm thấy lệnh strings
Một trong những vấn đề phổ biến nhất mà người dùng mới có thể gặp phải là lỗi “command not found” khi cố gắng chạy lệnh strings. Lỗi này hầu như luôn luôn có nghĩa là gói phần mềm chứa lệnh này chưa được cài đặt trên hệ thống của bạn. Lệnh strings là một phần của bộ công cụ GNU Binutils, một tập hợp các công cụ lập trình cần thiết.
Nguyên nhân có thể là bạn đang làm việc trên một hệ thống được cài đặt tối giản, chẳng hạn như một container Docker hoặc một máy chủ cloud, nơi các gói không thiết yếu đã được lược bỏ để tiết kiệm dung lượng. Cách khắc phục rất đơn giản: bạn chỉ cần cài đặt gói binutils bằng trình quản lý gói của bản phân phối Linux bạn đang sử dụng.
- Trên Ubuntu/Debian:
sudo apt-get install binutils - Trên CentOS/Fedora/RHEL:
sudo yum install binutils
Sau khi quá trình cài đặt hoàn tất, shell sẽ có thể tìm thấy lệnh strings trong đường dẫn hệ thống và bạn có thể bắt đầu sử dụng nó ngay lập tức.
Kết quả đầu ra quá dài, nhiều chuỗi không liên quan
Một vấn đề khác không phải là lỗi mà là một thách thức về hiệu quả: kết quả đầu ra của strings có thể quá lớn và chứa đầy “nhiễu”. Điều này xảy ra khi phân tích các tệp nhị phân lớn, vì bất kỳ chuỗi 4 ký tự nào cũng sẽ được hiển thị, bao gồm cả những chuỗi vô nghĩa được hình thành ngẫu nhiên từ dữ liệu nhị phân.
Để giải quyết vấn đề này, có hai giải pháp chính. Đầu tiên, hãy sử dụng tùy chọn -n để tăng độ dài chuỗi tối thiểu. Đặt giá trị này thành 6, 8, hoặc thậm chí cao hơn sẽ giúp loại bỏ phần lớn các chuỗi ngắn, không liên quan.
strings -n 8 ten_file.bin
Thứ hai, hãy kết hợp strings với các công cụ lọc văn bản mạnh mẽ khác của Linux. Bạn có thể chuyển đầu ra của strings vào lệnh grep để chỉ hiển thị các dòng chứa một từ khóa cụ thể. Hoặc, bạn có thể chuyển nó vào less để xem kết quả theo từng trang, cho phép bạn tìm kiếm và điều hướng dễ dàng hơn.
strings ten_file.bin | grep "password"strings ten_file.bin | less
Sử dụng kết hợp các kỹ thuật này sẽ giúp bạn biến một lượng lớn dữ liệu lộn xộn thành thông tin hữu ích và có thể hành động.
Những lưu ý và thực hành tốt nhất khi dùng strings
Để khai thác tối đa sức mạnh của lệnh strings và tránh những kết quả sai lệch, có một vài lưu ý và thực hành tốt nhất mà bạn nên tuân thủ. Đầu tiên và quan trọng nhất, hãy luôn cân nhắc về mã hóa (encoding) của chuỗi ký tự. Nếu bạn đang làm việc với các tệp có khả năng chứa văn bản đa ngôn ngữ hoặc được tạo ra trên hệ thống Windows, đừng quên thử tùy chọn -e với l hoặc b để tìm kiếm chuỗi Unicode. Việc bỏ qua bước này có thể khiến bạn bỏ lỡ những thông tin quan trọng.
Thứ hai, hãy lọc kết quả một cách thông minh. Sử dụng tùy chọn -n để đặt độ dài chuỗi tối thiểu một cách hợp lý là một thói quen tốt. Điều này không chỉ giúp giảm nhiễu mà còn tăng tốc độ phân tích của bạn. Đừng ngần ngại kết hợp strings với các công cụ khác như grep, sort, và uniq thông qua cơ chế pipe (|). Ví dụ, strings file.bin | sort | uniq -c có thể giúp bạn đếm số lần xuất hiện của mỗi chuỗi, một kỹ thuật hữu ích trong phân tích tần suất.
Cuối cùng, hãy nhớ rằng strings là công cụ dành cho tệp nhị phân. Mặc dù nó có thể chạy trên các tệp văn bản, nhưng nó không hiệu quả bằng các công cụ được thiết kế riêng cho mục đích đó như cat, less, hoặc grep. Sử dụng đúng công cụ cho đúng công việc sẽ giúp quy trình làm việc của bạn trở nên hiệu quả và chính xác hơn.
Kết luận
Lệnh strings trên Linux là một minh chứng hoàn hảo cho triết lý của Unix: tạo ra những công cụ đơn giản, thực hiện một việc và thực hiện nó thật tốt. Mặc dù có vẻ khiêm tốn, strings lại là một tiện ích cực kỳ mạnh mẽ, mở ra một cánh cửa để nhìn vào bên trong các tệp nhị phân vốn dĩ khó hiểu. Từ việc kiểm tra nhanh một tệp tải về, debug một ứng dụng phức tạp, cho đến các bước đầu tiên trong phân tích phần mềm độc hại, lợi ích mà nó mang lại là không thể phủ nhận. Nó giúp biến dữ liệu máy móc thành thông tin mà con người có thể đọc và hiểu được.
Bằng cách nắm vững cách sử dụng lệnh này cùng các tùy chọn phổ biến như -n, -t, và -e, bạn đã trang bị cho mình một kỹ năng quan trọng trong bộ công cụ của một quản trị viên hệ thống, nhà phát triển phần mềm hay chuyên gia bảo mật. AZWEB khuyến khích bạn không chỉ đọc mà hãy mở ngay cửa sổ terminal và thực hành lệnh strings trên các tệp tin thực tế. Hãy bắt đầu với các tệp thực thi trong thư mục /bin của bạn và xem bạn có thể khám phá ra những gì. Việc thực hành thường xuyên sẽ giúp bạn nhanh chóng thành thạo và áp dụng công cụ này một cách hiệu quả trong công việc hàng ngày.