Trong thế giới quản trị hệ thống Linux, việc xử lý và tìm kiếm thông tin trong các tập tin văn bản là một kỹ năng không thể thiếu. Các lệnh tìm kiếm như grep, sed, hay awk đã trở thành công cụ quen thuộc của mọi quản trị viên. Tuy nhiên, nhiều người dùng, đặc biệt là những người mới bắt đầu, thường cảm thấy bối rối trước sự đa dạng của các lệnh này, đặc biệt là khi gặp phải lệnh egrep. Họ không rõ egrep khác gì so với grep và khi nào nên sử dụng nó để đạt hiệu quả cao nhất. Bài viết này của AZWEB sẽ là kim chỉ nam giúp bạn làm chủ lệnh egrep một cách toàn diện. Chúng tôi sẽ đi từ cú pháp cơ bản, các ví dụ thực tiễn, so sánh với các lệnh tương tự và chia sẻ những mẹo hữu ích để bạn có thể áp dụng ngay vào công việc hàng ngày của mình, biến việc tìm kiếm dữ liệu phức tạp trở nên đơn giản và nhanh chóng.
Giới thiệu về lệnh egrep trong Linux
Đối với bất kỳ ai làm việc trong môi trường Linux là gì, từ quản trị viên hệ thống đến các nhà phát triển phần mềm, khả năng tìm kiếm và lọc dữ liệu trong các tệp văn bản là một kỹ năng nền tảng. Các tập tin log, tệp cấu hình hay mã nguồn đều chứa đựng những thông tin quan trọng, và việc trích xuất chúng một cách nhanh chóng quyết định hiệu suất công việc. Đây chính là lúc các lệnh tìm kiếm như grep, fgrep, và đặc biệt là egrep phát huy vai trò của mình.
Tuy nhiên, vấn đề phổ biến mà nhiều người dùng gặp phải là không phân biệt rõ ràng chức năng giữa các lệnh này. Tại sao lại cần đến egrep khi đã có grep? egrep mang lại lợi ích gì vượt trội? Sự mơ hồ này dẫn đến việc không tận dụng được hết sức mạnh của các công cụ mà hệ điều hành cung cấp. Nhiều người dùng chỉ dừng lại ở grep với các mẫu tìm kiếm đơn giản, bỏ lỡ khả năng xử lý các biểu thức phức tạp mà egrep hỗ trợ.
Để giải quyết vấn đề này, bài viết của AZWEB sẽ cung cấp một cái nhìn chi tiết và dễ hiểu về lệnh egrep. Chúng tôi sẽ giúp bạn hiểu rõ egrep là gì, tại sao nó lại mạnh mẽ và khi nào bạn nên sử dụng nó. Nội dung bài viết sẽ được cấu trúc một cách logic, bắt đầu từ cú pháp cơ bản, đi sâu vào các ví dụ thực tiễn, so sánh trực tiếp với grep và fgrep, và cuối cùng là các mẹo để sử dụng hiệu quả. Sau khi đọc xong, bạn sẽ tự tin sử dụng egrep như một chuyên gia để xử lý các tác vụ tìm kiếm phức tạp một cách dễ dàng.
Cú pháp cơ bản của lệnh egrep
Để bắt đầu sử dụng egrep, điều quan trọng đầu tiên là phải nắm vững cú pháp của nó. Về cơ bản, egrep hoạt động tương tự như grep nhưng được trang bị thêm khả năng diễn giải các biểu thức chính quy mở rộng (Extended Regular Expressions – ERE), giúp bạn xây dựng các mẫu tìm kiếm linh hoạt và mạnh mẽ hơn mà không cần phải “escape” (thoát) các ký tự đặc biệt. Điều này làm cho cú pháp trở nên gọn gàng và dễ đọc hơn rất nhiều.
Cấu trúc và các tham số phổ biến
Cú pháp chuẩn của lệnh egrep rất đơn giản và có thể được mô tả như sau:
egrep [tùy_chọn] 'biểu_thức_chính_quy' [tập_tin...]
Trong đó:
- [tùy_chọn]: Là các cờ (flags) để thay đổi hành vi của lệnh.
- ‘biểu_thức_chính_quy’: Là mẫu tìm kiếm bạn muốn đối chiếu. Việc đặt mẫu trong cặp dấu nháy đơn (‘ ‘) là một thói quen tốt để ngăn shell diễn giải các ký tự đặc biệt.
- [tập_tin…]: Là một hoặc nhiều tệp tin mà bạn muốn tìm kiếm. Nếu không có tệp nào được chỉ định,
egrepsẽ đọc từ đầu vào chuẩn (standard input).
Dưới đây là một số tham số phổ biến và hữu ích nhất của egrep:
-i: Bỏ qua sự phân biệt chữ hoa/chữ thường khi tìm kiếm.-v: Đảo ngược kết quả, chỉ in ra những dòng không khớp với mẫu tìm kiếm.-c: Chỉ đếm và in ra số lượng dòng khớp thay vì hiển thị nội dung của chúng.-rhoặc-R: Tìm kiếm đệ quy trong tất cả các tệp và thư mục con của thư mục hiện tại.-l: Chỉ in ra tên của các tệp có chứa dòng khớp với mẫu.-n: Hiển thị số dòng của mỗi dòng kết quả.--color=auto: Tô màu cho phần văn bản khớp với mẫu để dễ dàng nhận diện.
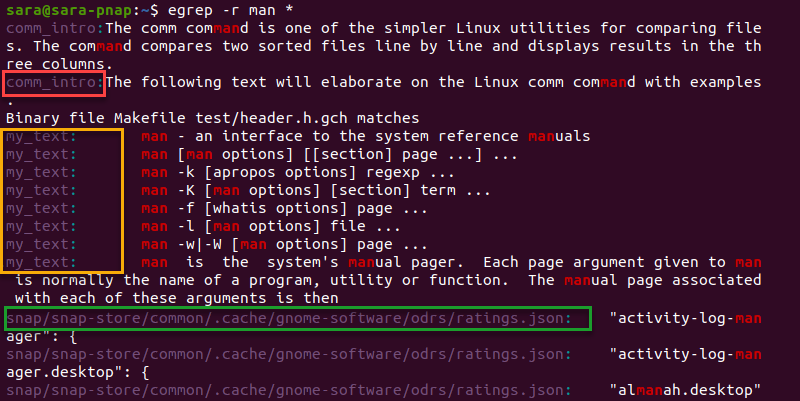
Ví dụ minh họa cú pháp đơn giản
Hãy cùng xem qua một vài ví dụ để hiểu rõ hơn về cách egrep hoạt động. Giả sử chúng ta có một tệp tin tên là logfile.txt với nội dung sau:
[2023-10-27] INFO: User logged in successfully.[2023-10-27] WARNING: Disk space is running low.[2023-10-27] error: Failed to connect to database.[2023-10-27] Error: Payment processing failed.
1. Tìm một chuỗi đơn giản:
Để tìm tất cả các dòng chứa từ “error” (không phân biệt hoa thường), chúng ta sử dụng tùy chọn -i:
egrep -i 'error' logfile.txt
Kết quả sẽ là:
[2023-10-27] error: Failed to connect to database.[2023-10-27] Error: Payment processing failed.
2. Kết hợp nhiều điều kiện với biểu thức chính quy mở rộng:
Đây là lúc sức mạnh của egrep tỏa sáng. Giả sử bạn muốn tìm tất cả các dòng chứa “WARNING” hoặc “error”. Với egrep, bạn có thể sử dụng toán tử | (OR) một cách trực tiếp:
egrep 'WARNING|error' logfile.txt
Kết quả sẽ là:
[2023-10-27] WARNING: Disk space is running low.[2023-10-27] error: Failed to connect to database.
Nếu dùng grep thông thường, bạn sẽ phải viết grep 'WARNING\|error' logfile.txt, cú pháp trông kém trực quan hơn. Sự tiện lợi này làm cho egrep trở thành lựa chọn ưu tiên khi làm việc với các mẫu phức tạp.
![]()
Ví dụ minh họa thực tiễn sử dụng lệnh egrep
Lý thuyết về cú pháp là quan trọng, nhưng sức mạnh thực sự của egrep chỉ được thể hiện rõ ràng qua các ví dụ ứng dụng trong thực tế. Trong công việc hàng ngày của một quản trị viên hệ thống hay nhà phát triển, việc phân tích log và lọc dữ liệu là những tác vụ không thể thiếu. egrep với khả năng hỗ trợ biểu thức chính quy mở rộng trở thành một công cụ cực kỳ hiệu quả cho những nhiệm vụ này.
Tìm kiếm dữ liệu trong tập tin log
Các tập tin log hệ thống thường chứa hàng ngàn, thậm chí hàng triệu dòng thông tin. Việc “đào” ra một thông điệp lỗi cụ thể hoặc theo dõi hoạt động của một địa chỉ IP nhất định giống như mò kim đáy bể nếu không có công cụ phù hợp. egrep giúp bạn thực hiện điều này một cách nhanh chóng.
Ví dụ: Lọc lỗi và cảnh báo trong log máy chủ web Apache
Giả sử bạn đang quản lý một máy chủ web và cần tìm tất cả các dòng log ghi nhận lỗi (error) hoặc các yêu cầu bị từ chối (denied) trong tệp access.log. Bạn có thể sử dụng toán tử | để kết hợp hai điều kiện:
egrep -i 'error|denied' /var/log/apache2/access.log
Ví dụ: Tìm kiếm các địa chỉ IP cụ thể
Bạn nghi ngờ có một vài địa chỉ IP đang thực hiện các hành vi bất thường và muốn xem tất cả hoạt động của chúng. Các địa chỉ IP đó là 192.168.1.10 và 10.0.0.5. Lệnh egrep sẽ giúp bạn tìm tất cả các dòng chứa một trong hai địa chỉ IP này:
egrep '192.168.1.10|10.0.0.5' /var/log/nginx/access.log
Biểu thức chính quy còn cho phép bạn tìm kiếm theo một mẫu IP phức tạp hơn, ví dụ như tìm tất cả IP trong một dải mạng con. Điều này cho thấy sự linh hoạt vượt trội của egrep so với tìm kiếm chuỗi cố định.

Sử dụng egrep để lọc danh sách người dùng, địa chỉ email
Ngoài việc phân tích log, egrep còn rất hữu ích trong việc xử lý các tệp dữ liệu có cấu trúc như danh sách người dùng hoặc email. Bạn có thể dễ dàng lọc, xác thực và trích xuất thông tin dựa trên các mẫu cụ thể.
Ví dụ: Lọc các địa chỉ email hợp lệ từ một tệp
Giả sử bạn có một tệp emails.txt chứa một danh sách các chuỗi, trong đó có cả email hợp lệ và không hợp lệ. Bạn có thể sử dụng một biểu thức chính quy để chỉ trích xuất những dòng trông giống một địa chỉ email:
egrep '^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$' emails.txt
Biểu thức chính quy này có vẻ phức tạp, nhưng nó mô tả một cấu trúc email phổ biến: các ký tự hợp lệ cho tên người dùng, theo sau là ký tự @, tên miền và cuối cùng là tên miền cấp cao nhất có ít nhất hai chữ cái. Đây là điều mà grep cơ bản hoặc fgrep không thể làm được.
Ví dụ: Lọc người dùng hệ thống theo một mẫu tên
Bạn muốn tìm tất cả người dùng trong tệp /etc/passwd có tên bắt đầu bằng “dev” hoặc “test”. Bạn có thể dùng egrep kết hợp với ký tự neo đầu dòng ^:
egrep '^(dev|test)' /etc/passwd
Lệnh này sẽ chỉ trả về những dòng bắt đầu bằng “dev” hoặc “test”, giúp bạn nhanh chóng lọc ra các tài khoản người dùng cần tìm.
Ứng dụng egrep trong tìm kiếm văn bản với biểu thức chính quy
Điểm cốt lõi làm nên sức mạnh của egrep chính là khả năng xử lý các biểu thức chính quy mở rộng (Extended Regular Expressions – ERE). Nếu bạn chỉ tìm kiếm các chuỗi văn bản cố định, grep hay fgrep có thể là đủ. Nhưng khi bạn cần tìm kiếm dựa trên các mẫu (patterns) phức tạp, ví dụ như “một dòng bắt đầu bằng ngày tháng, theo sau là từ ‘ERROR’, và kết thúc bằng một địa chỉ IP”, thì biểu thức chính quy là công cụ duy nhất có thể làm được điều đó.

Tổng quan về biểu thức chính quy trong Linux
Biểu thức chính quy, hay còn gọi là Regex, là một chuỗi các ký tự đặc biệt dùng để định nghĩa một mẫu tìm kiếm. Nó giống như một ngôn ngữ mini chuyên dùng để mô tả và đối sánh văn bản. Trong môi trường Linux, có hai loại biểu thức chính quy chính:
- Biểu thức chính quy cơ bản (Basic Regular Expressions – BRE): Được sử dụng bởi lệnh
grepmặc định. Trong BRE, các ký tự có ý nghĩa đặc biệt như?,+,{,|,(, và)sẽ mất đi sự đặc biệt đó và được coi là các ký tự thông thường, trừ khi bạn đặt một dấu gạch chéo ngược (\) phía trước chúng (ví dụ:\?,\+). - Biểu thức chính quy mở rộng (Extended Regular Expressions – ERE): Được sử dụng bởi
egrep(hoặcgrep -E). Trong ERE, các ký tự đặc biệt nói trên được diễn giải theo đúng ý nghĩa của chúng mà không cần dấu gạch chéo ngược. Điều này làm cho các mẫu regex trở nên ngắn gọn, dễ đọc và dễ viết hơn rất nhiều.
Chính vì sự tiện lợi và rõ ràng này mà egrep trở thành công cụ được ưa chuộng khi cần xây dựng các mẫu tìm kiếm phức tạp.
Các biểu thức chính quy thường dùng với egrep
Dưới đây là một số ký tự và cấu trúc trong biểu thức chính quy mở rộng mà bạn sẽ thường xuyên sử dụng với egrep:
.(Dấu chấm): Đại diện cho bất kỳ một ký tự nào. Ví dụ,'h.t'sẽ khớp với “hat”, “hot”, “h_t”, v.v.|(Toán tử OR): Khớp với biểu thức bên trái hoặc biểu thức bên phải. Ví dụ,'cat|dog'sẽ khớp với “cat” hoặc “dog”.+(Một hoặc nhiều): Khớp với một hoặc nhiều lần xuất hiện của ký tự đứng trước nó. Ví dụ,'go+gle'sẽ khớp với “gogle”, “google”, “gooogle”, v.v.?(Không hoặc một): Khớp với không hoặc một lần xuất hiện của ký tự đứng trước nó. Ví dụ,'colou?r'sẽ khớp với “color” và “colour”.()(Nhóm): Nhóm các biểu thức lại với nhau. Điều này rất hữu ích khi kết hợp với toán tử|. Ví dụ,'Nov(ember)?'sẽ khớp với “Nov” và “November”.[](Lớp ký tự): Khớp với bất kỳ ký tự nào bên trong dấu ngoặc vuông. Ví dụ,'[aeiou]'sẽ khớp với bất kỳ nguyên âm nào. Bạn cũng có thể định nghĩa một khoảng, ví dụ'[0-9]'sẽ khớp với bất kỳ chữ số nào.^(Bắt đầu dòng): Neo mẫu tìm kiếm vào đầu dòng. Ví dụ,'^Error'sẽ chỉ khớp với các dòng bắt đầu bằng “Error”.$(Kết thúc dòng): Neo mẫu tìm kiếm vào cuối dòng. Ví dụ,'failed$'sẽ chỉ khớp với các dòng kết thúc bằng “failed”.
Bằng cách kết hợp các yếu tố trên, bạn có thể tạo ra những mẫu tìm kiếm cực kỳ tinh vi để trích xuất chính xác thông tin mình cần từ bất kỳ tệp văn bản nào.
So sánh egrep với grep và fgrep
Trong hệ sinh thái các công cụ dòng lệnh của Linux, việc có nhiều lệnh với chức năng tương tự nhau đôi khi gây bối rối. egrep, grep, và fgrep đều dùng để tìm kiếm văn bản, nhưng chúng có những điểm khác biệt quan trọng về cách chúng diễn giải mẫu tìm kiếm và hiệu suất hoạt động. Hiểu rõ sự khác biệt này sẽ giúp bạn chọn đúng công cụ cho từng tác vụ cụ thể.

Điểm giống và khác nhau giữa egrep và grep
Trên thực tế, trong hầu hết các hệ thống Linux hiện đại, egrep chính là một bí danh (alias) cho lệnh grep -E. Cả hai đều thực hiện cùng một chức năng: tìm kiếm văn bản bằng cách sử dụng Biểu thức Chính quy Mở rộng (ERE).
Điểm giống nhau:
- Cả hai đều là công cụ tìm kiếm văn bản dựa trên mẫu.
- Chúng chia sẻ chung một bộ các tùy chọn dòng lệnh như
-i,-v,-c,-r, v.v. - Mục tiêu cuối cùng là lọc và hiển thị các dòng khớp với một mẫu cho trước từ một đầu vào văn bản.
Điểm khác biệt chính (giữa grep mặc định và egrep):
- Loại biểu thức chính quy: Đây là sự khác biệt cốt lõi.
grepmặc định sử dụng Biểu thức Chính quy Cơ bản (BRE). Trong BRE, các toán tử như|,+,?, và()không được coi là ký tự đặc biệt và bạn phải “escape” chúng bằng dấu gạch chéo ngược (\) để chúng có tác dụng. Ngược lại,egrep(haygrep -E) sử dụng Biểu thức Chính Quy Mở Rộng (ERE), nơi các ký tự đó được hiểu là toán tử mà không cần escape.
Hãy xem ví dụ sau để thấy rõ sự khác biệt:
- Tìm các dòng chứa “apple” hoặc “orange”:
- Với
grep:grep 'apple\|orange' filename.txt - Với
egrep:egrep 'apple|orange' filename.txt
- Với
Rõ ràng, cú pháp của egrep trong trường hợp này sạch sẽ và dễ đọc hơn, đặc biệt khi các mẫu regex trở nên phức tạp.
Sự khác biệt giữa egrep và fgrep
Tương tự như egrep, fgrep cũng thường là một bí danh cho lệnh grep -F. Chữ “f” trong fgrep là viết tắt của “fixed string” (chuỗi cố định) hoặc “fast” (nhanh).
Sự khác biệt cơ bản:
- Diễn giải mẫu tìm kiếm: Đây là điểm khác biệt lớn nhất.
fgrepkhông hề xử lý biểu thức chính quy. Nó coi mọi ký tự trong mẫu tìm kiếm (bao gồm.,*,|,$) là các ký tự thông thường. Nó chỉ đơn giản là tìm kiếm một chuỗi văn bản cố định. - Hiệu suất: Bởi vì
fgrepkhông cần phải phân tích và biên dịch một biểu thức chính quy phức tạp, nó thường nhanh hơn đáng kể so vớigrepvàegrep, đặc biệt khi tìm kiếm các chuỗi đơn giản trong các tệp lớn.
Khi nào nên dùng fgrep?
Bạn nên sử dụng fgrep khi:
- Bạn chỉ cần tìm một chuỗi văn bản chính xác, không cần sự linh hoạt của regex.
- Mẫu tìm kiếm của bạn chứa các ký tự đặc biệt của regex (ví dụ:
.hoặc*) và bạn muốn tìm chính xác các ký tự đó mà không cần phải escape chúng. - Ưu tiên hàng đầu của bạn là tốc độ tìm kiếm.
Ví dụ: Nếu bạn muốn tìm chuỗi “192.168.1.1”, fgrep '192.168.1.1' log.txt sẽ là lựa chọn tối ưu vì nó không diễn giải các dấu chấm . như các ký tự đại diện.
Tóm lại:
- Dùng
fgrep(grep -F) khi tìm chuỗi cố định, cần tốc độ nhanh nhất. - Dùng
grep(mặc định) khi cần các biểu thức chính quy cơ bản. - Dùng
egrep(grep -E) khi cần sự mạnh mẽ và cú pháp rõ ràng của biểu thức chính quy mở rộng.
Các mẹo và lưu ý khi sử dụng lệnh egrep hiệu quả
Việc nắm vững cú pháp và các biểu thức chính quy là một khởi đầu tuyệt vời. Tuy nhiên, để thực sự khai thác tối đa sức mạnh của egrep, bạn nên biết thêm một số mẹo và lưu ý quan trọng. Những kỹ thuật này không chỉ giúp bạn tìm kiếm nhanh hơn mà còn giúp kết quả trả về rõ ràng và dễ phân tích hơn, đồng thời tránh được các lỗi phổ biến.

Mẹo tăng tốc tìm kiếm với các tham số bổ sung
Ngoài các tham số cơ bản, egrep cung cấp nhiều tùy chọn khác để tối ưu hóa quá trình làm việc của bạn.
1. Làm nổi bật kết quả với --color
Đây là một trong những mẹo hữu ích nhất cho việc phân tích kết quả. Khi sử dụng tùy chọn --color=auto, egrep sẽ tự động tô màu phần văn bản khớp với mẫu tìm kiếm của bạn. Điều này giúp mắt bạn nhanh chóng xác định được thông tin quan trọng trong hàng loạt dòng kết quả.
egrep --color=auto 'ERROR|FAILURE' system.log
Hầu hết các bản phân phối Linux Ubuntu hiện đại đều đã thiết lập bí danh grep thành grep --color=auto, nhưng việc biết rõ tùy chọn này vẫn rất hữu ích.
2. Tìm kiếm đệ quy với -r
Thay vì phải chỉ định từng tệp một, bạn có thể yêu cầu egrep tìm kiếm trong toàn bộ một cây thư mục. Tùy chọn -r (hoặc -R) sẽ thực hiện tìm kiếm đệ quy, lùng sục qua tất cả các tệp và thư mục con. Điều này cực kỳ tiện lợi khi bạn cần tìm một đoạn mã hoặc một dòng cấu hình nhưng không nhớ chính xác nó nằm ở tệp nào.
egrep -r 'database_connection_string' /etc/project_config/
3. Chỉ hiển thị tên tệp với -l
Đôi khi, bạn không cần xem nội dung các dòng khớp mà chỉ muốn biết tệp nào chứa chúng. Tùy chọn -l (list files) sẽ chỉ in ra tên của các tệp có ít nhất một dòng khớp với mẫu, giúp danh sách kết quả của bạn gọn gàng hơn nhiều.
egrep -r -l 'main_function' /var/www/html/
Lưu ý khi sử dụng ký tự đặc biệt trong biểu thức chính quy
Một trong những cạm bẫy lớn nhất khi làm việc với các lệnh dòng lệnh là sự tương tác giữa lệnh và shell (như Bash). Shell có thể diễn giải một số ký tự đặc biệt trước khi chúng được truyền cho egrep, gây ra lỗi hoặc kết quả không mong muốn.
1. Luôn đặt biểu thức chính quy trong dấu nháy đơn (”)
Đây là quy tắc vàng. Việc sử dụng dấu nháy đơn sẽ ngăn shell diễn giải các ký tự đặc biệt như $ (biến), * (ký tự đại diện của shell), ! (lịch sử lệnh), v.v. Nó đảm bảo rằng toàn bộ chuỗi mẫu của bạn được truyền nguyên vẹn đến egrep.
Ví dụ, nếu bạn muốn tìm chuỗi $HOME, lệnh egrep $HOME file.txt sẽ bị lỗi vì shell sẽ thay thế $HOME bằng đường dẫn thư mục nhà của bạn. Lệnh đúng phải là egrep '$HOME' file.txt.
2. Cẩn thận với việc “thoát” (escape) ký tự
Mặc dù egrep giúp bạn không cần escape các ký tự ERE như |, +, ?, nhưng đôi khi bạn lại muốn tìm chính các ký tự đó dưới dạng văn bản thông thường. Trong trường hợp này, bạn cần phải escape chúng bằng dấu gạch chéo ngược (\).
Ví dụ, để tìm dòng văn bản chứa chuỗi “1+1=2”, bạn cần viết:
egrep '1\+1=2' data.txt
Nếu không có dấu \, ký tự + sẽ được hiểu là “một hoặc nhiều số 1”, dẫn đến kết quả sai.
Các vấn đề thường gặp và cách khắc phục
Ngay cả những người dùng có kinh nghiệm đôi khi cũng gặp phải sự cố khi sử dụng egrep. Các vấn đề này thường xuất phát từ cú pháp biểu thức chính quy phức tạp hoặc các vấn đề liên quan đến quyền truy cập tệp tin. Hiểu rõ nguyên nhân và cách khắc phục sẽ giúp bạn tiết kiệm rất nhiều thời gian và tránh được sự thất vọng.
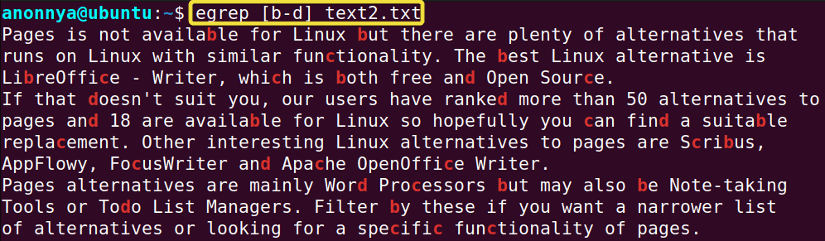
Lỗi không tìm thấy kết quả do cú pháp regex sai
Đây là vấn đề phổ biến nhất. Bạn chắc chắn rằng dữ liệu tồn tại trong tệp, nhưng egrep lại không trả về kết quả nào. Nguyên nhân hầu hết nằm ở biểu thức chính quy của bạn.
Cách kiểm tra và sửa lỗi:
- Bắt đầu từ những gì đơn giản nhất: Thay vì viết ngay một biểu thức phức tạp, hãy bắt đầu với một phần nhỏ và đơn giản của mẫu. Ví dụ, nếu bạn muốn tìm
'^(ERROR|WARN).*User: [a-z]+', hãy thử tìm'ERROR|WARN'trước. Nếu nó hoạt động, hãy thêm dần các phần khác của biểu thức và kiểm tra sau mỗi lần thêm. - Sử dụng công cụ kiểm tra Regex trực tuyến: Các trang web như regex101.com hoặc regexr.com là những công cụ tuyệt vời để gỡ lỗi. Bạn có thể dán biểu thức chính quy và một đoạn văn bản mẫu vào đó. Công cụ sẽ phân tích chi tiết từng phần của regex, giải thích ý nghĩa của nó và tô màu các phần khớp. Điều này giúp bạn trực quan hóa và nhanh chóng phát hiện ra lỗi logic.
- Kiểm tra các ký tự cần escape: Hãy chắc chắn rằng bạn đã escape (thêm
\) đúng cách các ký tự đặc biệt mà bạn muốn tìm kiếm dưới dạng ký tự thông thường, ví dụ như dấu chấm (\.để tìm dấu chấm thật) hoặc dấu cộng (\+). - Chú ý đến phân biệt hoa/thường: Nếu bạn không chắc chắn về cách viết hoa/thường của từ khóa, hãy luôn sử dụng tùy chọn
-iđể bỏ qua sự phân biệt này.
Quyền truy cập và lỗi đọc tập tin
Một vấn đề khác không liên quan đến regex là lỗi “Permission denied” (Quyền truy cập bị từ chối). Lỗi này xảy ra khi người dùng hiện tại không có quyền đọc tệp tin hoặc thư mục mà bạn đang cố gắng tìm kiếm.
Cách xử lý:
- Kiểm tra quyền của tệp/thư mục: Sử dụng lệnh ls -l [đường_dẫn_tệp_hoặc_thư_mục] để xem quyền truy cập. Bạn cần có quyền đọc (ký hiệu là ‘r’) đối với tệp đó.
- Sử dụng
sudo(nếu cần thiết và được phép): Nếu bạn cần tìm kiếm trong các tệp hệ thống mà chỉ người dùngrootmới có quyền truy cập, bạn có thể sử dụngsudođể thực thi lệnh với quyền quản trị cao nhất. - Chuyển hướng lỗi để giữ sạch đầu ra: Khi tìm kiếm đệ quy (với
-r), bạn có thể gặp nhiều lỗi “Permission denied” cho các thư mục khác nhau, làm lộn xộn kết quả tìm kiếm. Bạn có thể chuyển hướng các thông báo lỗi này đến/dev/nullđể chỉ xem các kết quả hợp lệ. - Sử dụng fgrep (grep -F) khi có thể: Nếu bạn chỉ tìm kiếm một chuỗi cố định, hãy luôn ưu tiên
fgrepvì nó nhanh hơn đáng kể. - Kết hợp với các lệnh khác: Thay vì để
egrepxử lý toàn bộ tệp lớn, bạn có thể dùng các lệnh khác để lọc trước dữ liệu. Ví dụ, nếu bạn chỉ quan tâm đến các dòng log của ngày hôm nay, bạn có thể lọc chúng ra trước rồi mới dùngegrepvới mẫu phức tạp hơn. - Tận dụng
--color=autovà-n: Luôn sử dụng--colorđể làm nổi bật kết quả và-nđể hiển thị số dòng. Điều này giúp việc phân tích và định vị thông tin trở nên dễ dàng hơn rất nhiều.
ls -l /var/log/secure-rw-------. 1 root root 12345 Oct 27 10:00 /var/log/secure
Trong ví dụ trên, chỉ người dùng root mới có quyền đọc tệp này.
sudo egrep 'Failed password' /var/log/secure
Lưu ý quan trọng: Hãy sử dụng sudo một cách cẩn thận. Chỉ thực thi các lệnh với quyền root khi bạn hoàn toàn hiểu rõ lệnh đó làm gì và tin tưởng vào nguồn gốc của nó.
sudo egrep -r 'config' /etc 2>/dev/null
Ở đây, 2>/dev/null có nghĩa là chuyển hướng đầu ra lỗi chuẩn (stderr, kênh số 2) đến “hố đen” /dev/null, tức là loại bỏ chúng.
Những thực hành tốt nhất khi sử dụng lệnh egrep
Để trở thành một người dùng egrep thành thạo, việc tuân thủ các thực hành tốt nhất không chỉ giúp tối ưu hóa hiệu suất mà còn đảm bảo tính chính xác và dễ bảo trì của các lệnh bạn viết. Những nguyên tắc này sẽ giúp bạn tránh được các cạm bẫy phổ biến và làm việc hiệu quả hơn trong môi trường dòng lệnh.
1. Luôn kiểm tra biểu thức regex trên tập dữ liệu nhỏ trước
Trước khi chạy một biểu thức chính quy phức tạp trên một tệp log khổng lồ hàng gigabyte, hãy thử nghiệm nó trên một mẫu dữ liệu nhỏ hơn. Bạn có thể trích xuất vài trăm dòng đầu tiên của tệp lớn vào một tệp tạm thời bằng lệnh head:
head -n 500 large_logfile.log > sample.logegrep 'your_complex_regex' sample.log
Cách tiếp cận này giúp bạn nhanh chóng xác minh tính đúng đắn của regex mà không phải chờ đợi lâu và không gây lãng phí tài nguyên hệ thống nếu có lỗi.
2. Sử dụng các tùy chọn để tối ưu hiệu suất và hiển thị kết quả rõ ràng
grep '2023-10-27' huge.log | egrep -i 'error|critical|failure'

3. Tránh dùng egrep cho tập dữ liệu quá lớn mà không lọc bước đầu
Chạy egrep với một regex phức tạp trên một tệp tin cực lớn có thể tiêu tốn rất nhiều CPU và bộ nhớ. Như đã đề cập ở trên, hãy luôn cố gắng giảm kích thước đầu vào cho egrep bằng cách sử dụng các công cụ lọc đơn giản hơn trước đó. Điều này đặc biệt quan trọng trên các máy chủ sản xuất, nơi hiệu suất hệ thống là ưu tiên hàng đầu.
4. Không lạm dụng regex quá phức tạp gây chậm hệ thống
Biểu thức chính quy rất mạnh mẽ, nhưng một regex được viết tồi hoặc quá phức tạp có thể dẫn đến một tình trạng gọi là “catastrophic backtracking”, khiến thời gian thực thi tăng theo cấp số nhân và có thể làm “treo” hệ thống. Hãy giữ cho biểu thức của bạn đơn giản và cụ thể nhất có thể. Ưu tiên sự rõ ràng và hiệu quả hơn là cố gắng tạo ra một regex “thông minh” nhưng khó hiểu và chậm chạp. Đôi khi, việc chạy hai hoặc ba lệnh egrep đơn giản liên tiếp qua pipe (|) lại hiệu quả hơn một lệnh duy nhất với regex cực kỳ phức tạp.
Kết luận
Qua những phân tích chi tiết từ cú pháp, ví dụ thực tiễn cho đến các mẹo sử dụng hiệu quả, có thể thấy rằng egrep không chỉ là một biến thể của grep mà là một công cụ tìm kiếm văn bản vô cùng mạnh mẽ và linh hoạt. Vai trò quan trọng của nó nằm ở việc hỗ trợ các biểu thức chính quy mở rộng (ERE) một cách tự nhiên, giúp người dùng xây dựng các mẫu tìm kiếm phức tạp với cú pháp gọn gàng và dễ đọc hơn. Từ việc gỡ lỗi trong các tệp log hệ thống, lọc danh sách người dùng, cho đến xác thực dữ liệu, egrep đã chứng tỏ mình là một trợ thủ đắc lực không thể thiếu cho bất kỳ quản trị viên hệ thống, nhà phát triển hay bất kỳ ai thường xuyên làm việc trên môi trường dòng lệnh Linux.
Kiến thức lý thuyết là nền tảng, nhưng kỹ năng thực sự chỉ đến từ việc thực hành. AZWEB khuyến khích bạn hãy bắt đầu áp dụng egrep ngay hôm nay. Hãy thử nghiệm với các ví dụ trong bài viết, tự tạo ra các biểu thức chính quy của riêng mình để giải quyết các vấn đề thực tế trong công việc. Càng sử dụng nhiều, bạn sẽ càng thấy được sự tiện lợi và sức mạnh mà công cụ này mang lại. Đừng ngần ngại khám phá và kết hợp egrep với các lệnh khác để tạo ra những chuỗi xử lý dữ liệu hiệu quả. Chúc bạn thành công trên hành trình làm chủ các công cụ dòng lệnh Linux!