Trong kỷ nguyên số hóa, khi dữ liệu lớn (Big Data) và trí tuệ nhân tạo (AI) đang phát triển như vũ bão, nhu cầu về khả năng xử lý tính toán tốc độ cao trở nên cấp thiết hơn bao giờ hết. Để đáp ứng yêu cầu này, việc kết nối hiệu quả giữa các bộ xử lý, đặc biệt là các bộ xử lý đồ họa (GPU), đóng một vai trò cực kỳ quan trọng. Sức mạnh của một hệ thống không chỉ nằm ở từng linh kiện riêng lẻ mà còn phụ thuộc vào khả năng giao tiếp và trao đổi dữ liệu giữa chúng.
Tuy nhiên, các công nghệ kết nối truyền thống như PCI Express (PCIe) đôi khi trở thành “nút thắt cổ chai”, hạn chế băng thông và làm chậm quá trình xử lý các tác vụ đồ họa phức tạp hay huấn luyện những mô hình AI khổng lồ. Khi nhiều GPU cùng làm việc, lượng dữ liệu cần trao đổi giữa chúng là rất lớn, và một kết nối không đủ nhanh sẽ làm giảm hiệu suất tổng thể của toàn hệ thống. Đây chính là lúc NVLink, một công nghệ đột phá của NVIDIA, ra đời để giải quyết bài toán này. NVLink là một chuẩn kết nối tốc độ cao, mở ra một hướng đi hoàn toàn mới trong việc liên kết GPU với GPU và GPU với CPU. Trong bài viết này, AZWEB sẽ cùng bạn tìm hiểu chi tiết NVLink là gì, cách thức hoạt động, những lợi ích vượt trội, ứng dụng thực tế và so sánh nó với các công nghệ khác trên thị trường.
NVLink là gì và cách hoạt động
Để hiểu rõ sức mạnh của NVLink, trước tiên chúng ta cần làm rõ khái niệm và cơ chế vận hành của công nghệ này. Đây không chỉ đơn thuần là một dây cáp kết nối, mà là cả một giao thức truyền tải dữ liệu được thiết kế chuyên biệt cho các tác vụ tính toán hiệu năng cao.
Khái niệm NVLink
NVLink là một giao thức kết nối điểm-tới-điểm (point-to-point) tốc độ cao do NVIDIA phát triển, được giới thiệu lần đầu tiên cùng với kiến trúc GPU Pascal vào năm 2016. Mục đích chính của NVLink là tạo ra một “siêu xa lộ” dữ liệu, cho phép các GPU và CPU có thể giao tiếp trực tiếp với nhau với băng thông cực lớn và độ trễ cực thấp. Công nghệ này được sinh ra để phá vỡ những giới hạn của giao diện PCIe truyền thống.
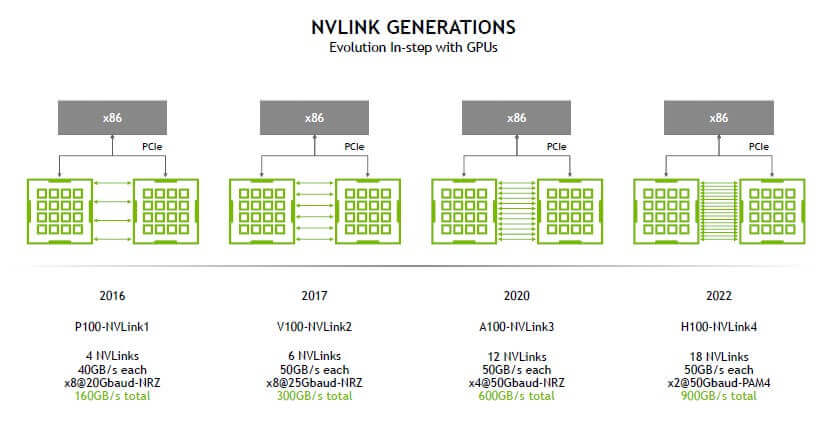
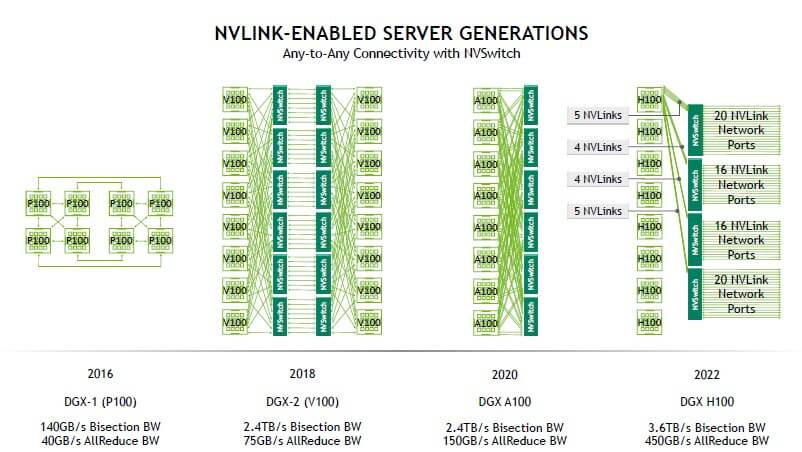
Hãy tưởng tượng, nếu PCIe là một hệ thống đường cao tốc công cộng nơi nhiều loại phương tiện (dữ liệu từ SSD, card mạng, GPU) cùng di chuyển, thì NVLink giống như một đường hầm riêng biệt, đa làn xe, được xây dựng độc quyền cho các GPU “trò chuyện” với nhau. Sự chuyên biệt hóa này giúp loại bỏ tình trạng tắc nghẽn và tối ưu hóa luồng dữ liệu cho các tác vụ đòi hỏi giao tiếp liên tục giữa các bộ xử lý. Qua nhiều thế hệ, từ NVLink 1.0 đến NVLink 4.0 trên các GPU Hopper H100, băng thông đã tăng lên một cách đáng kinh ngạc, đáp ứng nhu cầu ngày càng tăng của AI và khoa học dữ liệu.

Cơ chế kết nối giữa GPU với GPU và GPU với CPU
Cơ chế hoạt động của NVLink dựa trên nguyên tắc kết nối trực tiếp. Thay vì phải đi qua một bộ điều khiển trung tâm trên bo mạch chủ như PCIe, NVLink tạo ra một đường dẫn thẳng giữa hai GPU hoặc giữa một GPU và một CPU hỗ trợ. Mỗi kết nối NVLink bao gồm nhiều làn (lanes) dữ liệu, cho phép truyền và nhận thông tin đồng thời, giúp tăng gấp nhiều lần băng thông so với PCIe.
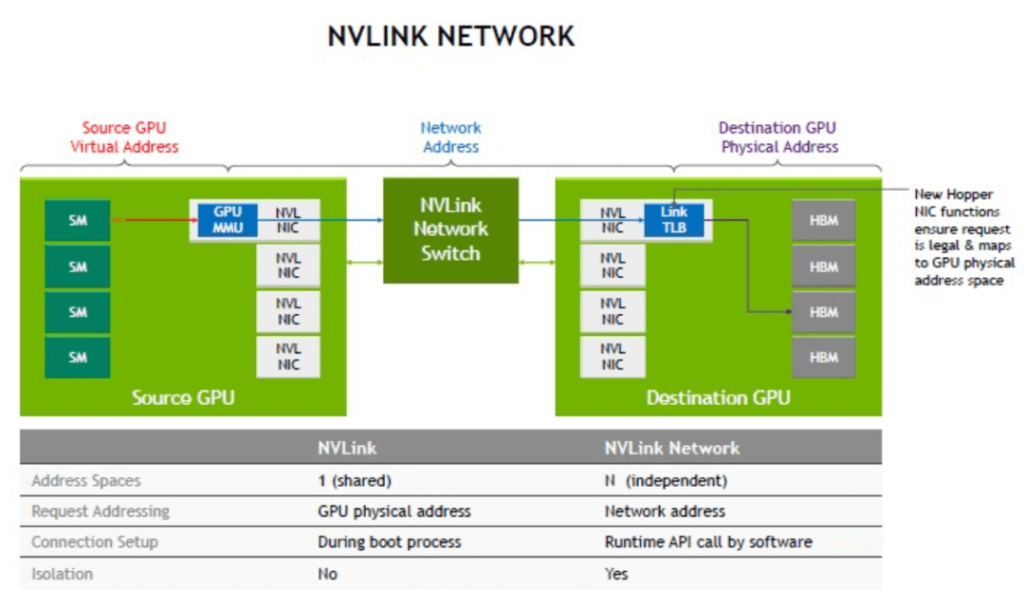
Khi hai GPU được kết nối bằng NVLink, chúng có thể chia sẻ bộ nhớ (VRAM) của nhau một cách liền mạch. Tính năng này được gọi là bộ nhớ hợp nhất (unified memory), cho phép hai GPU hoạt động như một GPU ảo duy nhất với dung lượng VRAM được cộng gộp. Ví dụ, hai card đồ họa NVIDIA RTX A6000, mỗi card có 48GB VRAM, khi kết nối qua NVLink có thể xử lý một tập dữ liệu hoặc một mô hình 3D khổng lồ lên tới 96GB. Dữ liệu không cần phải sao chép qua lại giữa bộ nhớ hệ thống (RAM) và VRAM của từng GPU, giúp giảm độ trễ và tăng tốc độ xử lý một cách ngoạn mục. Tương tự, khi kết nối GPU với CPU (ví dụ như CPU Grace của NVIDIA), NVLink cho phép GPU truy cập trực tiếp vào bộ nhớ hệ thống với tốc độ chưa từng có, loại bỏ các rào cản truyền thống.
Lợi ích của NVLink trong xử lý đồ họa và tính toán
Sự ra đời của NVLink không chỉ là một bước tiến về mặt kỹ thuật, mà còn mang lại những lợi ích cụ thể và đo lường được cho các ngành công nghiệp đòi hỏi sức mạnh tính toán khổng lồ. Từ việc render những thước phim Hollywood cho đến huấn luyện các mô hình trí tuệ nhân tạo phức tạp, NVLink đều đóng vai trò là chất xúc tác quan trọng.
Tăng hiệu suất xử lý đồ họa
Trong lĩnh vực đồ họa chuyên nghiệp, thời gian là tiền bạc. NVLink giúp các nghệ sĩ 3D, kiến trúc sư và nhà làm phim hoạt hình tăng tốc đáng kể quy trình làm việc. Hãy xem xét một vài ví dụ thực tế. Khi xử lý các cảnh quay 3D cực kỳ phức tạp với hàng triệu đa giác, kết cấu (texture) độ phân giải 8K và hiệu ứng ánh sáng chân thực, dung lượng VRAM của một GPU đơn lẻ có thể nhanh chóng bị cạn kiệt. Với NVLink, hai GPU có thể gộp bộ nhớ, cho phép tải toàn bộ cảnh quay vào VRAM và tương tác, chỉnh sửa một cách mượt mà theo thời gian thực mà không cần chờ đợi.
Đối với quá trình render cuối cùng, NVLink cho phép các công cụ render như V-Ray, OctaneRender hay Redshift phân chia công việc hiệu quả hơn giữa hai GPU. Dữ liệu hình học và kết cấu được chia sẻ nhanh chóng, giúp giảm thời gian render từ vài giờ xuống chỉ còn vài phút. Ngay cả trong lĩnh vực game, dù SLI (Scalable Link Interface) qua NVLink không còn được ưu tiên cho các dòng card phổ thông, nó vẫn cho thấy tiềm năng trong việc đạt được độ phân giải siêu cao (8K) và tốc độ khung hình ổn định trên các hệ thống cao cấp nhất.
Nâng cao hiệu quả tính toán trong AI và máy học
Lợi ích của NVLink có lẽ được thể hiện rõ ràng nhất trong lĩnh vực trí tuệ nhân tạo (AI) và học máy (Machine Learning). Các mô hình deep learning hiện đại, chẳng hạn như các mô hình ngôn ngữ lớn (LLM) như GPT-4, có hàng trăm tỷ tham số và đòi hỏi một lượng VRAM khổng lồ để huấn luyện. Việc sử dụng một GPU đơn lẻ là bất khả thi.
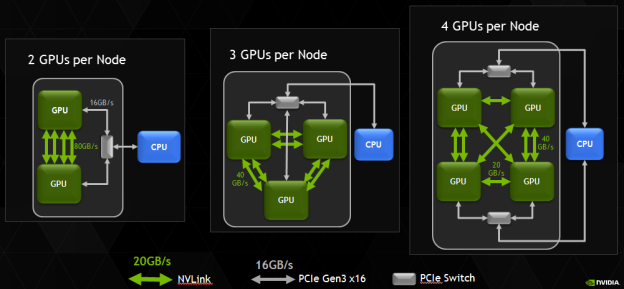
Đây là lúc NVLink phát huy tác dụng. Bằng cách kết nối nhiều GPU (thường là 8 hoặc 16 GPU trong các hệ thống như NVIDIA DGX), NVLink tạo ra một “siêu GPU” với bộ nhớ hợp nhất cực lớn. Dữ liệu huấn luyện và các tham số mô hình có thể được phân chia và xử lý song song trên tất cả các GPU. Giao tiếp tốc độ cao giữa chúng đảm bảo rằng quá trình đồng bộ hóa diễn ra gần như tức thời, giúp giảm đáng kể thời gian huấn luyện mô hình từ vài tháng xuống còn vài tuần, thậm chí vài ngày. Trong lĩnh vực tính toán hiệu năng cao (HPC), các nhà khoa học sử dụng NVLink để mô phỏng các hiện tượng phức tạp như biến đổi khí hậu, dự báo thời tiết hay nghiên cứu dược phẩm, nơi việc trao đổi dữ liệu nhanh chóng giữa các nút tính toán là yếu tố quyết định đến sự thành công của dự án.
Ứng dụng và tác động của NVLink
Công nghệ NVLink đã vượt ra khỏi phạm vi phòng thí nghiệm để trở thành một thành phần cốt lõi trong nhiều hệ thống máy tính hiệu năng cao trên toàn thế giới. Tác động của nó lan tỏa mạnh mẽ, đặc biệt trong các lĩnh vực đòi hỏi khả năng xử lý song song và băng thông bộ nhớ lớn.
Ứng dụng trong hệ thống máy chủ và card đồ họa
NVLink là trái tim của các hệ thống máy chủ và máy trạm chuyên dụng được thiết kế cho AI và HPC. Ví dụ điển hình nhất là dòng siêu máy tính AI NVIDIA DGX. Một hệ thống DGX H100 sử dụng công nghệ NVLink thế hệ thứ tư và NVSwitch để kết nối 8 GPU H100 với nhau, cung cấp tổng băng thông lên tới 900 GB/s cho mỗi GPU. Điều này cho phép chúng hoạt động như một bộ tăng tốc khổng lồ duy nhất, lý tưởng cho việc huấn luyện các mô hình AI lớn nhất hiện nay.
Ngoài các trung tâm dữ liệu, NVLink cũng xuất hiện trên các dòng card đồ họa máy trạm cao cấp như NVIDIA RTX 6000 Ada Generation. Các chuyên gia trong ngành thiết kế, kỹ thuật và sáng tạo nội dung có thể kết nối hai card này lại với nhau để tạo ra một máy trạm với 96GB VRAM, đủ sức xử lý những dự án kỹ thuật số phức tạp nhất. Mặc dù NVIDIA đã ngừng hỗ trợ NVLink trên các dòng card đồ họa chơi game phổ thông như GeForce RTX 40 series, nhưng công nghệ này vẫn tồn tại trên các mẫu flagship trước đó như RTX 3090, mang lại lợi ích cho những người dùng đam mê hiệu năng đỉnh cao.
Tác động đối với lĩnh vực trí tuệ nhân tạo và xử lý đồ họa chuyên sâu
Sự ra đời của NVLink đã tạo ra một cuộc cách mạng thầm lặng nhưng vô cùng mạnh mẽ. Trong lĩnh vực AI, nó đã trở thành một yếu tố then chốt cho phép các nhà nghiên cứu và doanh nghiệp vượt qua các giới hạn về bộ nhớ, từ đó xây dựng và huấn luyện các mô hình ngày càng lớn và phức tạp hơn. Nếu không có băng thông khổng lồ mà NVLink cung cấp, sự bùng nổ của AI tạo sinh (Generative AI) trong những năm gần đây có thể đã không diễn ra với tốc độ nhanh như vậy.
Trong ngành đồ họa, NVLink đã thay đổi cách các studio sản xuất phim ảnh và hiệu ứng hình ảnh (VFX). Thay vì phải dựa vào các trang trại render (render farm) lớn với hàng trăm máy chủ, giờ đây một máy trạm duy nhất với hai GPU kết nối NVLink có thể đảm nhận một khối lượng công việc đáng kể. Điều này không chỉ tiết kiệm chi phí mà còn cho phép các nghệ sĩ có được phản hồi trực quan nhanh hơn, thúc đẩy sự sáng tạo và rút ngắn thời gian hoàn thành dự án. Về cơ bản, NVLink đã dân chủ hóa một phần sức mạnh của siêu máy tính, đưa nó đến gần hơn với các chuyên gia và nhà nghiên cứu cá nhân.
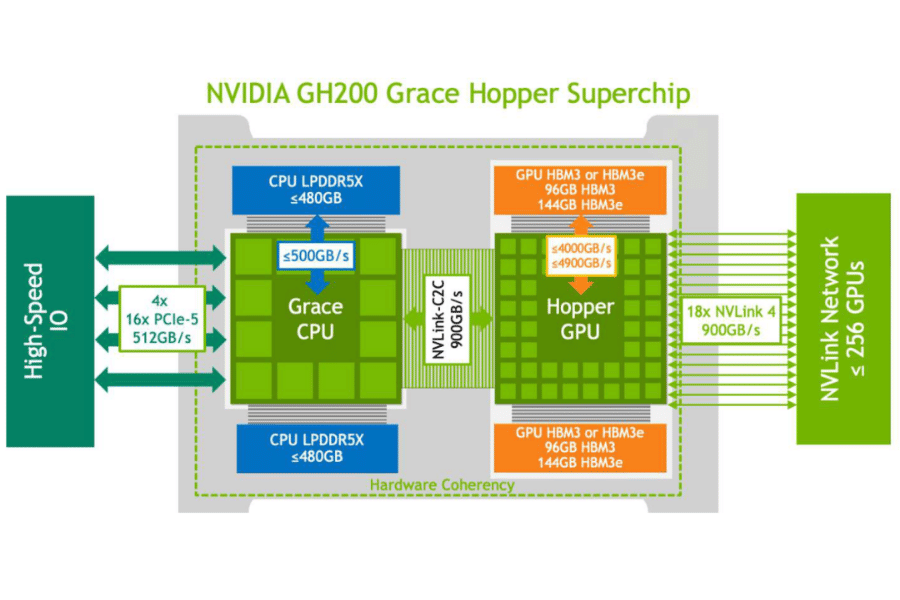
So sánh NVLink với các công nghệ kết nối khác
Để đánh giá đúng giá trị của NVLink, điều quan trọng là phải đặt nó bên cạnh các công nghệ kết nối khác đang tồn tại trên thị trường. Việc so sánh này sẽ làm nổi bật những ưu điểm độc đáo cũng như vị thế của NVLink trong hệ sinh thái phần cứng hiện đại.
So sánh NVLink và PCIe
PCI Express (PCIe) là giao diện kết nối phổ biến nhất trong máy tính, được sử dụng cho hầu hết các linh kiện từ card đồ họa, ổ cứng SSD cho đến card mạng. Tuy nhiên, khi so sánh trực tiếp với NVLink trong vai trò kết nối GPU, sự khác biệt trở nên rõ rệt.
- Băng thông: Đây là điểm khác biệt lớn nhất. Một khe cắm PCIe 5.0 x16 hiện đại cung cấp băng thông khoảng 64 GB/s hai chiều. Trong khi đó, một kết nối NVLink thế hệ thứ ba trên RTX 3090 đã đạt 112.5 GB/s. Thế hệ thứ tư trên GPU H100 đẩy con số này lên tới 900 GB/s (tổng băng thông cho 18 liên kết). Sự chênh lệch này cho thấy NVLink được thiết kế chuyên biệt cho việc truyền tải lượng dữ liệu khổng lồ giữa các GPU.
- Kiến trúc: PCIe hoạt động theo kiến trúc bus, nơi dữ liệu phải đi qua bộ điều khiển trung tâm trên bo mạch chủ. Ngược lại, NVLink là kết nối điểm-tới-điểm, tạo ra một đường dẫn trực tiếp và riêng tư giữa hai thiết bị. Điều này giúp giảm độ trễ và tránh xung đột dữ liệu.
- Mục đích: PCIe là một “con dao đa năng”, được thiết kế để tương thích với nhiều loại thiết bị. NVLink là một “công cụ chuyên dụng”, được tối ưu hóa hoàn toàn cho giao tiếp GPU-GPU và GPU-CPU trong hệ sinh thái của NVIDIA. Do đó, PCIe có tính phổ quát cao hơn, trong khi NVLink mang lại hiệu suất vượt trội cho các tác vụ cụ thể.
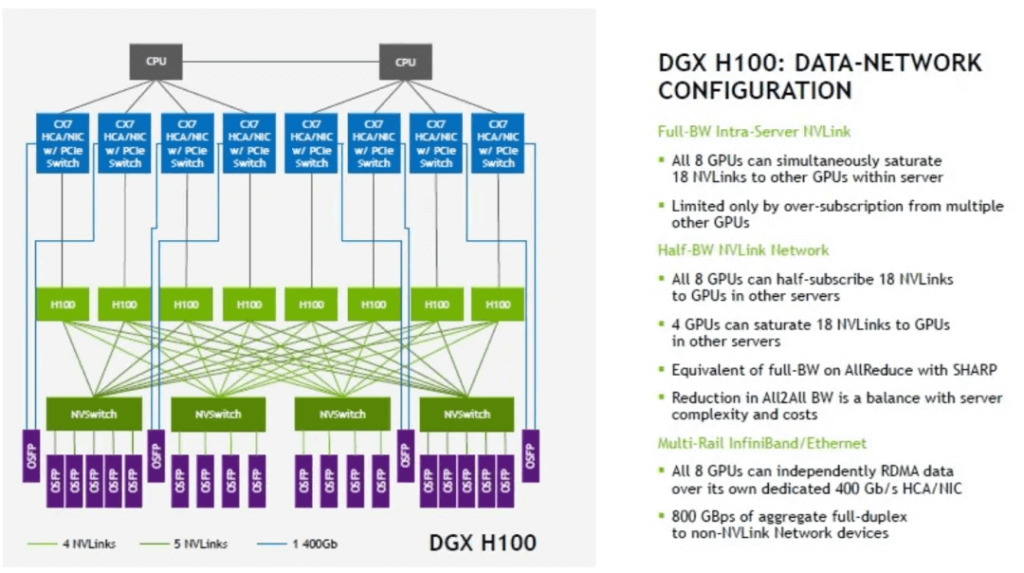
So sánh NVLink với các giao tiếp tốc độ cao khác (VD: Infinity Fabric, CXL)
Ngoài PCIe, thị trường còn có các công nghệ kết nối tốc độ cao khác, mỗi công nghệ có những đặc điểm riêng.
- AMD Infinity Fabric: Đây có thể coi là đối thủ cạnh tranh trực tiếp nhất với NVLink. Infinity Fabric là công nghệ độc quyền của AMD, được sử dụng để kết nối các chiplet trong CPU Ryzen và EPYC, cũng như liên kết các GPU Instinct trong các hệ thống máy chủ. Giống như NVLink, nó cung cấp băng thông cao và độ trễ thấp, nhưng chỉ hoạt động trong hệ sinh thái của AMD. Cuộc cạnh tranh giữa NVLink và Infinity Fabric thúc đẩy sự đổi mới trong lĩnh vực kết nối hiệu năng cao.
- Compute Express Link (CXL): Đây là một tiêu chuẩn kết nối mở, được phát triển dựa trên nền tảng vật lý của PCIe. Mục tiêu của CXL là tạo ra một giao thức chung cho phép CPU, GPU, FPGA và các bộ tăng tốc khác chia sẻ bộ nhớ một cách nhất quán (cache coherency). Không giống như NVLink hay Infinity Fabric là các giải pháp độc quyền, CXL được hỗ trợ bởi một liên minh lớn gồm nhiều công ty công nghệ (bao gồm cả NVIDIA, Intel, AMD). CXL được xem là tương lai của kết nối trong trung tâm dữ liệu, hứa hẹn tạo ra một môi trường linh hoạt và tương thích hơn, nơi các thành phần từ nhiều nhà sản xuất khác nhau có thể hoạt động liền mạch với nhau.
Vấn đề thường gặp và cách khắc phục
Mặc dù NVLink là một công nghệ mạnh mẽ, việc triển khai và sử dụng nó không phải lúc nào cũng suôn sẻ. Người dùng có thể gặp phải một số vấn đề liên quan đến tương thích phần cứng hoặc hiệu năng không như mong đợi. Hiểu rõ những thách thức này và cách khắc phục sẽ giúp bạn tận dụng tối đa tiềm năng của hệ thống.
Tương thích phần cứng và cài đặt hệ thống
Đây là rào cản phổ biến nhất khi người dùng muốn xây dựng một hệ thống đa GPU với NVLink.
- Hỗ trợ từ GPU: Không phải tất cả các card đồ họa NVIDIA đều có cổng kết nối NVLink. Thông thường, chỉ các dòng card cao cấp dành cho máy trạm (như dòng RTX Ada Generation) và một số mẫu flagship chơi game thế hệ cũ (như RTX 3090) mới được trang bị tính năng này. Bạn cần kiểm tra kỹ thông số kỹ thuật của card trước khi mua.
- Cầu nối NVLink Bridge: Mỗi thế hệ GPU lại yêu cầu một loại cầu nối NVLink riêng. Ví dụ, bạn không thể sử dụng cầu nối của dòng RTX 20-series cho card RTX 30-series. Việc sử dụng sai cầu nối sẽ khiến hệ thống không nhận diện được liên kết.
- Bo mạch chủ và khoảng cách: Các bo mạch chủ cần có ít nhất hai khe cắm PCIe x16 với khoảng cách phù hợp để lắp vừa hai card đồ họa và cầu nối NVLink. Một số card đồ họa có kích thước lớn (3-4 slot) có thể gây khó khăn trong việc lắp đặt.
Cách khắc phục: Luôn kiểm tra danh sách tương thích trên trang web chính thức của NVIDIA. Đọc kỹ hướng dẫn của nhà sản xuất bo mạch chủ và card đồ họa. Đo đạc cẩn thận không gian trong vỏ máy trước khi tiến hành lắp đặt để đảm bảo mọi thứ vừa vặn.

Hiệu năng không đạt kỳ vọng
Đôi khi, ngay cả khi đã lắp đặt đúng cách, hiệu suất của hệ thống NVLink vẫn không được như mong đợi. Điều này có thể xuất phát từ nhiều nguyên nhân.
- Phần mềm không tối ưu: Lợi ích của NVLink chỉ phát huy khi ứng dụng hoặc phần mềm bạn đang sử dụng được lập trình để tận dụng khả năng của đa GPU. Nhiều trò chơi hoặc chương trình cũ không hỗ trợ SLI hoặc đa GPU, do đó việc thêm card thứ hai sẽ không mang lại lợi ích gì, thậm chí có thể gây ra lỗi.
- Cấu hình driver sai: Việc kích hoạt chế độ đa GPU (SLI) trong NVIDIA Control Panel là bắt buộc. Nếu không được cấu hình đúng, hệ thống sẽ chỉ sử dụng một card đồ họa duy nhất.
- “Nút thắt cổ chai” ở nơi khác: Một CPU yếu, dung lượng RAM không đủ, hoặc ổ cứng chậm có thể làm hạn chế hiệu năng của cả hệ thống, khiến cặp GPU mạnh mẽ không thể phát huy hết sức mạnh.
Cách khắc phục: Nghiên cứu và đảm bảo phần mềm bạn dùng có hỗ trợ đa GPU. Luôn tải và cài đặt phiên bản driver mới nhất từ NVIDIA. Đảm bảo toàn bộ hệ thống của bạn được xây dựng cân bằng, tránh tình trạng một linh kiện yếu kìm hãm các linh kiện mạnh khác.
Các lưu ý và thực hành tốt nhất khi sử dụng NVLink
Để khai thác tối đa sức mạnh của NVLink và đảm bảo hệ thống hoạt động ổn định, có một vài nguyên tắc và thực hành tốt nhất mà bạn nên tuân thủ. Việc đầu tư vào một hệ thống NVLink là không hề nhỏ, vì vậy việc tối ưu hóa nó ngay từ đầu là vô cùng quan trọng.
- Tối ưu cấu hình phần cứng: Hãy đảm bảo rằng các thành phần khác trong hệ thống của bạn đủ mạnh để hỗ trợ hai GPU cao cấp. Điều này bao gồm một bộ nguồn (PSU) có công suất lớn và chất lượng tốt để cung cấp đủ điện năng, và một hệ thống tản nhiệt hiệu quả (cả tản nhiệt khí và tản nhiệt nước) để giữ cho nhiệt độ của cả hai GPU ở mức an toàn, tránh tình trạng giảm xung nhịp do quá nhiệt.
- Đảm bảo phần mềm và driver NVIDIA được cập nhật đầy đủ: NVIDIA thường xuyên phát hành các bản cập nhật driver để cải thiện hiệu năng, sửa lỗi và bổ sung hỗ trợ cho các ứng dụng mới. Hãy tạo thói quen kiểm tra và cập nhật driver lên phiên bản mới nhất. Đồng thời, hãy chắc chắn rằng các phần mềm chuyên dụng của bạn (như công cụ render, phần mềm AI) cũng được cập nhật để tận dụng các tính năng đa GPU mới nhất.
- Tránh kết hợp NVLink với thiết bị không tương thích: Tuyệt đối không cố gắng kết nối hai card đồ họa khác loại với nhau bằng NVLink (ví dụ: RTX 3080 và RTX 3090). NVLink yêu cầu hai GPU phải hoàn toàn giống hệt nhau về model để có thể hoạt động. Việc kết hợp sai sẽ không được hệ thống hỗ trợ.
- Đánh giá nhu cầu thực tế trước khi đầu tư: Đây là lưu ý quan trọng nhất. NVLink là một công nghệ mạnh mẽ nhưng cũng rất đắt đỏ và chuyên dụng. Hãy tự hỏi: “Quy trình làm việc của tôi có thực sự được hưởng lợi từ việc gộp VRAM và băng thông cực lớn không?”. Đối với nhiều người dùng, kể cả game thủ hay nhà sáng tạo nội dung, một GPU đơn lẻ mạnh nhất (như RTX 4090) thường mang lại hiệu quả đầu tư tốt hơn so với hai GPU thế hệ cũ hơn chạy NVLink. NVLink thực sự tỏa sáng trong các lĩnh vực cực kỳ chuyên sâu như huấn luyện AI, phân tích dữ liệu lớn và render các dự án 3D khổng lồ.
Kết luận
Qua những phân tích chi tiết, có thể khẳng định rằng NVLink không chỉ là một công nghệ kết nối đơn thuần, mà là một giải pháp nền tảng giúp định hình lại giới hạn của tính toán hiệu năng cao. Nó đóng vai trò là “xa lộ” truyền dẫn dữ liệu tốc độ cao, phá vỡ các rào cản về băng thông và bộ nhớ, cho phép các bộ xử lý đồ họa hoạt động như một thể thống nhất mạnh mẽ. Từ việc tăng tốc render các tác phẩm đồ họa đỉnh cao cho đến việc rút ngắn thời gian huấn luyện các mô hình trí tuệ nhân tạo phức tạp, lợi ích mà NVLink mang lại là không thể phủ nhận.
Đối với các doanh nghiệp và chuyên gia hoạt động trong lĩnh vực AI, khoa học dữ liệu, và đồ họa chuyên sâu, việc nghiên cứu và ứng dụng NVLink không còn là một lựa chọn, mà là một yêu cầu tất yếu để duy trì lợi thế cạnh tranh. Khả năng gộp VRAM và giao tiếp siêu tốc giữa các GPU mở ra những cánh cửa mới để giải quyết các bài toán mà trước đây được cho là bất khả thi.
AZWEB khuyến khích bạn hãy bắt đầu tìm hiểu sâu hơn về các dòng sản phẩm GPU hỗ trợ NVLink như NVIDIA RTX Ada Generation hay các hệ thống máy chủ DGX. Nếu điều kiện cho phép, việc thử nghiệm công nghệ này trong môi trường thực tế sẽ giúp bạn cảm nhận rõ nhất sự khác biệt về hiệu suất. Trong thế giới công nghệ luôn vận động, NVLink chính là một trong những chìa khóa giúp chúng ta khai phá những tiềm năng vô hạn của sức mạnh tính toán.