Chào mừng bạn đến với thế giới dữ liệu lớn! Trong kỷ nguyên số hiện nay, việc xử lý hàng terabyte, thậm chí petabyte dữ liệu đã trở thành một yêu cầu tất yếu. Các giải pháp truyền thống thường gặp khó khăn trước quy mô và tốc độ của dữ liệu hiện đại. Đây chính là lúc Apache Hadoop xuất hiện như một người hùng, cung cấp một framework mạnh mẽ để lưu trữ và xử lý các tập dữ liệu khổng lồ một cách phân tán. Để khai thác sức mạnh này, việc lựa chọn một nền tảng ổn định là vô cùng quan trọng, và Ubuntu, với sự linh hoạt và cộng đồng hỗ trợ mạnh mẽ, đã trở thành hệ điều hành được tin dùng. Bài viết này sẽ là kim chỉ nam, hướng dẫn bạn từng bước chi tiết để cài đặt Hadoop trên Ubuntu một cách hiệu quả và dễ dàng nhất.
Tổng quan về Hadoop và vai trò trong xử lý dữ liệu lớn
Hadoop là gì?
Hadoop, hay Apache Hadoop, là một framework mã nguồn mở được viết bằng Java, cho phép xử lý phân tán các tập dữ liệu lớn trên các cụm máy tính. Thay vì sử dụng một máy chủ siêu mạnh và đắt đỏ, Hadoop cho phép bạn kết hợp nhiều máy tính thông thường lại với nhau để tạo thành một hệ thống hợp nhất với năng lực xử lý vượt trội. Sức mạnh của Hadoop đến từ ba thành phần cốt lõi. Đầu tiên là HDFS (Hadoop Distributed File System), hệ thống lưu trữ phân tán, chịu trách nhiệm chia nhỏ dữ liệu và lưu trữ trên nhiều máy trong cụm, đảm bảo an toàn và khả năng chịu lỗi. Tiếp theo là MapReduce, mô hình lập trình dùng để xử lý song song lượng dữ liệu khổng lồ. Cuối cùng là YARN (Yet Another Resource Negotiator), trình quản lý tài nguyên, điều phối và phân bổ tài nguyên hệ thống (CPU, RAM) cho các ứng dụng chạy trên cụm.
Ưu điểm chính của Hadoop là khả năng mở rộng quy mô một cách linh hoạt. Bạn có thể dễ dàng thêm hoặc bớt các nút (máy tính) trong cụm mà không làm gián đoạn hoạt động. Hơn nữa, Hadoop được thiết kế để phát hiện và xử lý lỗi ở cấp độ phần mềm, tự động sao chép dữ liệu để đảm bảo tính sẵn sàng cao. Điều này làm cho nó trở thành một giải pháp cực kỳ hiệu quả về chi phí cho các bài toán dữ liệu lớn.

Ứng dụng và vai trò của Hadoop trong thực tiễn
Hadoop không chỉ là một công cụ công nghệ, mà còn là nền tảng cho cuộc cách mạng dữ liệu lớn. Nó được ứng dụng rộng rãi trong nhiều lĩnh vực đòi hỏi phân tích dữ liệu quy mô lớn. Các công ty công nghệ hàng đầu như Facebook, Yahoo, và LinkedIn sử dụng Hadoop để phân tích hành vi người dùng, tối ưu hóa quảng cáo và đề xuất nội dung. Trong lĩnh vực tài chính, Hadoop giúp phát hiện gian lận thẻ tín dụng bằng cách phân tích hàng tỷ giao dịch trong thời gian thực. Ngành y tế cũng tận dụng Hadoop để phân tích hồ sơ bệnh án điện tử và dữ liệu gen, thúc đẩy các nghiên cứu y học đột phá.
Trong hệ sinh thái dữ liệu lớn, Hadoop đóng vai trò là hạt nhân trung tâm. Nó là nền tảng lưu trữ và xử lý ban đầu, nơi dữ liệu thô được thu thập và làm sạch. Từ đó, các công cụ khác trong hệ sinh thái như Spark, Hive, và Pig có thể truy cập và xử lý dữ liệu này cho các mục đích chuyên sâu hơn như truy vấn SQL, học máy (Machine Learning) và trí tuệ nhân tạo (AI). Lý do Hadoop được ưu tiên là vì tính linh hoạt, chi phí thấp và khả năng xử lý nhiều định dạng dữ liệu khác nhau, từ có cấu trúc đến phi cấu trúc.
Giới thiệu hệ điều hành Ubuntu và các yêu cầu cài đặt
Lý do chọn Ubuntu cho môi trường Hadoop
Khi lựa chọn một hệ điều hành để triển khai Hadoop, Ubuntu thường là cái tên được nhắc đến đầu tiên. Sự phổ biến này không phải là ngẫu nhiên. Ubuntu, một bản phân phối Linux dựa trên Debian, nổi tiếng với sự ổn định và hiệu suất cao, hai yếu tố cực kỳ quan trọng cho một hệ thống xử lý dữ liệu lớn. Hệ điều hành này cung cấp một môi trường hoạt động đáng tin cậy, giảm thiểu nguy cơ xảy ra lỗi hệ thống có thể ảnh hưởng đến các tác vụ xử lý kéo dài.
Bên cạnh đó, Ubuntu sở hữu một cộng đồng người dùng và nhà phát triển khổng lồ trên toàn thế giới. Điều này có nghĩa là bạn có thể dễ dàng tìm thấy tài liệu hướng dẫn, các bài viết chia sẻ kinh nghiệm và sự hỗ trợ nhanh chóng khi gặp sự cố. Hệ thống quản lý gói APT (Advanced Package Tool) của Ubuntu cũng giúp việc cài đặt và cập nhật các phần mềm phụ thuộc trở nên đơn giản và nhanh chóng. Để cài đặt Hadoop, các phiên bản Ubuntu LTS (Long-Term Support) như Ubuntu 20.04 LTS hoặc 22.04 LTS là lựa chọn lý tưởng vì chúng được hỗ trợ cập nhật bảo mật và sửa lỗi trong thời gian dài.
Các yêu cầu phần cứng và phần mềm cơ bản
Trước khi bắt tay vào cài đặt, việc đảm bảo hệ thống của bạn đáp ứng các yêu cầu tối thiểu là rất quan trọng để Hadoop có thể hoạt động trơn tru. Mặc dù Hadoop có thể chạy trên phần cứng thông thường, một cấu hình tốt sẽ mang lại hiệu suất cao hơn. Về phần cứng, bạn nên có ít nhất 8GB RAM, tuy nhiên 16GB trở lên được khuyến nghị cho các tác vụ xử lý phức tạp. Về CPU, một bộ xử lý đa lõi (tối thiểu 4 lõi) sẽ giúp tăng tốc độ xử lý song song. Dung lượng ổ cứng cần đủ lớn để chứa cả hệ điều hành, bộ cài Hadoop và dữ liệu của bạn, tối thiểu nên có khoảng 50GB dung lượng trống.
Về phần mềm, yêu cầu quan trọng nhất là Java Development Kit (JDK). Hadoop được xây dựng hoàn toàn bằng Java, do đó nó không thể hoạt động nếu thiếu môi trường Java. Phiên bản Java tương thích phổ biến nhất với các phiên bản Hadoop gần đây là OpenJDK 8 hoặc OpenJDK 11. Việc cài đặt đúng phiên bản Java là bước đầu tiên và tiên quyết để đảm bảo quá trình cài đặt Hadoop sau này không gặp lỗi. Bạn cũng cần có trình truy cập SSH để quản lý các nút trong cụm, ngay cả khi chỉ cài đặt trên một máy.
Hướng dẫn chuẩn bị môi trường trên Ubuntu
Cập nhật hệ thống và cài đặt các phụ thuộc cần thiết
Bước đầu tiên trong mọi quy trình cài đặt trên Ubuntu là đảm bảo hệ thống của bạn được cập nhật lên phiên bản mới nhất. Điều này giúp vá các lỗ hổng bảo mật và đảm bảo tính tương thích của các gói phần mềm. Bạn hãy mở Terminal và chạy lần lượt hai lệnh sau. Lệnh đầu tiên sẽ làm mới danh sách các gói phần mềm có sẵn từ kho lưu trữ.
sudo apt update
Lệnh thứ hai sẽ nâng cấp tất cả các gói đã cài đặt trên hệ thống của bạn lên phiên bản mới nhất.
sudo apt upgrade
Sau khi hệ thống đã được cập nhật, chúng ta cần cài đặt các phụ thuộc cần thiết. Quan trọng nhất là OpenJDK, môi trường chạy Java cho Hadoop. Chúng ta sẽ cài đặt OpenJDK phiên bản 11.
sudo apt install openjdk-11-jdk
Bạn cũng cần cài đặt SSH client và server, vì Hadoop sử dụng SSH để giao tiếp giữa các nút trong cụm.
sudo apt install ssh openssh-server

Tạo người dùng và thiết lập quyền cho Hadoop
Việc chạy các dịch vụ hệ thống dưới một tài khoản người dùng riêng biệt thay vì tài khoản root là một thực hành bảo mật tốt. Điều này giúp giới hạn quyền truy cập và giảm thiểu rủi ro nếu có sự cố xảy ra. Chúng ta sẽ tạo một người dùng mới có tên là hadoop để quản lý và vận hành cụm Hadoop.
sudo adduser hadoop
Bạn sẽ được yêu cầu đặt mật khẩu và cung cấp một số thông tin cho người dùng mới. Sau khi tạo xong, hãy thêm người dùng hadoop vào nhóm sudo để có thể thực hiện các tác vụ quản trị khi cần.
sudo usermod -aG sudo hadoop
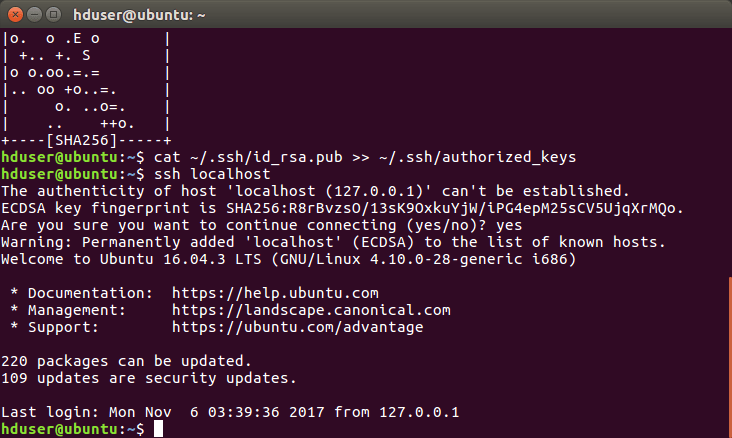
Tiếp theo, chúng ta cần thiết lập truy cập SSH không cần mật khẩu (passwordless SSH) cho chính người dùng hadoop trên máy localhost. Điều này là bắt buộc để các script quản lý của Hadoop có thể khởi động và dừng các dịch vụ trên cụm. Chuyển sang người dùng hadoop:
su - hadoop
Sau đó, tạo một cặp khóa SSH mới và sao chép khóa công khai vào danh sách các khóa được ủy quyền.
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 0600 ~/.ssh/authorized_keys
Bây giờ bạn có thể kiểm tra bằng cách SSH vào localhost. Lần đầu tiên có thể yêu cầu xác nhận, nhưng những lần sau sẽ không yêu cầu mật khẩu.
ssh localhost
Quá trình cài đặt và cấu hình Hadoop trên Ubuntu
Tải và giải nén bộ cài Hadoop
Sau khi đã chuẩn bị xong môi trường, bước tiếp theo là tải về bộ cài đặt Hadoop. Bạn nên truy cập trang web chính thức của Apache Hadoop để tìm phiên bản ổn định mới nhất. Tại thời điểm viết bài, một phiên bản phổ biến là Hadoop 3.x. Sử dụng lệnh wget để tải trực tiếp file nén về máy.
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
Khi quá trình tải xuống hoàn tất, bạn sẽ có một file hadoop-3.3.6.tar.gz trong thư mục hiện tại. Bây giờ, hãy giải nén file này bằng lệnh tar.
tar -xvf hadoop-3.3.6.tar.gz
Để dễ quản lý, chúng ta nên di chuyển thư mục Hadoop vừa giải nén vào một vị trí chuẩn của hệ thống, ví dụ như /usr/local/hadoop. Đồng thời, chúng ta cũng cần thay đổi quyền sở hữu của thư mục này cho người dùng hadoop đã tạo trước đó.
sudo mv hadoop-3.3.6 /usr/local/hadoopsudo chown -R hadoop:hadoop /usr/local/hadoop
Cấu hình các file cơ bản (core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml)
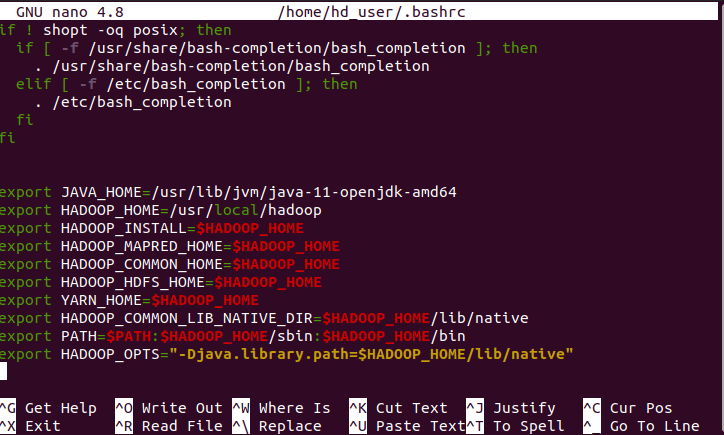
Đây là bước quan trọng nhất, quyết định Hadoop có hoạt động đúng hay không. Chúng ta cần thiết lập các biến môi trường và chỉnh sửa một số file cấu hình. Đầu tiên, hãy mở file .bashrc của người dùng hadoop để thêm các biến môi trường.
nano ~/.bashrc
Thêm các dòng sau vào cuối file:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Lưu file và kích hoạt các thay đổi: source ~/.bashrc. Tiếp theo, chúng ta cần chỉnh sửa file hadoop-env.sh để chỉ định JAVA_HOME cho Hadoop.
nano /usr/local/hadoop/etc/hadoop/hadoop-env.sh
Tìm dòng export JAVA_HOME= và sửa thành: export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64.
Bây giờ, chúng ta sẽ cấu hình các file XML.
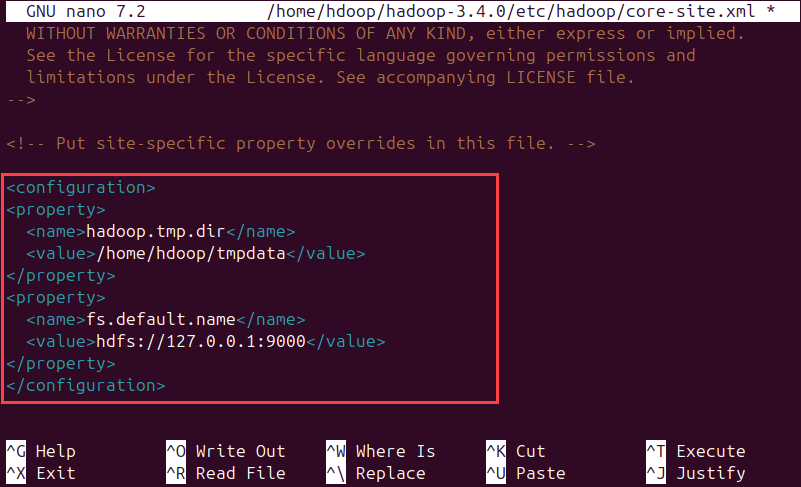
- core-site.xml:
nano /usr/local/hadoop/etc/hadoop/core-site.xml. Thêm vào giữa thẻ<configuration>:
<property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property>
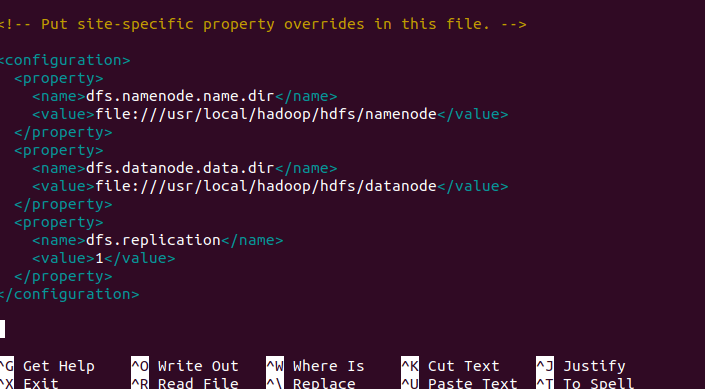
- hdfs-site.xml:
nano /usr/local/hadoop/etc/hadoop/hdfs-site.xml. Trước tiên, tạo các thư mục cho NameNode và DataNode:mkdir -p /home/hadoop/hdfs/namenodevàmkdir -p /home/hadoop/hdfs/datanode. Sau đó thêm vào file:
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hdfs/datanode</value> </property>
- mapred-site.xml:
nano /usr/local/hadoop/etc/hadoop/mapred-site.xml. Thêm vào:
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
- yarn-site.xml:
nano /usr/local/hadoop/etc/hadoop/yarn-site.xml. Thêm vào:
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
Kiểm tra và khởi động dịch vụ Hadoop
Khởi tạo hệ thống tập tin HDFS
Sau khi hoàn tất việc cấu hình, bước tiếp theo là định dạng (format) NameNode. Quá trình này sẽ khởi tạo hệ thống tập tin phân tán HDFS. Đây là một bước cực kỳ quan trọng và bạn chỉ thực hiện một lần duy nhất khi thiết lập cụm. Việc chạy lại lệnh này trên một cụm đang hoạt động sẽ xóa toàn bộ dữ liệu.
Hãy chắc chắn rằng bạn đang ở trong phiên làm việc của người dùng hadoop và chạy lệnh sau:
hdfs namenode -format
Nếu quá trình thành công, bạn sẽ thấy rất nhiều thông tin xuất ra màn hình, và dòng cuối cùng sẽ có nội dung tương tự như “Storage directory … has been successfully formatted” và “Exiting with status 0”. Điều này xác nhận rằng NameNode đã được khởi tạo và sẵn sàng hoạt động. Nếu bạn gặp lỗi, hãy kiểm tra lại các biến môi trường và đường dẫn đã cấu hình trong các file XML.
Khởi động các daemon Hadoop
Bây giờ, mọi thứ đã sẵn sàng để khởi động các dịch vụ của Hadoop. Hadoop cung cấp các script tiện lợi để khởi động tất cả các tiến trình (daemon) cần thiết. Đầu tiên, hãy khởi động HDFS (bao gồm NameNode và DataNode).
start-dfs.sh
Lần đầu chạy, hệ thống có thể hỏi bạn xác nhận kết nối SSH. Hãy nhập “yes” và nhấn Enter. Sau khi script chạy xong, bạn có thể kiểm tra các tiến trình đang chạy bằng lệnh jps. Bạn sẽ thấy các tiến trình có tên là NameNode, DataNode, và SecondaryNameNode.
Tiếp theo, hãy khởi động YARN (bao gồm ResourceManager và NodeManager).
start-yarn.sh
Chạy lại lệnh jps, bây giờ danh sách sẽ có thêm ResourceManager và NodeManager. Sự hiện diện đầy đủ của năm tiến trình này xác nhận rằng cụm Hadoop đơn nút của bạn đã khởi động thành công. Bạn cũng có thể truy cập các giao diện web để theo dõi trạng thái cụm, chẳng hạn như giao diện của NameNode tại http://localhost:9870 và của ResourceManager tại http://localhost:8088.
Thiết lập cụm Hadoop đơn nút hoặc phân tán
Cụm Hadoop đơn nút (Single Node Cluster)
Mô hình mà chúng ta vừa hoàn thành cài đặt chính là một cụm Hadoop đơn nút (Single Node Cluster). Trong mô hình này, tất cả các tiến trình cốt lõi của Hadoop, bao gồm cả các tiến trình chủ (master) như NameNode, ResourceManager và các tiến trình tớ (worker) như DataNode, NodeManager, đều chạy trên cùng một máy tính. Đây là cấu hình lý tưởng cho những người mới bắt đầu tìm hiểu về Hadoop.
Bạn nên sử dụng cụm đơn nút cho các mục đích học tập, phát triển và thử nghiệm các ứng dụng MapReduce mà không cần đến tài nguyên của một cụm máy tính thực sự. Nó cho phép bạn làm quen với các lệnh, quy trình làm việc và cấu trúc của Hadoop một cách nhanh chóng và tiện lợi. Các bước cấu hình cho cụm đơn nút tương đối đơn giản, chủ yếu là đảm bảo các dịch vụ có thể giao tiếp với nhau trên localhost, như chúng ta đã làm ở các bước trên. Mặc dù không có khả năng xử lý dữ liệu quy mô lớn, nó là nền tảng vững chắc để bạn hiểu rõ cách Hadoop hoạt động trước khi chuyển sang môi trường phức tạp hơn.

Cụm Hadoop phân tán (Multi Node Cluster)
Khi bạn đã sẵn sàng làm việc với dữ liệu thực sự lớn, bạn sẽ cần mở rộng thành một cụm Hadoop phân tán (Multi Node Cluster). Khái niệm phân tán có nghĩa là các tiến trình của Hadoop sẽ được triển khai trên nhiều máy tính khác nhau, kết nối với nhau qua mạng. Một cụm phân tán điển hình bao gồm một nút chủ (Master Node) chạy NameNode và ResourceManager, và nhiều nút tớ (Worker Nodes) chạy DataNode và NodeManager.
Việc mở rộng từ cụm đơn nút lên cụm phân tán bao gồm các bước chính sau. Đầu tiên, bạn cần chuẩn bị các máy tính sẽ đóng vai trò là nút tớ. Tiếp theo, thiết lập kết nối SSH không cần mật khẩu từ nút chủ đến tất cả các nút tớ. Sau đó, bạn cần chỉnh sửa file workers (hoặc slaves trong các phiên bản cũ) trong thư mục cấu hình của Hadoop trên nút chủ, liệt kê địa chỉ IP hoặc hostname của tất cả các nút tớ. Cuối cùng, bạn sao chép toàn bộ thư mục cấu hình Hadoop từ nút chủ sang tất cả các nút tớ để đảm bảo chúng đồng bộ. Khi khởi động cụm từ nút chủ bằng các script start-dfs.sh và start-yarn.sh, các dịch vụ sẽ tự động được kích hoạt trên các nút tương ứng.
Khắc phục sự cố phổ biến trong quá trình cài đặt
Lỗi liên quan đến biến môi trường JAVA_HOME không chính xác
Một trong những lỗi phổ biến nhất mà người dùng mới gặp phải là thiết lập sai biến môi trường JAVA_HOME. Vì Hadoop là một ứng dụng Java, nó cần biết chính xác vị trí của bộ cài đặt Java để hoạt động. Nếu JAVA_HOME không được đặt hoặc trỏ đến một đường dẫn sai, bạn sẽ gặp lỗi “JAVA_HOME is not set” hoặc các lỗi tương tự khi chạy bất kỳ lệnh Hadoop nào.
Để kiểm tra, bạn có thể chạy lệnh echo $JAVA_HOME trong terminal. Lệnh này sẽ hiển thị đường dẫn hiện tại được gán cho biến môi trường. Nếu kết quả trống hoặc không đúng với đường dẫn cài đặt OpenJDK của bạn (thường là /usr/lib/jvm/...), bạn cần phải chỉnh sửa lại. Cách khắc phục là mở lại file .bashrc và file hadoop-env.sh để kiểm tra và sửa lại đường dẫn JAVA_HOME cho chính xác. Sau khi sửa, đừng quên chạy lệnh source ~/.bashrc để áp dụng thay đổi ngay lập tức.

Hadoop không thể khởi động NameNode hoặc DataNode
Một vấn đề khác cũng thường gặp là một hoặc nhiều dịch vụ của Hadoop không thể khởi động. Bạn chạy start-dfs.sh, nhưng khi kiểm tra bằng jps, lại không thấy NameNode hoặc DataNode đâu cả. Có nhiều nguyên nhân có thể dẫn đến tình trạng này. Nguyên nhân phổ biến nhất là sai sót trong các file cấu hình XML, chẳng hạn như gõ sai tên thuộc tính, giá trị hoặc đường dẫn thư mục không tồn tại.
Cách tốt nhất để chẩn đoán vấn đề là kiểm tra các file log của Hadoop. Các file log này nằm trong thư mục $HADOOP_HOME/logs. Hãy mở các file log tương ứng với dịch vụ bị lỗi (ví dụ: hadoop-hadoop-namenode-YourHostName.log) và tìm kiếm các thông báo lỗi (thường có từ khóa ERROR hoặc FATAL). Các thông báo này sẽ cho bạn biết chính xác nguyên nhân, có thể là do vấn đề về quyền truy cập thư mục, cổng mạng đã bị sử dụng bởi một ứng dụng khác, hoặc bạn đã vô tình format lại NameNode trong khi DataNode vẫn còn dữ liệu cũ. Từ đó, bạn có thể tìm ra hướng giải quyết phù hợp.
Các thực hành tốt khi cài đặt và vận hành Hadoop trên Ubuntu
Để đảm bảo hệ thống Hadoop của bạn hoạt động ổn định, an toàn và hiệu quả, việc tuân thủ các thực hành tốt là vô cùng cần thiết. Đầu tiên và quan trọng nhất, hãy luôn sử dụng một tài khoản người dùng riêng biệt (như hadoop mà chúng ta đã tạo) để chạy các dịch vụ Hadoop. Điều này giúp cô lập các tiến trình và hạn chế thiệt hại nếu có sự cố bảo mật xảy ra, thay vì chạy chúng với quyền root tối cao.
Bảo mật và bảo trì cũng là yếu tố then chốt. Hãy đảm bảo rằng hệ điều hành Ubuntu và phiên bản Hadoop của bạn luôn được cập nhật lên các bản vá mới nhất để tránh các lỗ hổng đã biết. Đồng thời, việc sao lưu định kỳ các file cấu hình quan trọng và siêu dữ liệu của NameNode là rất quan trọng. Mất siêu dữ liệu của NameNode có thể khiến toàn bộ dữ liệu trên HDFS không thể truy cập được.
Bên cạnh đó, việc giám sát và kiểm soát tài nguyên hệ thống là không thể thiếu. Hãy theo dõi việc sử dụng CPU, RAM và dung lượng đĩa để tránh tình trạng quá tải có thể làm sập cụm. Cuối cùng, một lời khuyên quan trọng là không bao giờ cài đặt và thử nghiệm Hadoop lần đầu tiên trên một hệ thống sản xuất đang chạy các ứng dụng quan trọng. Luôn sử dụng một môi trường thử nghiệm riêng biệt để đảm bảo an toàn cho dữ liệu và dịch vụ hiện có của bạn.
Kết luận
Qua bài viết này, chúng ta đã cùng nhau đi qua một hành trình chi tiết, từ việc tìm hiểu Hadoop là gì cho đến các bước cài đặt và cấu hình hoàn chỉnh trên hệ điều hành Ubuntu. Việc thiết lập thành công một cụm Hadoop là bước đệm quan trọng, mở ra cánh cửa để bạn khai thác sức mạnh của dữ liệu lớn, phục vụ cho các bài toán phân tích phức tạp, học máy và trí tuệ nhân tạo. Ubuntu, với sự ổn định và cộng đồng hỗ trợ mạnh mẽ, đã chứng tỏ là một nền tảng tuyệt vời cho Hadoop.
Quá trình cài đặt có thể có nhiều bước và đòi hỏi sự cẩn thận, nhưng bằng cách thực hiện tuần tự và kiểm tra kỹ lưỡng từng cấu hình, bạn hoàn toàn có thể xây dựng thành công môi trường của riêng mình. Đừng ngần ngại thử nghiệm và khám phá. Sau khi đã cài đặt thành công, bước tiếp theo có thể là chạy thử một chương trình MapReduce đơn giản hoặc tìm hiểu cách tích hợp các công cụ khác trong hệ sinh thái như Spark, Hive.
Chúc bạn thành công trên con đường chinh phục thế giới dữ liệu lớn