Bạn đã bao giờ truy cập một trang web và nhận được thông báo lỗi “không thể kết nối”? Sự cố này, dù chỉ diễn ra trong vài phút, cũng có thể gây ra những thiệt hại không nhỏ. Trong thế giới kỹ thuật số luôn đòi hỏi sự kết nối liên tục, bất kỳ sự gián đoạn nào đối với hệ thống đều có thể ảnh hưởng tiêu cực đến trải nghiệm người dùng, doanh thu và uy tín của doanh nghiệp. Vấn đề về thời gian chết (downtime) không chỉ là một sự bất tiện, mà còn là một rủi ro kinh doanh nghiêm trọng. Để giải quyết thách thức này, khái niệm High Availability (HA) hay Tính Sẵn Sàng Cao đã ra đời. Đây là giải pháp cốt lõi giúp đảm bảo hệ thống luôn hoạt động ổn định, ngăn chặn downtime và tối đa hóa hiệu suất. Bài viết này sẽ đi sâu vào định nghĩa, các kỹ thuật, ứng dụng và ví dụ thực tế về High Availability.
Định nghĩa High Availability là gì
Khái niệm cơ bản về High Availability
Vậy chính xác thì High Availability là gì? High Availability (HA), hay Tính Sẵn Sàng Cao, là một nguyên tắc thiết kế hệ thống và phương pháp triển khai trong công nghệ thông tin nhằm đảm bảo một mức độ hoạt động liên tục được chấp nhận trong một khoảng thời gian nhất định. Mục tiêu của HA là loại bỏ các điểm lỗi đơn (single points of failure), giúp hệ thống vẫn tiếp tục vận hành ngay cả khi một hoặc nhiều thành phần gặp sự cố. Thay vì tập trung vào việc ngăn chặn 100% lỗi, HA tập trung vào việc đảm bảo khả năng phục hồi nhanh chóng và tự động để người dùng cuối không cảm nhận được sự gián đoạn.
Độ sẵn sàng của một hệ thống thường được đo bằng tỷ lệ phần trăm thời gian hoạt động (uptime) trong một năm. Ví dụ, một hệ thống có độ sẵn sàng “năm số 9” (99,999%) nghĩa là thời gian chết (downtime) tối đa chỉ khoảng 5,26 phút mỗi năm. Để đạt được con số ấn tượng này, các yếu tố như dự phòng (redundancy), giám sát (monitoring) và tự động chuyển đổi dự phòng (failover) phải được tích hợp chặt chẽ ngay từ khâu thiết kế kiến trúc hệ thống.
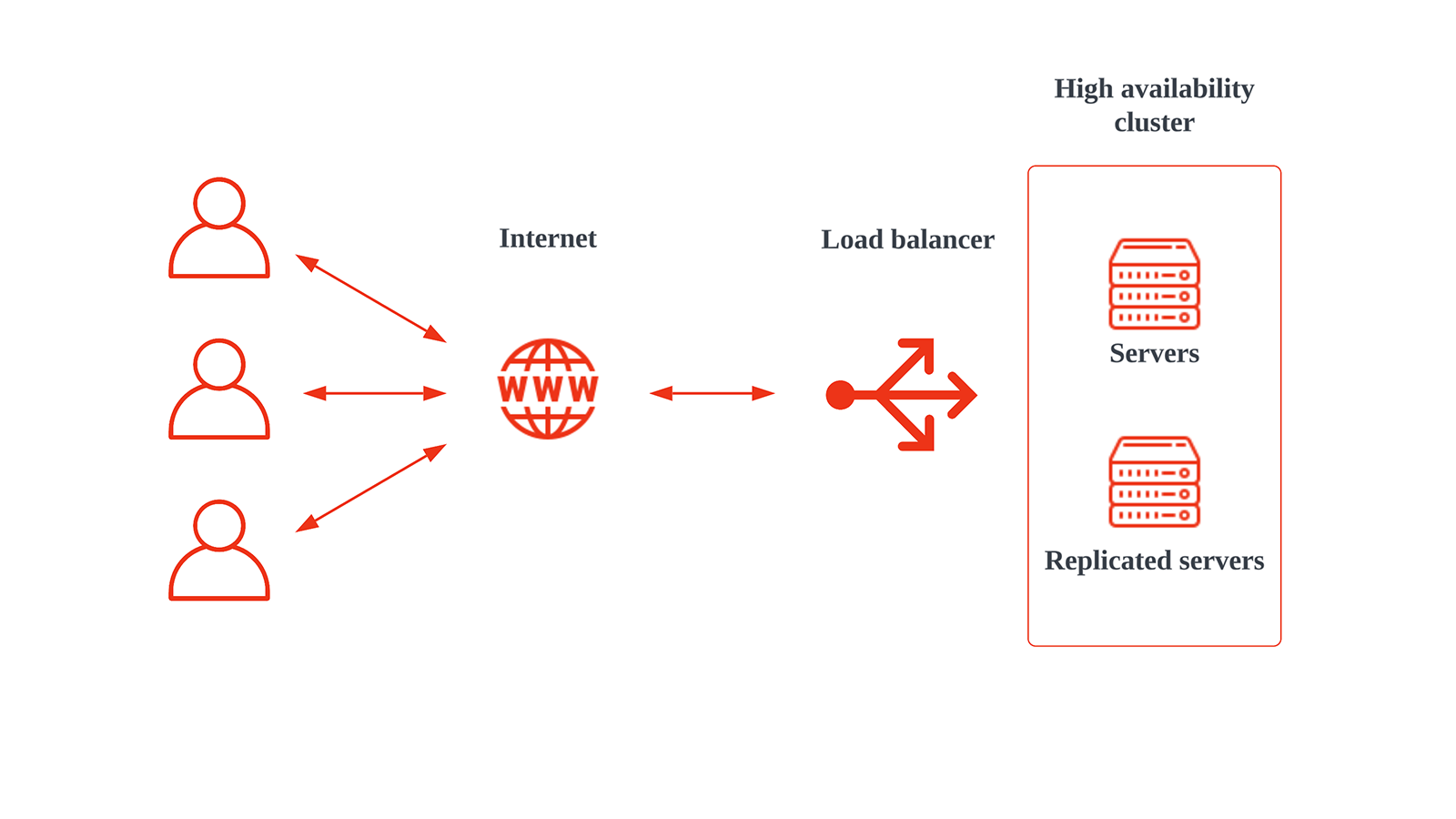
Ý nghĩa và tầm quan trọng của High Availability
Trong môi trường kinh doanh cạnh tranh ngày nay, việc đảm bảo hệ thống hoạt động liên tục không còn là một lựa chọn, mà là một yêu cầu bắt buộc. Thời gian chết có thể gây ra những hậu quả vô cùng tốn kém. Đối với một trang web thương mại điện tử, mỗi phút hệ thống ngừng hoạt động đồng nghĩa với việc mất đi doanh thu từ các đơn hàng không thể thực hiện. Thậm chí nghiêm trọng hơn, nó còn làm suy giảm lòng tin của khách hàng. Một người dùng truy cập vào website của bạn và thấy nó không hoạt động có thể sẽ không bao giờ quay trở lại.
Ảnh hưởng của downtime không chỉ dừng lại ở mặt tài chính trực tiếp. Nó còn tác động mạnh mẽ đến uy tín thương hiệu mà doanh nghiệp đã dày công xây dựng. Trong các ngành như tài chính, y tế hay viễn thông, sự gián đoạn hệ thống có thể dẫn đến những hậu quả nghiêm trọng, ảnh hưởng đến an toàn và sinh mạng. Do đó, đầu tư vào một kiến trúc High Availability không chỉ là một chi phí kỹ thuật, mà là một khoản đầu tư chiến lược để bảo vệ hoạt động kinh doanh, duy trì sự hài lòng của khách hàng và đảm bảo sự phát triển bền vững.
Các kỹ thuật và phương pháp xây dựng hệ thống High Availability
Để xây dựng một hệ thống có tính sẵn sàng cao, các kỹ sư phải áp dụng nhiều kỹ thuật và phương pháp khác nhau, kết hợp chúng để tạo ra một kiến trúc vững chắc và có khả năng phục hồi.
Kiến trúc dự phòng và sao lưu
Nền tảng của mọi hệ thống High Availability chính là sự dự phòng (redundancy). Nguyên tắc cơ bản là loại bỏ bất kỳ điểm lỗi đơn lẻ nào. Nếu một thành phần trong hệ thống gặp sự cố, phải có một thành phần khác sẵn sàng thay thế ngay lập tức. Điều này được thực hiện thông qua nhiều lớp. Ví dụ, một máy chủ có thể được trang bị hai nguồn điện (power supply redundancy) hoặc nhiều card mạng. Ở quy mô lớn hơn, chúng ta sử dụng các cụm máy chủ (server cluster), nơi nhiều máy chủ hoạt động cùng nhau. Nếu một máy chủ trong cụm bị lỗi, các máy chủ còn lại sẽ gánh vác khối lượng công việc của nó.

Sao lưu (backup) dữ liệu cũng là một yếu tố then chốt. Dữ liệu từ máy chủ chính sẽ được sao chép liên tục sang một hoặc nhiều máy chủ dự phòng. Khi có sự cố, hệ thống có thể chuyển sang sử dụng máy chủ dự phòng với dữ liệu gần như tức thời. Bên cạnh đó, cân bằng tải (load balancing) đóng vai trò như một người điều phối giao thông, phân bổ các yêu cầu của người dùng đến nhiều máy chủ khác nhau. Kỹ thuật này không chỉ giúp ngăn ngừa tình trạng quá tải trên một máy chủ duy nhất mà còn tự động loại bỏ các máy chủ bị lỗi ra khỏi nhóm, đảm bảo yêu cầu luôn được xử lý bởi các máy chủ khỏe mạnh.
Giám sát và tự động phục hồi (Monitoring & Failover)
Có một hệ thống dự phòng là chưa đủ; bạn cần một cơ chế để biết khi nào cần sử dụng nó. Đây chính là lúc hệ thống giám sát (monitoring) và tự động phục hồi (failover) phát huy tác dụng. Hệ thống giám sát liên tục kiểm tra “sức khỏe” của tất cả các thành phần, từ phần cứng như máy chủ, ổ cứng, đến phần mềm và ứng dụng. Các công cụ này sẽ theo dõi các chỉ số quan trọng như CPU, RAM, lưu lượng mạng và thời gian phản hồi của ứng dụng.
Khi hệ thống giám sát phát hiện một sự cố – chẳng hạn một máy chủ không phản hồi – nó sẽ ngay lập tức kích hoạt một cơ chế cảnh báo. Đồng thời, quy trình tự động chuyển đổi dự phòng (automatic failover) sẽ được thực thi. Ví dụ, trong một cụm máy chủ cơ sở dữ liệu, nếu máy chủ chính (primary) gặp lỗi, hệ thống sẽ tự động chuyển vai trò chính cho một máy chủ phụ (secondary) đã được đồng bộ hóa dữ liệu trước đó. Quá trình này diễn ra chỉ trong vài giây, giúp giảm thiểu thời gian gián đoạn xuống mức thấp nhất và thường không bị người dùng cuối phát hiện.
Cách đảm bảo hệ thống hoạt động liên tục và không gián đoạn
Xây dựng được một hệ thống High Availability đã khó, việc duy trì nó hoạt động ổn định và liên tục còn là một thách thức lớn hơn. Điều này đòi hỏi sự kết hợp giữa thiết lập ban đầu và quy trình vận hành, bảo trì thông minh.
Thiết lập hệ thống dự phòng và cân bằng tải
Bước đầu tiên để đảm bảo hoạt động liên tục là lựa chọn và thiết lập đúng phương án kỹ thuật phù hợp với quy mô và yêu cầu của hệ thống. Đối với một trang web nhỏ hoặc blog cá nhân, giải pháp có thể đơn giản là sử dụng dịch vụ hosting chất lượng cao như tại AZWEB, nơi đã tích hợp sẵn các cơ chế dự phòng ở tầng hạ tầng. Tuy nhiên, với các hệ thống lớn hơn như trang thương mại điện tử hoặc ứng dụng doanh nghiệp, bạn cần một kiến trúc phức tạp hơn.
Việc lựa chọn phương pháp cân bằng tải là rất quan trọng. Bạn có thể sử dụng cân bằng tải dựa trên DNS, hoặc các bộ cân bằng tải phần cứng/phần mềm chuyên dụng. Mỗi phương pháp có ưu và nhược điểm riêng về chi phí, hiệu suất và độ phức tạp. Tương tự, việc thiết lập một cụm máy chủ (cluster) cũng cần được cân nhắc kỹ lưỡng. Một cụm active-passive có một máy chủ chính hoạt động và một máy chủ dự phòng chờ sẵn, trong khi cụm active-active cho phép tất cả các máy chủ cùng lúc xử lý yêu cầu, giúp tận dụng tối đa tài nguyên. Lựa chọn đúng kiến trúc sẽ quyết định hiệu quả của toàn bộ hệ thống HA.

Bảo trì định kỳ và nâng cấp không gây gián đoạn
Một trong những nguyên nhân phổ biến gây ra downtime chính là quá trình bảo trì và nâng cấp hệ thống. Làm thế nào để cập nhật phần mềm, vá lỗi bảo mật hoặc nâng cấp phần cứng mà không phải tạm ngưng dịch vụ? Đây là lúc các chiến lược bảo trì không gây gián đoạn (zero-downtime maintenance) trở nên cần thiết.
Một chiến lược phổ biến là “blue-green deployment”. Với phương pháp này, bạn sẽ có hai môi trường sản xuất giống hệt nhau: “Blue” (môi trường đang chạy) và “Green” (môi trường mới). Khi cần nâng cấp, bạn sẽ triển khai phiên bản mới lên môi trường “Green”. Sau khi kiểm tra mọi thứ hoạt động hoàn hảo trên “Green”, bạn chỉ cần chuyển hướng người dùng từ “Blue” sang “Green”. Nếu có bất kỳ sự cố nào xảy ra, bạn có thể dễ dàng chuyển hướng trở lại môi trường “Blue” ngay lập tức. Các kỹ thuật khác như cập nhật cuốn chiếu (rolling updates) trong các cụm máy chủ cũng cho phép nâng cấp từng máy chủ một mà không làm ảnh hưởng đến hoạt động chung của hệ thống.
Ứng dụng của High Availability trong quản trị máy chủ và dịch vụ mạng
High Availability không phải là một khái niệm trừu tượng; nó được ứng dụng rộng rãi trong hầu hết các khía cạnh của công nghệ thông tin hiện đại, từ quản trị máy chủ đến các dịch vụ mạng thiết yếu.
High Availability trong quản trị server và lưu trữ dữ liệu
Đối với máy chủ và hệ thống lưu trữ, HA là yếu tố sống còn. Ở cấp độ phần cứng, các máy chủ dành cho doanh nghiệp thường được trang bị các thành phần dự phòng như nguồn điện kép, quạt tản nhiệt dự phòng và nhiều đường mạng. Về mặt lưu trữ, công nghệ RAID (Redundant Array of Independent Disks) được sử dụng để bảo vệ dữ liệu khỏi lỗi ổ cứng bằng cách phân tán hoặc sao chép dữ liệu trên nhiều đĩa.
Trong môi trường ảo hóa và điện toán đám mây (cloud computing), các nhà cung cấp dịch vụ như AZWEB với dịch vụ VPS chất lượng cao thường xây dựng hạ tầng của họ trên các cụm máy chủ lớn. Nếu một máy chủ vật lý gặp sự cố, các máy ảo (VM) chạy trên đó có thể được tự động di chuyển sang một máy chủ vật lý khác đang hoạt động mà không gây gián đoạn dịch vụ. Các hệ thống lưu trữ đám mây cũng sử dụng cơ chế sao chép dữ liệu ra nhiều vị trí địa lý khác nhau (geo-replication) để đảm bảo dữ liệu an toàn ngay cả khi một trung tâm dữ liệu gặp thảm họa.
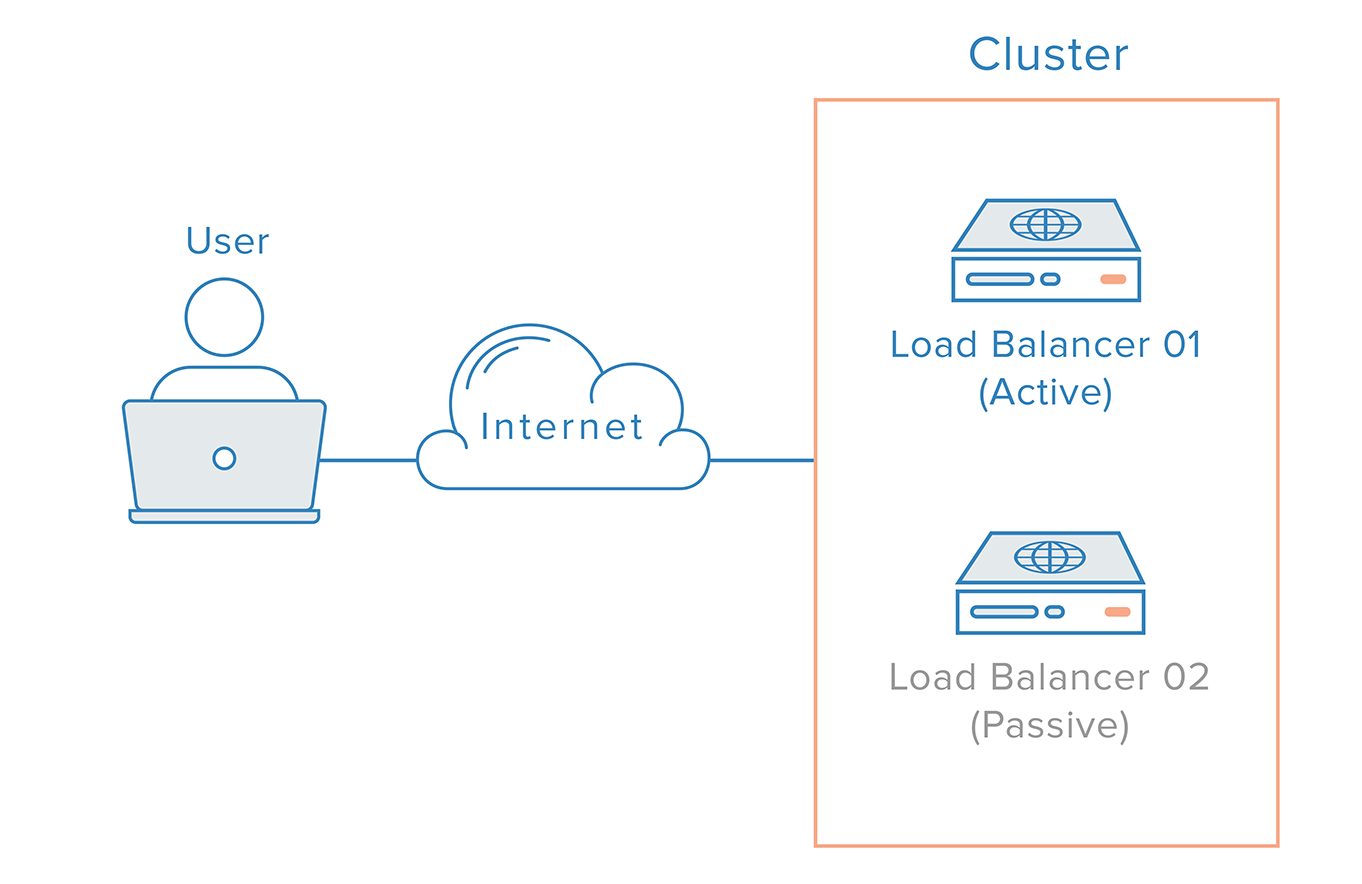
High Availability trong dịch vụ mạng và ứng dụng doanh nghiệp
Các dịch vụ mạng cốt lõi mà chúng ta sử dụng hàng ngày đều phụ thuộc rất nhiều vào High Availability. Hệ thống Email doanh nghiệp không thể ngừng hoạt động, vì nó là công cụ giao tiếp chính. Do đó, các máy chủ Email thường được thiết lập trong một cụm có khả năng chịu lỗi. Tương tự, các máy chủ Web cho các trang tin tức, thương mại điện tử hay ngân hàng trực tuyến bắt buộc phải có kiến trúc HA để phục vụ hàng triệu lượt truy cập mỗi ngày.
Hệ thống cơ sở dữ liệu (Database) là trái tim của hầu hết các ứng dụng. Mất kết nối đến cơ sở dữ liệu đồng nghĩa với việc toàn bộ ứng dụng sẽ ngừng hoạt động. Vì vậy, các kỹ thuật như database clustering, replication (sao chép master-slave hoặc master-master) được triển khai để đảm bảo dữ liệu luôn sẵn sàng và nhất quán. Các ứng dụng quản trị doanh nghiệp (ERP), quản lý quan hệ khách hàng (CRM) cũng được xây dựng trên nền tảng HA để đảm bảo quy trình kinh doanh không bị gián đoạn.
Các ví dụ thực tế về hệ thống High Availability
Để hiểu rõ hơn về cách High Availability hoạt động trong thực tế, chúng ta hãy cùng xem qua một vài ví dụ cụ thể từ doanh nghiệp đến các dịch vụ đám mây phổ biến.
Ví dụ hệ thống cluster và load balancing trong doanh nghiệp
Hãy tưởng tượng một công ty thương mại điện tử lớn chuẩn bị cho chương trình khuyến mãi Black Friday. Họ dự đoán lưu lượng truy cập sẽ tăng đột biến gấp 10 lần so với ngày thường. Để xử lý khối lượng công việc khổng lồ này và tránh sập web, họ đã triển khai một kiến trúc High Availability. Hệ thống của họ bao gồm một bộ cân bằng tải (load balancer) ở phía trước, có nhiệm vụ phân phối các yêu cầu truy cập đến một cụm gồm 5 máy chủ web (web server cluster). Tất cả 5 máy chủ này đều chạy cùng một phiên bản của trang web.

Nếu một trong các máy chủ web gặp sự cố hoặc bị quá tải, bộ cân bằng tải sẽ tự động phát hiện và ngừng gửi yêu cầu đến máy chủ đó, chuyển hướng sang 4 máy chủ còn lại. Phía sau, hệ thống cơ sở dữ liệu của họ cũng được thiết lập theo mô hình cụm master-slave. Mọi giao dịch ghi (như đặt hàng) sẽ được thực hiện trên máy chủ master và sao chép ngay lập tức sang máy chủ slave. Nếu máy chủ master gặp lỗi, hệ thống sẽ tự động chuyển máy chủ slave lên làm master mới. Nhờ kiến trúc này, công ty có thể tự tin phục vụ lượng khách hàng khổng lồ mà không lo bị gián đoạn.
Trường hợp sử dụng High Availability trong các dịch vụ Cloud phổ biến
Các nhà cung cấp điện toán đám mây hàng đầu thế giới như Amazon Web Services (AWS), Microsoft Azure và Google Cloud Platform (GCP) đã xây dựng toàn bộ đế chế của mình dựa trên việc cung cấp các dịch vụ có tính sẵn sàng cao. Họ thực hiện điều này bằng cách chia nhỏ hạ tầng của mình thành các Vùng (Regions) và Vùng sẵn sàng (Availability Zones – AZs). Một Region là một khu vực địa lý riêng biệt (ví dụ: Singapore), trong khi một AZ là một hoặc nhiều trung tâm dữ liệu độc lập trong một Region.
Khi bạn triển khai một ứng dụng trên cloud, bạn có thể chọn chạy nó trên nhiều AZ khác nhau. Ví dụ, bạn có thể đặt máy chủ web của mình ở AZ-1 và một bản sao y hệt ở AZ-2. Hai AZ này được kết nối với nhau bằng mạng tốc độ cao nhưng lại độc lập về nguồn điện, hệ thống làm mát và mạng lưới. Nếu có sự cố xảy ra tại AZ-1 (ví dụ: mất điện), các yêu cầu sẽ được tự động chuyển hướng đến máy chủ của bạn đang chạy ở AZ-2. Đây chính là cách các dịch vụ như Netflix, Spotify hay Airbnb duy trì hoạt động gần như 100% thời gian, ngay cả khi có lỗi xảy ra ở một phần hạ tầng của họ.

Common Issues/Troubleshooting
Mặc dù High Availability được thiết kế để ngăn ngừa downtime, nhưng không có hệ thống nào là hoàn hảo. Việc triển khai HA phức tạp và đôi khi vẫn có thể xảy ra sự cố. Hiểu rõ các vấn đề phổ biến sẽ giúp bạn khắc phục chúng hiệu quả hơn.
Nguyên nhân phổ biến dẫn đến downtime dù đã triển khai HA
Một trong những lý do hàng đầu gây ra sự cố chính là cấu hình sai (misconfiguration). Một bộ cân bằng tải được cấu hình không chính xác có thể gửi lưu lượng đến một máy chủ đã chết, hoặc cơ chế phát hiện lỗi (health check) quá nhạy hoặc quá chậm. Một vấn đề phức tạp khác là “split-brain” trong các hệ thống cluster. Điều này xảy ra khi kết nối giữa các node trong cụm bị mất, khiến mỗi node đều nghĩ rằng node kia đã chết và tự mình nhận quyền làm node chính. Hậu quả là cả hai cùng cố gắng ghi vào dữ liệu, dẫn đến tình trạng không nhất quán và hỏng dữ liệu.
Ngoài ra, lỗi phần mềm trong chính các thành phần của hệ thống HA cũng có thể gây ra downtime. Đôi khi, sự cố không nằm ở máy chủ mà ở các thành phần mạng như switch, router hoặc tường lửa. Nếu không có sự dự phòng cho các thiết bị này, toàn bộ hệ thống vẫn có thể bị tê liệt. Cuối cùng, sự can thiệp của con người cũng là một nguyên nhân phổ biến, từ việc thực hiện một lệnh sai cho đến việc triển khai một bản cập nhật chưa được kiểm tra kỹ lưỡng.
Cách xử lý sự cố tự động failover không hoạt động hiệu quả
Khi cơ chế tự động chuyển đổi dự phòng (failover) không hoạt động như mong đợi, tình hình có thể trở nên rất căng thẳng. Bước đầu tiên để xử lý là phải có một hệ thống giám sát và cảnh báo chi tiết. Bạn cần biết ngay lập tức khi failover thất bại và lý do tại sao. Các file log (nhật ký hệ thống) là người bạn tốt nhất của bạn trong trường-hợp này. Hãy kiểm tra log của bộ cân bằng tải, của các node trong cluster và của ứng dụng để tìm manh mối.
Một nguyên nhân phổ biến là do hệ thống dự phòng không thực sự “sẵn sàng”. Dữ liệu có thể chưa được đồng bộ hóa hoàn toàn, hoặc phiên bản phần mềm trên máy chủ dự phòng không khớp với máy chủ chính. Đó là lý do tại sao việc kiểm tra định kỳ quy trình failover là cực kỳ quan trọng. Hãy tạo ra một môi trường thử nghiệm và cố tình gây ra lỗi để xem hệ thống có tự động chuyển đổi đúng cách hay không. Việc “diễn tập” này giúp bạn phát hiện và khắc phục các vấn đề tiềm ẩn trước khi chúng xảy ra trong môi trường sản xuất thực tế.
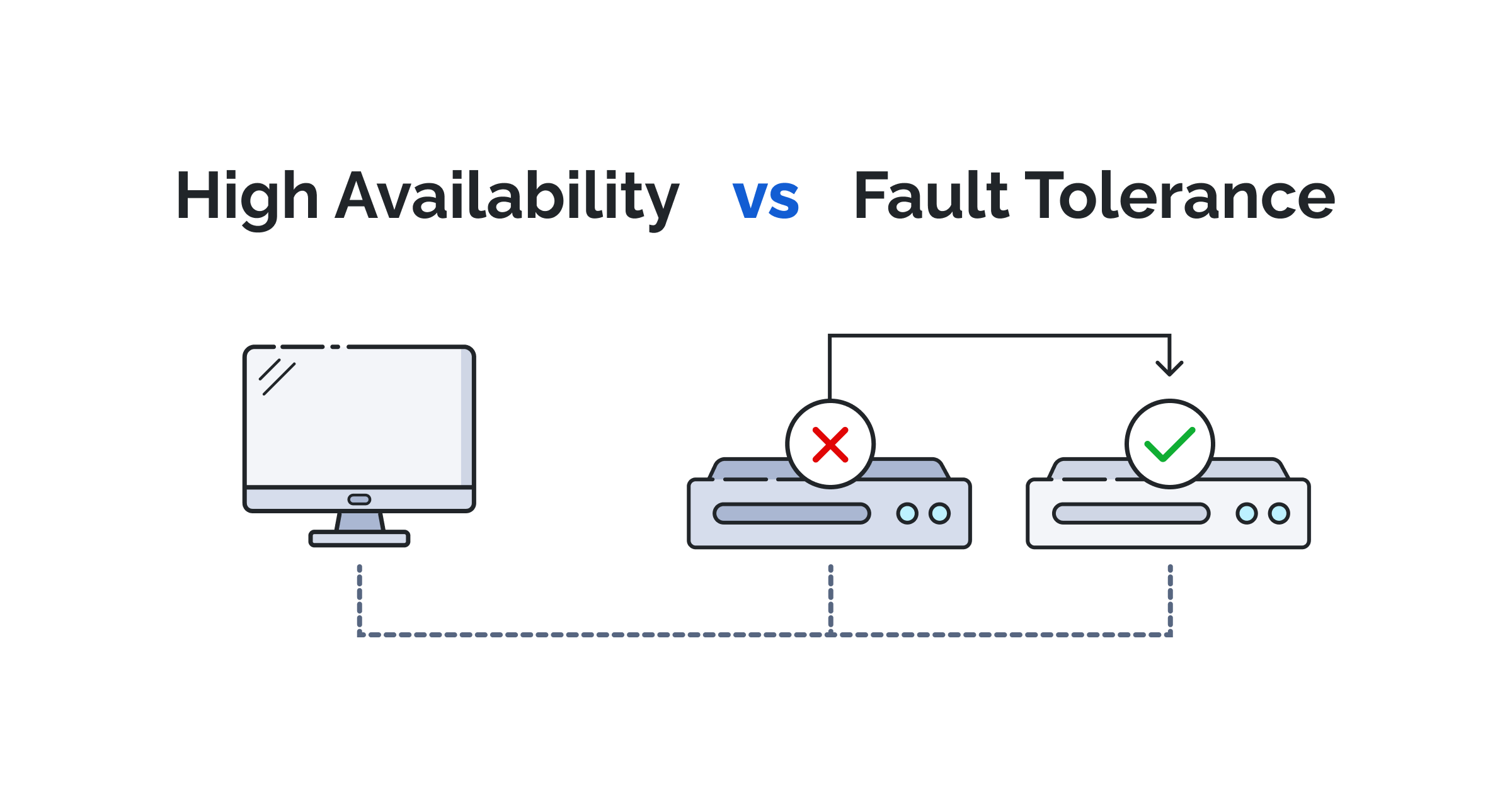
Best Practices
Để triển khai và duy trì một hệ thống High Availability hiệu quả, việc tuân thủ các nguyên tắc và thực tiễn tốt nhất là vô cùng cần thiết. Dưới đây là những khuyến nghị quan trọng từ các chuyên gia.
- Luôn có kế hoạch sao lưu đầy đủ và kiểm tra định kỳ: Dự phòng không thể thay thế cho sao lưu. High Availability bảo vệ bạn khỏi downtime, còn sao lưu bảo vệ bạn khỏi mất mát dữ liệu. Hãy đảm bảo bạn có một chiến lược sao lưu toàn diện và quan trọng hơn là phải thường xuyên kiểm tra tính toàn vẹn của các bản sao lưu đó bằng cách khôi phục thử chúng.
- Triển khai hệ thống giám sát toàn diện và cảnh báo sớm: Bạn không thể sửa những gì bạn không biết. Hãy thiết lập một hệ thống giám sát chi tiết cho mọi thành phần, từ phần cứng, mạng, hệ điều hành đến ứng dụng. Cảnh báo phải được cấu hình để thông báo cho đội ngũ quản trị ngay khi có dấu hiệu bất thường, chứ không phải đợi đến khi hệ thống đã sập.
- Không lạm dụng quá nhiều tầng dự phòng làm phức tạp hệ thống: Mặc dù dự phòng là cốt lõi của HA, nhưng việc thêm quá nhiều lớp dự phòng có thể làm cho hệ thống trở nên cực kỳ phức tạp, khó quản lý và gỡ rối. Hãy tìm sự cân bằng hợp lý giữa độ tin cậy và sự đơn giản. Một thiết kế đơn giản nhưng vững chắc thường tốt hơn một thiết kế phức tạp và dễ bị lỗi cấu hình.
- Thường xuyên cập nhật kiến thức và nâng cấp thiết bị, phần mềm: Công nghệ thay đổi liên tục. Các bản vá lỗi bảo mật, các phiên bản phần mềm mới và các công nghệ phần cứng hiệu quả hơn ra đời mỗi ngày. Việc thường xuyên cập nhật kiến thức cho đội ngũ và lên kế hoạch nâng cấp hệ thống sẽ giúp bạn đi trước một bước so với các mối đe dọa và duy trì hiệu suất tối ưu.
Conclusion
Qua bài viết, chúng ta đã cùng nhau khám phá một cách toàn diện về High Availability – từ định nghĩa cơ bản, tầm quan trọng không thể phủ nhận, đến các kỹ thuật xây dựng và ứng dụng thực tiễn. High Availability không chỉ là một thuật ngữ kỹ thuật, mà là một triết lý thiết kế hệ thống nhằm đảm bảo sự ổn định và liên tục cho hoạt động kinh doanh trong kỷ nguyên số. Việc loại bỏ các điểm lỗi đơn, sử dụng cơ chế dự phòng, giám sát và tự động phục hồi là những trụ cột giúp doanh nghiệp chống lại những thiệt hại do downtime gây ra.
Đầu tư vào một kiến trúc High Availability là một quyết định chiến lược, giúp bảo vệ doanh thu, giữ vững niềm tin của khách hàng và tạo lợi thế cạnh tranh bền vững. Bước tiếp theo cho bạn là đánh giá lại nhu cầu của hệ thống hiện tại, xác định các điểm yếu tiềm ẩn và bắt đầu lựa chọn giải pháp phù hợp. Dù bạn đang vận hành một website WordPress đơn giản hay một hệ thống doanh nghiệp phức tạp, các nguyên tắc của High Availability đều có thể được áp dụng. Hãy bắt đầu với việc lựa chọn các dịch vụ nền tảng chất lượng cao như Hosting và VPS tại AZWEB, và từng bước triển khai các giải pháp dự phòng để tối ưu hóa sự ổn định cho hệ thống của mình.